Apache Druid 24.0 contains over 324 updates from over 63 contributors.
This release marks a significant leap forward for the Druid engine. In this release, we’ve introduced two groundbreaking features – A multi-stage query (MSQ) engine and support for nested JSON columns.
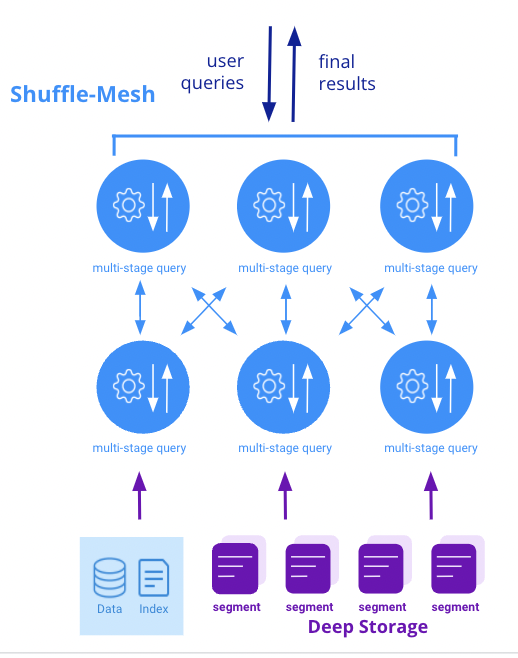
The multi-stage query engine marks the first step toward a universal query engine that’s both low latency and highly versatile. In this release, the Multi-Stage Query Engine enables you to transform and ingest batch data in Druid using SQL, simplifying the data prep process and tooling needed before ingestion. It is also highly performant; based on our benchmarking, it’s at least 40% faster than the native Druid batch ingestion engine.
Nested Column support enables you to ingest nested JSON columns and retain the nested structure while providing the fast performance you expect from Druid during querying. Visit the Apache Druid download page to download the software and read the full release notes detailing every change. The features in this Druid release are also available with Imply’s commercial distributions of Apache Druid.
Multi-Stage Query Engine and SQL Based ingestion
Before this release, in order to load data into Druid, you’d need to learn to use the Druid ingestion spec. Some users find this confusing as they are much more familiar with SQL. With Druid 24.0, you can now use SQL queries to load data into Druid. This is made possible through the introduction of the multi-stage query engine (MSQE).
