Reporting Data Warehouses and Real-Time Analytics Databases are Different Domains. Using the Right Tool for Your Requirements Is the Key to Success.
From a great distance, cloud-deployed Reporting Data Warehouses, like Snowflake, and Real-Time Analytics Databases, like Apache Druid®, look similar. Both enable asking questions of (and getting answers from) large datasets, and both use immutable segments to store data for parallel query.
For real-world projects, though, the two are very different. Understanding what each does well will let you decide whether you need one or both to reach your goals.
Snowflake: Reporting for the Cloud
In 2012, two engineers were looking for a better data warehouse. Legacy data warehouses, like Teradata, Vertica, Netezza, and Greenplum, were too expensive, while the then-emerging Hadoop tools were too complex to set up and too difficult to use. Thierry Cruanes and Benoit Dageville wanted a way to run reports where they could simply load and query data, and they thought they could do it using the cloud.
The two co-founded Snowflake to be a cloud data platform, designing a new database that uses the cloud to be scalable and cheap and uses automated services plus long-established SQL tools to be simple and easy to use.
In Snowflake, data is stored in buckets using object storage, like Amazon S3. Using buckets can cost up to 1,000x less than high-speed NVMe storage, and S3 is a very durable service, automatically creating multiple copies of each bucket in separate data centers to avoid data loss. But it’s slow … so Snowflake uses massive parallelism, splitting data into micro-partitions as small as 50MB, and placing each in its own bucket. So a Snowflake table with 1TB might be split into as many as 20,000 different buckets. While the read and write speeds of each bucket are slow, the parallel performance is fast enough to be useable, if still slower than high-speed disk.
Snowflake can also operate as a data lake, where data is not ingested into micro-partitions, but left in files to be queried by Snowflake. Of course, you can mix data between files and micro-partitions too, a concept known as a ‘data lakehouse’.
Meanwhile, Snowflake uses containers to spin up, use, and spin down compute resources (or, as Snowflake calls them, Virtual Data Warehouses or VDW). Again, this results in a lower cost, as you’re only paying for CPU and memory when you’re actually running a query – but it also has a cost in time, as Snowflake can spin up a container quickly, but not instantaneously.
As data warehouses go, Snowflake offers good concurrence, with up to 8 concurrent queries running in each Virtual Data Warehouse. When higher concurrency is needed, Snowflake can automatically spin up additional capacity, allowing up to 10 VDW running 80 concurrent queries, though at 10x the cost of a single VDW.
With this micro-partition-plus-on-demand-containers design, Snowflake can only run on the cloud. There’s no other option.
Snowflake also offers ‘time travel’, which allows reversing of queries (such as un-dropping a table) which occurred in the last few days. This removes one of the reasons for database backups, but creating and managing backup copies for archives and forensics is still required.
Nearly every organization has at least some need to generate reports, often monthly, weekly, or daily. As a cheap data warehouse that’s fast enough for most reporting needs, Snowflake is a common choice.
Real-Time Analytics Applications and Druid
Druid was first launched in 2011, trying to solve a very different problem: how to ingest a billion events in under a minute and query those billion events in under a second. Druid is an open source database, a top-level project of the Apache Software Foundation. Over 1400 businesses and other organizations use Druid to power applications that require some combination of speed, scale, and streaming data.
In Druid, source data is ingested from both files (batch ingestion) and data streams including Apache Kafka and Amazon Kinesis (stream ingestion). Data is columnarized, indexed, dictionary encoded, and compressed into immutable segments, which are distributed across one or more servers plus a copy in deep storage, usually an object store. This is similar to Snowflake micro-partitions, but copies are kept in both durable deep storage (usually object storage) and higher-speed storage teamed with compute and memory to enable high performance.
There are four characteristics of Druid that make it different than reporting data warehouses:
Subsecond performance at scale
Humans (and sometimes, machines) need to quickly and easily see and comprehend complex information, holding interactive conversations with data, drilling down to deep detail and panning outward to global views. Many Druid solutions support interactive conversations with large data sets, maintaining subsecond performance even with dozens of PB of data.
