Druid 0.23 – Features And Capabilities For Advanced Scenarios
Jun 22, 2022
Will Xu
By Abhishek Agarwal & Will Xu
Features and capabilities for advanced scenarios
This is part two of the Druid 0.23.0 release blog. Many of Druid’s improvements focus on building a solid foundation, including making the system more stable, easier to use, faster to scale, and better integrated with the rest of the data ecosystem. This blog is intended for advanced users as well as potential/existing contributors of the Druid project who might want to peek behind the scenes.
Streaming: Druid improves integration with Kinesis
Kinesis supports dynamic re-sharding to accommodate traffic growth. During re-sharding, empty intermediate shards are created. Druid can potentially be stuck due to empty shards. In this release, we’ve added a new capability to ignore those empty shards. You can do this by setting skipIgnorableShards = True as part of Druid common settings or part of the ingestion context.
At the same time, Druid now supports newer, faster Kinesis APIs to query for Kinesis shards. You can access this by setting useListShards = True.
We recommend both settings for users who are using Kinesis ingestion and will make those settings the default in the future.
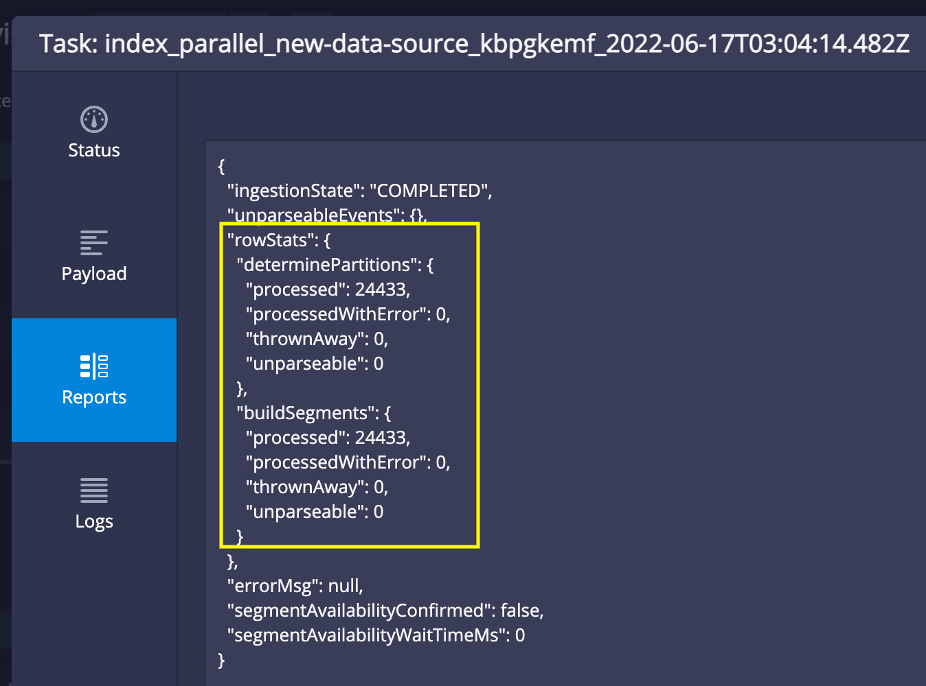
Task system: Task reports for parallel tasks
Druid now publishes task reports for parallel tasks. This is useful to monitor parallel tasks and is a necessary feature to move to native batch ingestion. The following image shows the parent task and the associated sub-tasks:
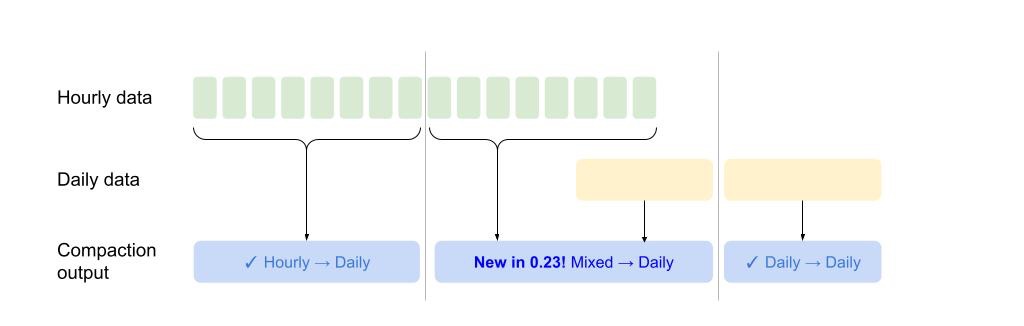
Auto-compaction improvements
Auto-compaction system helps you get optimal segment files to achieve good query performance. In this release, we have introduced two new changes to make this system more useful.