MSQE offers much more than syntax sugar over classic ingestion. You can now use SQL to perform transformations that are not possible in classic ingestion. Unlike current Druid queries, MSQE queries run as tasks. This means queries can run for much longer. MSQE queries also support data shuffle operations, which are essential for large-scale ingestion.
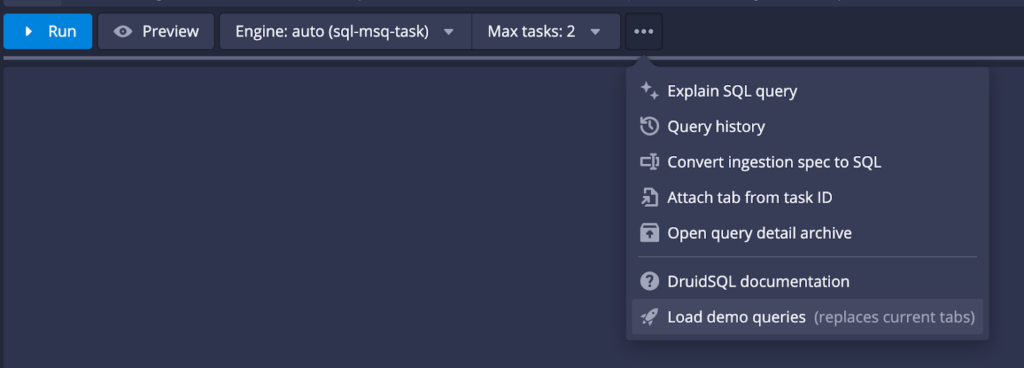
This version of Druid comes loaded with demo queries to illustrate the capabilities of the new query engine. To access the demo queries, simply open Druid’s query editor and select “Demo queries” from the dropdown menu below:
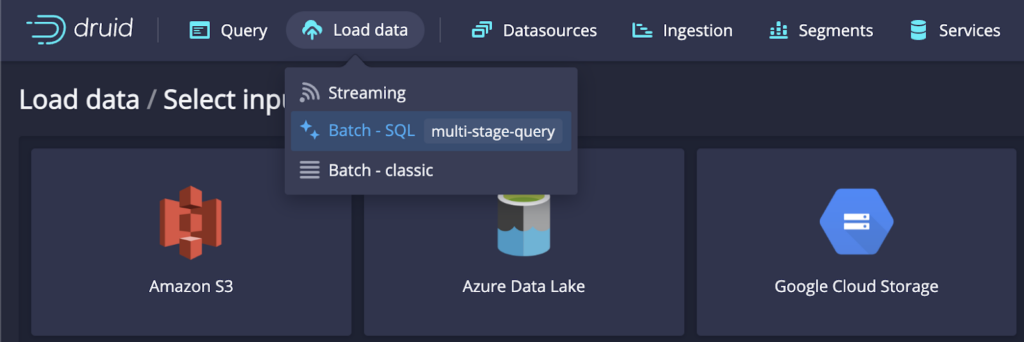
To help ease the transition into the new engine, it is now easier to connect with external data sources and generate the corresponding SQL query for data ingestion. The web console helps you parse the incoming data’s schema and generate the corresponding SQL query.
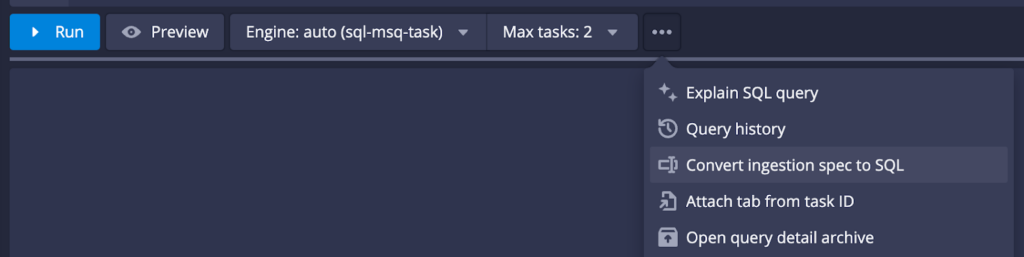
If you have an existing Druid ingestion spec, you can also use the built-in tools to convert it into a SQL-based ingestion query.
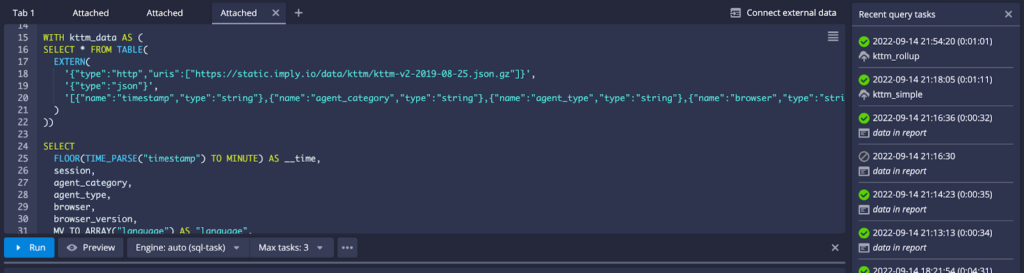
As part of this work, we have also revamped the query editor in the Druid web console. The query editor now features tabs! It can help you organize your workspace.
With tabs, you can now attach to previously run queries by expanding the “Recent query task panel” at the top right corner of the query editor.
Once expanded, you can select from any of the queries listed to show current progress.