High concurrency
Large numbers of users can generate multiple queries as they interact with the data. Architectures that support a few dozen concurrent queries aren’t sufficient when thousands of concurrent queries must be executed simultaneously. Druid provides high concurrency affordably, without requiring large installations of expensive infrastructure.
Real-time and historical data
Real-time data is usually delivered in streams, using tools like Apache Kafka, Confluent Cloud, or Amazon Kinesis. Data from past streams and from other sources, such as transactional systems, is delivered as a batch, through extract, load, and transform (ELT) processes. The combination of data types allows both real-time understanding and meaningful comparisons to the past.
Continuous Availability
Druid is designed for nonstop operations. All data is continuously backed up, for zero data loss. When hardware fails, the Druid cluster continues to operate, requiring widespread failures to cause downtime. Planned downtime is never needed, as scaling up, scaling down, and upgrades can all be executed while the cluster continues to operate. Data from streams is ingested using exactly-once semantics, so stream data is also never lost, even in the event of a full outage of a Druid cluster.
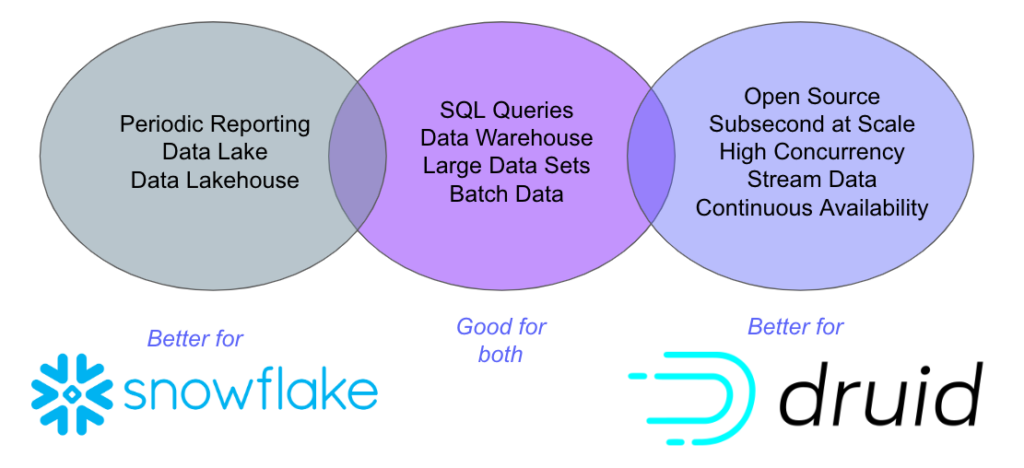
When to use Snowflake? When to use Druid?
Snowflake is the better platform for regular reporting (daily, weekly, monthly, and such), especially where performance isn’t important – when you’re running a weekly report, it usually doesn’t matter if it takes a few seconds or an hour, as long as it works reliably.
There are several use cases where both Snowflake and Druid are viable. For operational visibility, security and fraud analytics, and understanding user behavior, Snowflake may be a better option if performance, concurrency, and uptime are not important to the project. If an organization needs subsecond response times, high concurrency, or continuous availability, Druid is the better choice.
Druid is the better platform for interactive data exploration, where subsecond queries at scale enable analysts and others to quickly and easily drill through data, from the big picture down to any granularity. Druid is also the better platform for real-time analytics, when it’s important to have every incoming event in a data stream immediately available to query in context with historical data.
Druid’s high concurrency also makes it the better choice for applications where analytics are extended to customers or partners, where it’s difficult to predict how many queries must be supported at the same time.
Druid also has the advantage of being open source software. It can run on any platform, from a laptop, to self-managed clusters on-premise, to commercially-supported versions, to a cloud-delivered managed service.
If you’d like to try Druid for yourself, the easiest way to get started is with Imply Polaris, a fully-managed Database-as-a-Service. Get a free trial (no credit card needed!) at https://imply.io/polaris-signup/
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....