How we enabled the “Go Fast” button on TopN queries: Hint: we used vectorized virtual columns (which is new in Apache Druid 0.20.0)
May 18, 2021
Suneet Saldanha
Do you want your queries to run 25x faster? Of course you do! Keep reading to learn how.
Apache Druid is a fast, modern analytics database designed for workflows where fast, ad-hoc analytics, instant data visibility, or supporting high concurrency is important. Multiple factors contribute to Druid’s impressive querying speed. Recently, I explained how Apache Druid takes advantage of per-segment result caches as one part of a strategy to deal with high-concurrency workload. Now, let’s talk about raw speed!
To illustrate what we found, let’s use a fictitious example that is similar to a real-world problem. Let’s imagine a platform that manages a two-sided marketplace. Sellers and buyers come to the marketplace and trade goods. Based on platform demand, a surge price is factored into the total sales price. So, the total amount a seller makes on this platform is calculated as base_price * surge at the time of the purchase.
__time
seller_id
country
base_price
surge
April 5 2021 11:20:36
123987
CAN
12.00
1.8
April 5 2021 11:22:05
124358
USA
58.23
1
April 6 2021 11:30:28
123987
CAN
20.00
1.34
The above table illustrates what the data model might look like. Each row represents a transaction that takes place on the platform. We record the seller, the base_price, and the surge rate at the time of the purchase.
As the business behind the two-sided marketplace, we want to know, in real time, the top 100 sellers, excluding surge pricing, in each country [query1]. We also want to be able to see the top countries by total sales made [query 2]. To achieve this, you might write the following queries:
-- [query1] TOP sellers and countries by base sales
SELECT seller_id, country, sum(base_price) as total_price FROM purchases ORDER BY total_price desc LIMIT 100
-- [query2] TOP 20 countries by total sales
SELECT country, sum(base_price * surge) as total_price FROM purchases ORDER BY total_price desc LIMIT 20
Druid converts these two queries, respectively, into a GroupBy query for the top sellers and countries and a TopN query for the top countries by sales.
Conceptually, think of a TopN query as an approximate GroupBy query over a single dimension with an ordering spec and a limit. Because of these restrictions, in general, this query should be faster than a GroupBy query over the same data.
Query1 might intuitively appear more computationally intensive than query2 since Query1 is operating on multiple columns. However, we noticed that query1 finished in about 1 second while query2 took almost 17 seconds. To start looking into this discrepancy, we started by running an EXPLAIN PLAN for the two queries.
EXPLAIN PLAN FOR SELECT country, sum(base_price * surge) as total_price FROM purchases ORDER BY total_price DESC LIMIT 20
Running this command showed us that Druid executes a GroupBy query for query1 and a TopN query for query2. This was our first clue! By reading the Apache Druid docs, we found out that GroupBy queries are vectorized when TopN queries have not yet been.
Therefore, we decided to rewrite query2 to a GroupBy query by removing the limit from the SQL query being sent to Druid and applying the limit in the application code instead. We knew this would be okay, since, according to Wikipedia, there are only 195 countries. That means the overhead of running a GroupBy query on every value in the country column is not substantial.
We were confident that this would get us sub-second response time on query2. Unfortunately, the query time was still around 17 seconds. The results of the `EXPLAIN PLAN` command showed that this query was now being planned into a GroupBy query. In other words, the only difference between the two queries was that query1 was just adding a single column, whereas query2 was adding the product of two columns. This yielded our next experiment! What if we only needed to sum the base_price? BAM! That query only took 0.6 seconds.
