Overview
In today’s data-rich world, making decisions based on data is a top priority for just about everyone — from executives and product owners to data teams and practitioners. When most people think of analytics, it’s with this use case in mind: gathering data from real-time and historical sources to produce a synthesized picture (a chart, graph, or dashboard) that a person can analyze and use to drive action.
But humans aren’t the only ones relying on data to make decisions. Many applications rely on machines to make decisions or predict outcomes automatically. Whether behind the curtain of a UI or not, computers are capable of executing or recommending action themselves based on data flowing through algorithms that read, analyze, and act on information faster than a human can.
This is real-time decisioning, or when using machine learning, real-time inference. A real-time decisioning engine acts as a central brain within an application, sifting through possible actions and ultimately determining which one is most likely to produce the best result.
For example, consider the following scenarios:
- Route optimization: When you need directions from one location to another, Google Maps’ algorithm uses a combination of data to recommend the fastest route, including real-time traffic volume, historical traffic patterns, distance, and road network information. It also considers the mode of transportation (driving, biking, walking) and optimizes routing accordingly.
- Ad serving: In programmatic advertising, ad servers make subsecond decisions about what ads to show on a website, and then serve them. This is done by analyzing ad spend and user behavior information to select and populate ads on a web page in milliseconds.
- Real-time personalization: Every time you log in, Netflix’s AI model considers your past viewing habits to recommend new movies or TV shows based on the type of content you seem to prefer. It does this by combining historical info (what you’ve watched) with real-time data (what you’re viewing now) to make predictions as soon as data is available. This is in contrast to batch inference, where an AI model processes a batch of data at once and outputs predictions or decisions once processing is complete.
In each of these examples, there is no dashboard or report to interpret; there is data intake, analysis, and a result, with no human intervention.
Real-time decisioning is used in a wide variety of applications, such as autonomous vehicles, security systems, customer service, and recommendation systems, where decisions need to be made quickly based on incoming data. In order to make these real-time decisions, a model needs to be optimized for fast processing and low latency.
So, what should you consider when building real-time decisioning into your application? Let’s explore some of the technical challenges of developing these systems.
Challenges
Scalability: As complexity goes up, performance goes down
Models for real-time decisioning require a lot of data. The quantity of data plays a significant role in the success of the model, as limited data can prevent the model from learning enough to make accurate predictions.
But training data can’t be just any data — data feasibility and predictability risks are also a factor. Poor quality data can result in inaccurate models that produce error-ridden outputs. And once you have high-quality, relevant data sets, the question becomes ‘can I get the data into the model fast enough?’.
The answer is almost never straightforward. As the amount of data and the complexity of models increase, it becomes more challenging to train machine learning models in a timely and cost-effective manner. Ideally, the real-time decisioning platform should be able to handle simple and complex business rules for both streaming and historical data and scale to larger data volumes while maintaining cost efficiency.
Streaming: The shift from data at rest to data in motion
We no longer live in a batch-dominant world of business and data. Today, event streaming is the standard way to deliver real-time data to applications. Technologies like Apache Kafka and Amazon Kinesis have overcome the scale limitations of traditional messaging queues, enabling trillions of messages to flow freely between applications and data systems, and within and between organizations.
But capturing real-time data is only half of the picture — analyzing real-time data presents a different challenge because many analytic databases are purpose-built to ingest batch data, not streams. Without an end-to-end built for streaming data, your blazing-fast streaming pipeline loses its real-time edge.
So, what makes an analytics database streaming native? Scale, latency, and data quality are all important factors. Can the database handle full-scale event streaming? Can it ingest and correlate multiple Kafka topics or Kinesis shards? Can it guarantee data consistency? Can it avoid data loss or duplicates in the event of a disruption?
Lack of data consistency between systems, for example, can lead to a breakdown in other components of the pipeline, causing data duplication or data loss. Without reliable stream delivery, such as Kafka and exactly-once semantics, you risk both missing data and getting duplicated data, which can result in models that don’t reflect reality.
