Apache Druid uses load rules to manage aging of segments from one historical tier to another and finally to purge old segments from the cluster.
In this article we’ll show what happens when you make a mistake on the load rules which results in premature removal of segments from the cluster. We’ll also show how to correct the mistake and recover the segments before they are permanently deleted.
Misconception About loadByPeriod Rules
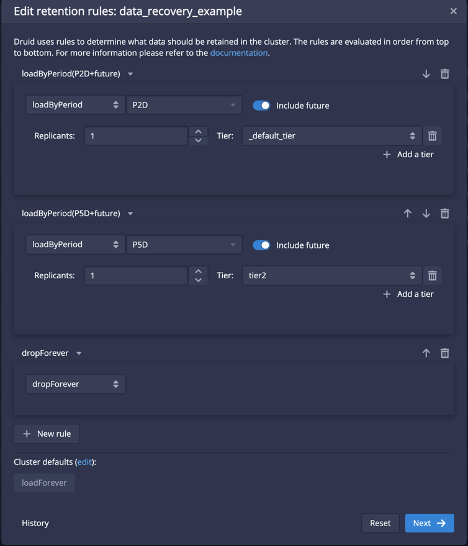
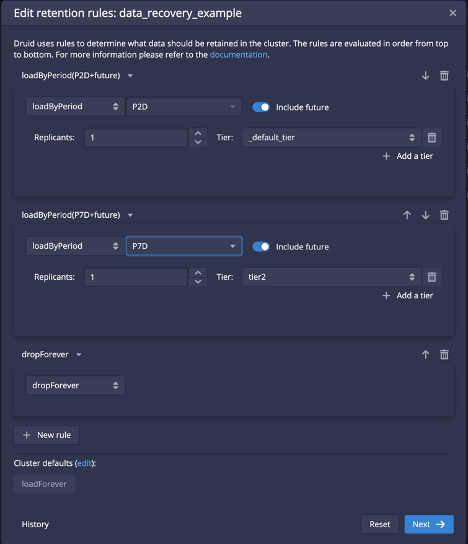
A common misconception in the setting Druid retention rules is that the periods expressed in the rules are consecutive. Assuming we want to retain the most recent 2 days in the _default_tier (the hot one), and retain an additional 5 days of data on tier2 (the cold one), an example of retention rules with this misconception would look like this:
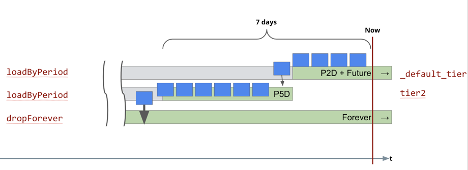
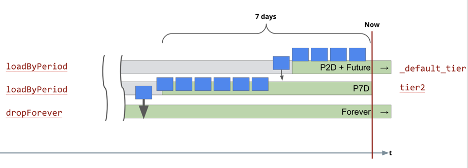
The misconception is that the second rule will start the 5 day interval at the end of the first rule’s 2 day interval totaling 7 days of retention, as shown below:
Let’s take a look at the data after initial ingestion with that set of rules.
If the data set that we are loading contains the following timestamps:
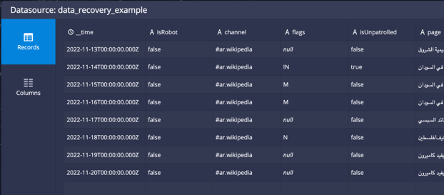
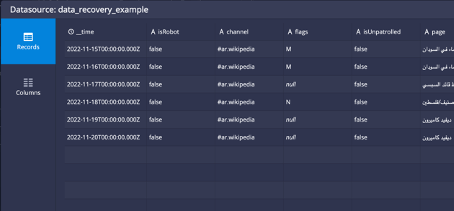
In reality you will see that you only get 5 days of data kept on the cluster. This is because the periods in the load rules don’t accumulate consecutively, instead they overlap, so the real behavior will be:
Notice that segments that are older than 5 days will be dropped and the data will actually look like the table below, where it is missing a couple of days at the beginning and the oldest timestamps are gone:
Let’s see what happened under the hood:
The first rule of P2D loads recent segments into the _default_tier.
When the segments are over 2 days old, the second load rule applies, so segments are loaded into tier2.
The second rule uses a period of P5D, so segments that are between 2 and 5 days old will be added in tier2.
When a segment reaches 5 days in age, the first and second rules don’t match, so the third rule is used.
All segments that reach this point will match the dropForever rule, so they will be marked as unused.
Fixing the Rules
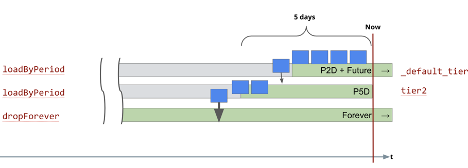
In order to fix this, you adjust the rules with the knowledge that the periods overlap and extend the second rule to the full 7 days:
This renders the correct timeframe for the second rule as follows:
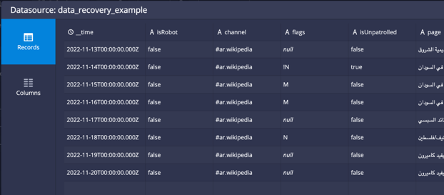
But now when you look at the data on the datasource, the rows older than 5 days are still not available because those segments were marked as Unused when the incorrect rules were active:
But no worries, let’s review what’s happening on the cluster and recover that data.
Recovering Unloaded Segments
When the incorrect rules were active, the coordinator did its job correctly and the segments that were older than 5 days, were marked as unused. This means that the metadata for the segments was updated to reflect that they are no longer in use. But the metadata is still there and the segments still exist in deep storage, so they are still recoverable until they are removed by a coordinator kill task.
The druid coordinator kill task is disabled by default. This means that unless segments are manually deleted, the segment will always be available in deep storage and the segment metadata will always be available in the metadata store. The druid coordinator kill task can be enabled by adding `druid.coordinator.kill.on=true` in the coordinator config.The coordinator kill task runs once a day (druid.coordinator.kill.period=P1D) by default when it is turned on. The default retention period for segments (druid.coordinator.kill.durationToRetain=90) means that even if the kill task runs it will not remove segments until they are 90 days old. Since the defaults are active, this means that we can still recover the segments marked as Unused.
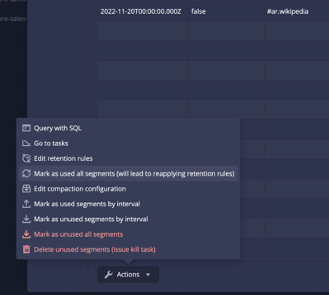
In order to recover the segments, you need to use the “Mark as Used all segments” function from the Actions menu for the datasource which will trigger the coordinator to apply the new load rules on all segments once more:
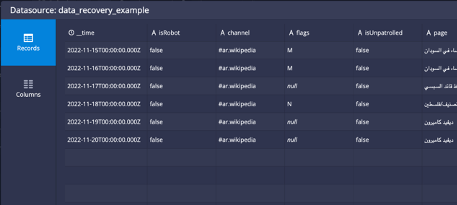
After doing this, the coordinator will again request those segments to be loaded to tier2 and will not be removed again until they age out of the 7 day period. After the next coordinator run which occurs every minute by default a new query of the data shows that the oldest 2 days are back:
Conclusion
Understanding the load/drop rules in Druid takes a little getting used to. Fortunately, the effects of incorrect rules can be fixed like I’ve shown here as long as the coordinator kill task has not actually removed the segment data and metadata.
If you want to learn more about load rules and how the coordinator interprets them, check out this video from the last Druid Summit.
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...