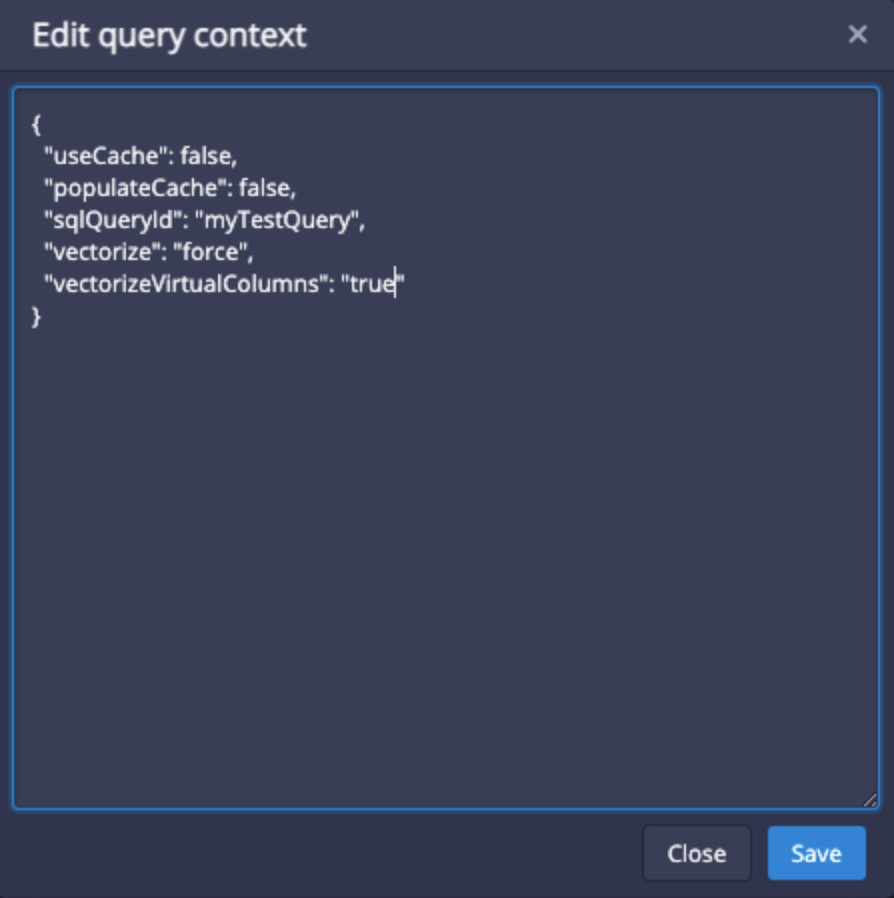
In the Apache Druid 0.20 release notes, there is a section that calls out vectorization support for expression virtual columns. Now, we had proof that when this query runs with the vectorized query engine, it can run in less than one second. So, we decided to enable this feature by adding `“vectorizeVirtualColumns”: “true”` to the query context and running the original query2 again except without a LIMIT. The query took 0.63 seconds to run, down from about 17 seconds before — that’s a 25x improvement!
Key takeaways:
Vectorized GroupBy and timeseries are the default starting in Apache Druid 0.19.0. If you’re on an older version, consider enabling this feature by setting vectorize: true in the queryContext. Or better yet, upgrade to the latest and greatest!
If you have queries that use expressions described in here, starting in Apache Druid 0.20.0, you should try the query context vectorizeVirtualColumns to see if your queries can take advantage of these improvements.
BONUS TIP: use vectorize: force in the queryContext to validate that your queries are in fact running with the vectorized query engine.
If you are running a TopN query on a column with a low cardinality, consider rewriting your query to a GroupBy query to take advantage of the vectorized query engine. You can do this by disabling the limit—this is ok if you know the column has a low cardinality—or by grouping on more than 1 column.
Use EXPLAIN PLAN FOR to see what Druid is actually doing to run the SQL query that is being used.
If you’re using the Apache Druid web console in your testing, check the setting of the `Auto limit` toggle. Adding a limit to a query can change the underlying query that Druid runs.
Does this type of performance hunting sound interesting to you? Do you want to help build the fastest analytics database out there, using techniques like vectorized processing that helped us realize this speedup? My team is looking for engineers to join us on this mission!
Alternatively, if you have ideas, or patches you’d like to share with us, send them our way on Github or toss ideas around with others in the Apache Druid community.
The fine print: While the scenario described in this post is fictional, the query performance numbers are based on a real datasource with almost 10 billion rows running on a test cluster with 64 data processing cores.
Note that this technique is not a silver bullet: A vectorized GroupBy query is not always faster than a non-vectorized TopN. Be especially careful of running a GroupBy query without a limit for high cardinality columns.
Other blogs you might find interesting
No records found...
Jun 04, 2026
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...
A First Look at Lumi Loglake: Query Logs Where They Live
TL;DR: Imply Lumi Loglake is a lakehouse (separated compute/storage) architecture for unstructured logs that reduces costs from 40% up to orders of magnitude on your hardware/AWS/Azure bill used to run your...
Imply Lumi Major Release Preview: Continuing the Journey Towards Decoupled Observability/SIEM
We are getting ready to introduce the next major expansion of Imply Lumi and the observability warehouse. When we introduced the industry’s first observability warehouse, the goal was clear: decouple the...