Availability: Real-time decisioning requires highly reliable and fault-tolerant architectures
When building a backend for batch data analysis, planned (or even unplanned) downtime is generally tolerated. A few minutes of downtime during the day or an overnight maintenance window aren’t considered major disruptions. Most OLAP databases and data warehouses were built with this in mind — that’s why downtime is generally acceptable for analytics systems.
By contrast, a real-time decisioning application is ‘always-on’ — often supporting mission-critical operations or responding to the activity of human end users. In these scenarios, downtime can directly impact revenue and take up valuable engineering time. For this reason, resiliency — which means both high availability and data durability — is an important characteristic of a database powering real-time decisioning engines.
Building resiliency into your analytics framework requires examining the design criteria. Can you protect yourself from a node or a cluster-wide failure? Can you afford data loss? What processes are in place to protect your application and your data?
Server failures are inevitable. A typical way to ensure resiliency is to replicate nodes and remember to make backups. But if you’re building operational workflows or always-on applications, the sensitivity to data loss is much higher. Even the ‘occasional’ data loss as you restore from a backup is simply not going to cut it.
Solutions
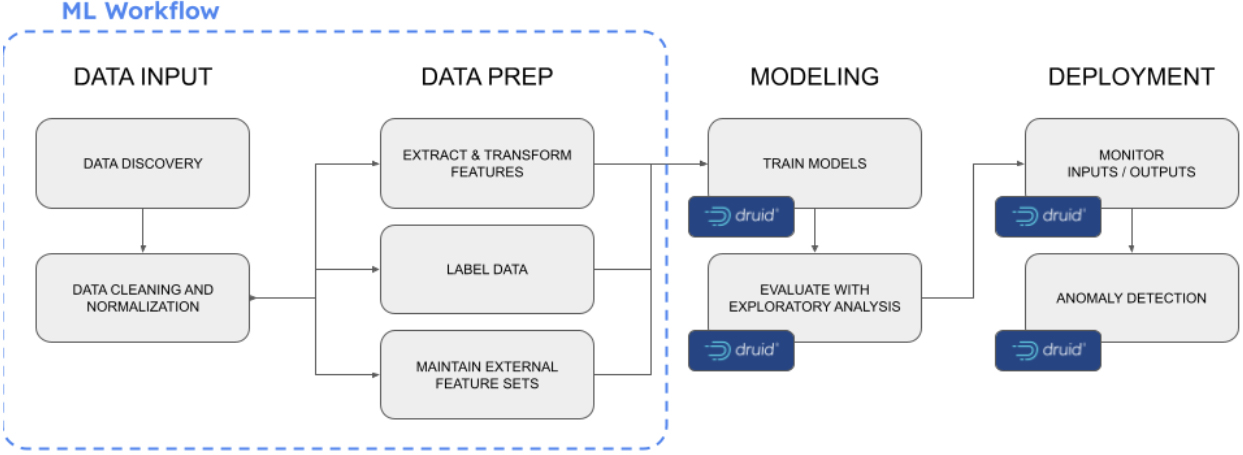
Powering a real-time decisioning system requires real-time, low-latency access to the data needed for generating outputs, whether they be actions, predictions, or recommendations. When selecting a backend for this type of application, you need a database that can handle large amounts of data, support high concurrency, and enable subsecond processing at scale.
Apache Druid is the real-time analytics database built specifically for these types of applications. It enables subsecond performance at scale, provides high concurrency at the best value, and easily combines real-time streaming data and historical batch data to support any model, from rules engines to regressions to machine learning. How does it do this?
- First, Druid processes the ingested data in real time, allowing the real-time decisioning engine to access the most up-to-date data when generating outputs. Druid connects natively to Apache Kafka and Amazon Kinesis with indexing processes that use Kafka’s own partition and offset mechanisms and Kinesis’ own shard and sequence mechanism. Druid’s unique architecture takes streaming topics and turns them into tables that are partitioned over multiple servers (thousands of them, if needed). This architecture enables faster performance than a decoupled query engine like a cloud data warehouse because there’s no data to move at query time and more scalability than an OLTP database like PostgreSQL or MySQL.