The first change supports auto-compaction of mixed granularity overlapping intervals, which was previously not possible. This paves the way to support changing the granularity of data based on the age of data in the future.
The second change allows resources to be used by the auto-compaction system to be adjusted independently from other tasks. This enables users to run auto-compaction more frequently than other tasks such as segment balancing and data drops.
There are also changes in webconsole’s segment view to help visualize the segment fragmentation issues. Specifically, if you see a significant variance between the size of the segments, it’s a good indication that there is some fragmentation of your data. Again, this is where applying auto-compaction can help your overall performance.
Over the next few releases, we aim to make the auto-compaction system enabled by default so segment files can stay optimized.
Querying: Better JDBC
There are a number of improvements around JDBC connection, such as handling trailing slashes, better logging as well as sanitization of exceptions. If you are using JDBC today, we definitely recommend you to upgrade and give the new version a try.
New things for Druid contributors
Overview for contributors
Below are the highlights from the release notes. For full details, please check out the full release notes.
Easier development
Add SQL query ID to response header for failed SQLl query (#11756)
Improved query IDs to make it easier to link queries and sub-queries for end-to-end query visibility (#11809)
Better internal typing systems
Added ARRAY_CONCAT_AGG to aggregate array inputs together into a single array (#12226)
Added a query context to use internally generated SegmentMetadata query (#11429)
Added support for Druid complex types to the native expression processing system to make all Druid data usable within expressions (#12016)
The Druid 0.23.0 release includes the following metrics and metric dimensions to help you better monitor and operate a Druid cluster:
New metrics
Auto-compaction duty group
Whether a query is vectorized
Shenandoah GC
CPU and CPU sets for cgroups
Jetty server thread pool
Batch tasks finish waiting for segment
New metric dimensions
Auto-compaction duty cycle
Work category for tasks
Druid also now includes a Prometheus emitter by default as well as supports proxying data through HTTP proxy.
Looking for contributors
We’re very thankful to all of the 81 contributors who have made Druid 0.23.0 possible – but we need more!
Are you a developer? A tech writer? Someone who is just interested in databases, analytics, streams, or anything else Druid? Join us! Take a look at the Druid Community to see what is needed and jump in.
Try this out today
For a full list of all new functionality in Druid 0.23.0, head over to the Apache Druid download page and check out the release notes!
Other blogs you might find interesting
No records found...
May 21, 2026
A First Look at Lumi Loglake: Query Logs Where They Live
TL;DR: Imply Lumi Loglake is a lakehouse (separated compute/storage) architecture for unstructured logs that reduces costs from 40% up to orders of magnitude on your hardware/AWS/Azure bill used to run your...
Imply Lumi Major Release Preview: Continuing the Journey Towards Decoupled Observability/SIEM
We are getting ready to introduce the next major expansion of Imply Lumi and the observability warehouse. When we introduced the industry’s first observability warehouse, the goal was clear: decouple the...
Imply Lumi's Grafana Loki integration is now in Private Preview. The same logs you've loaded into Lumi for Splunk are now queryable natively in Grafana using LogQL with no second pipeline, no duplicate storage,...