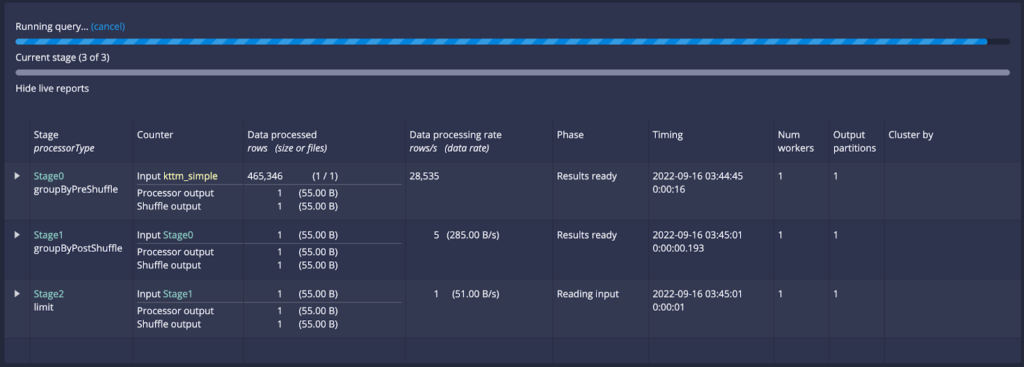
The new query engine has significantly improved live query reporting. Now you can monitor the progress of your queries in detail.
The new MSQE-powered SQL batch ingestion experience is now our recommended method to load batch data into Druid. Please give it a try!
Nested Columns
Real-world data often comes in nested shapes. Originally, most relational databases required data to be flattened into tables for loading and processing. Then came along document stores such as MongoDB and Elasticsearch, where the entire nested object can be stored as-is, greatly improving flexibility for developers.
In this release of Druid, we are introducing support for Nested Columns. It’s as simple as specifying the data type as “JSON” as part of your data ingestion spec. If you are using the new SQL-based batch ingestion, you can simply specify the column type to be “COMPLEX<json>”.
Once loaded, you can use functions like JSON_VALUE, JSON_QUERY, and others to query the data stored in the nested column. You can expect performance that matches or exceeds the performance of other Druid column types. For columns that are numerical types, you can expect 10-50% better performance when they are part of a nested JSON column.
In coming releases, we will be adding support for nested column support in formats beyond JSON, including Avro, Parquet, and Protobuf.
Other highlights
ZStandard(zstd) compression. This is a new option to compress data. It is about 8-10% smaller in terms of storage, but 25-80% slower on query reads. It is useful for storing large volumes of infrequently accessed data.
Kinesis ingestion improvements. We’ve made progress on better supporting Amazon Kinesis ingestion. The system can now gracefully handle empty shards and resharding, improving overall reliability.
Vectorization improvements. We have been continuously making improvements to query performance. In this release, we have added vectorization support for LATEST() and EARLIEST() aggregators. Those aggregators now perform up to 3X faster.
Experimental Java 17 support. Java 17 provides a new runtime environment that includes a new garbage collector. Early performance testing has shown some improvements with this new version of Java. We will continue to work on testing and fixing issues on the latest version of Java in coming releases.
Metrics
Druid 24.0 includes additional metrics and metric dimensions to help you better monitor and operate a Druid cluster:
segment/rowCount/avg
segment/rowCount/range/count
query/segment/time
worker/task/failed/count
worker/task/success/count
worker/taskSlot/idle/count
worker/taskSlot/total/count
worker/taskSlot/used/count
Want to contribute?
We’re very thankful to all of the contributors who have made Druid 24.0 possible – but we need more!
Are you a developer? A tech writer? Someone who is just interested in databases, analytics, streams, or anything else Druid? Join us! Take a look at the Druid Community to see what is needed and jump in.
Try this out today
For a full list of all new functionality in Druid 24.0, head over to the Apache Druid download page and check out the release notes!
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...