- Second, Druid has a highly optimized storage format. It employs automatic, multi-level indexing built into the data format to drive rapid query performance with less compute and storage infrastructure. This goes beyond the typical columnar format of an analytics database with the addition of a global index, data dictionary, and bitmap index. This maximizes CPU cycles for faster data crunching but also enables the database to retrieve relevant data for generating outputs. Druid’s indexing allows for fast and efficient aggregations, even on datasets with trillions of rows.
- Third, Druid is designed to withstand server outages without losing data (even recent events). Druid implements HA and durability based on automatic, multi-level replication with shared data in durable object storage. It enables the HA properties you expect as well as continuous backup to automatically protect and restore the latest state of the database even if you lose your entire cluster.
We recognize the time and effort that goes into developing real-time decisioning applications. Fortunately, you’ve got the entire Druid community by your side. As of 2023, over 1,400 organizations use Druid to generate insights that make data useful, in a wide variety of industries and for a broad range of uses. There are over 10,000 developers active in the Druid global community. Find them on Slack, GitHub, and Twitter.
Example
Reddit built an automated ad serving pipeline that analyzes campaign budgets and real-time plus historical user activity data to decide which ad to place, all within 30 milliseconds. To do this, the Reddit team needed user activity and budget information to be streamed with Kafka and analyzed in real time, with results fed back to ad serving infrastructure.
Advertisers create advertisement campaigns and set both daily and lifetime budgets for a campaign. The ads backend systems provide the best experience for Reddit’s advertisers by ensuring that a campaign’s entire budget is spent through — not a penny over or under. Reddit faced several technical challenges when architecting the data backend for this system, including:
- Maintaining low query latency while storing over 4 years of lifetime spend data
- Achieving eventual 100% accuracy, even in the case of Kafka or Flink outages
- Performing aggregations at ingestion time without slowing performance
Before choosing Druid as their real-time analytics database, Reddit experimented with batch-only and streaming-to-batch solutions, which resulted in either over-delivery (spending an advertiser’s budget too fast) or under-delivery (spending too slow). Efficient delivery — in other words, spending the right amount at the right time — requires a minimum delay in providing budget spend data to the ad serving infrastructure.
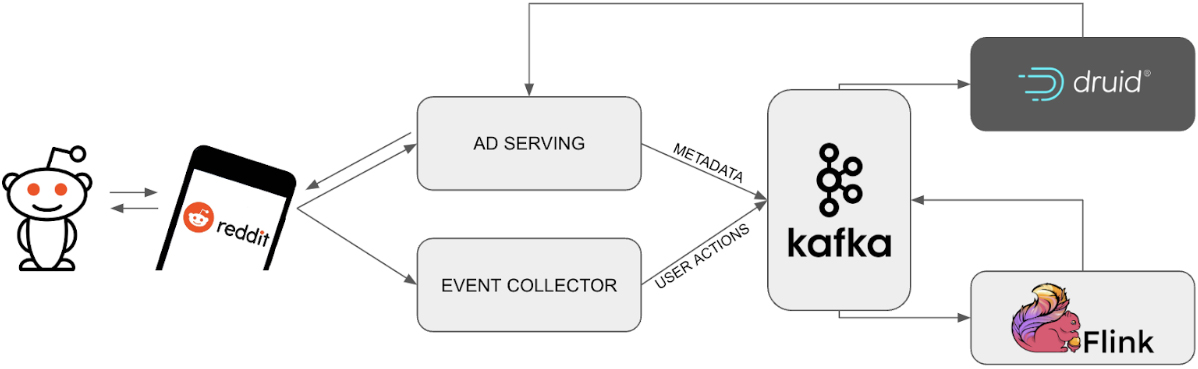
Reddit reduced this delay from 2 hours down to 15 minutes using Druid to process data from Apache Flink delivered by Kafka. This led to significant decreases in over-delivery and advertising effectiveness compared to their previous batch system, while providing reliable services with no downtime, just as the Reddit community has come to expect from the always-on website.