Our customers often come to us with use cases that require upserts or data deduplication. After digging into the use cases and the problems the customer is attempting to resolve, we find better approaches that are well-supported by Druid. Sometimes, we find that the use case really does require these capabilities, and the use of an external function is required. That said, in this blog, I’d like to tackle what can be done with Druid for upserts and data deduplication.
“Upsert” means “update if found, insert otherwise”. On the other hand, “deduplication” is the process of ensuring that only a single row exists for a particular key. These two functions are similar, in that they both rely on a key to identify a row. If users are generally upserting data into a table, that would also ensure deduplicated data. The main idea being that upserting means the user wants the latest version of the data whereas deduplication means the user wants any version of the data since they are all duplicates. So from here on, this blog will only be concerned with upserts, and there are several options for doing them with Druid, depending on the use case.
1. Upserts Using Batch Ingestion
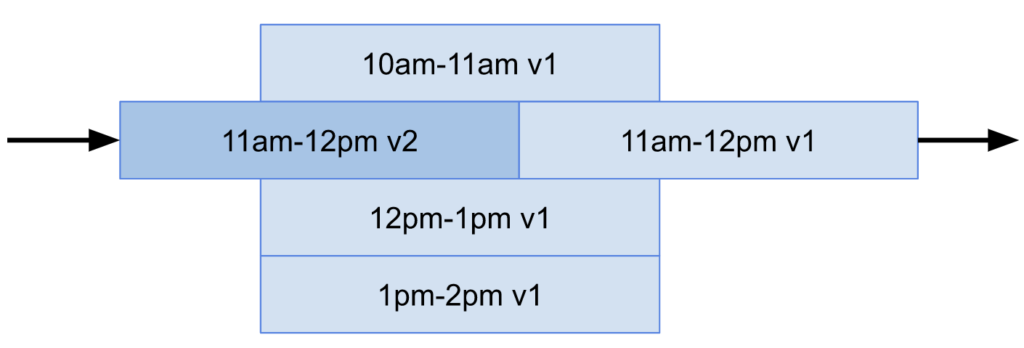
One possibility is to rewrite Druid time chunks (ie Druid time partition) with the latest data for that time chunk. This is relatively expensive at upsert time since you would need to reindex all the data in that time chunk, even if a single row changes. It also means that you would need to have the updated version of all the data in that time chunk handy for reingestion in a single job, which is often not the case. That said, this does provide the best query performance since the data will be already in its optimal form for querying.
Time partitions with one time partition being completely replaced by another
This is useful in situations where the upsert volume is not high (meaning the data is not changing often), and it’s not that important to make the upsert visible quickly. A useful strategy for a production deployment would be to batch upserts until there’s a sufficient number of them to be worth an ingestion job. Most use cases involving this solution would be situations where Druid is used as a materialized view over data that resides in another system such as in S3 or in a data warehouse and kept up to date. Then the latest data for any particular time chunk is always readily available for reloading into Druid.
2. Upserts Using Query-time Aggregation
Sometimes users just want to read the latest value of some field y for some key field x. If you append all updates (instead of upserting them) during ingestion, then you can do a query like SELECT x, LATEST_BY(y, update_timestamp) from tbl GROUP BY x to get the latest values. Note that you’ll need an update timestamp to be added so Druid can track the latest version. However, if you use this as a subquery and do further processing on top of it, for example:
SELECT w, SUM(latest_y) from (SELECT w, x, LATEST_BY(y, update_timestamp) as latest_y GROUP BY x) GROUP by w
And there are a lot of x in the subquery, this query could be expensive – though enhancements to Druid that make this sort of query faster are on the way (see this blog article). This pattern is useful in situations where there aren’t that many distinct x or where the performance requirement for these kinds of queries is not very demanding.
The table below is an example, where x is user_id and y is points. To get the latest points at each hour for each user_id, execute:
SELECTFLOOR(__time toHOUR) as hour_time, user_id, LATEST_BY(points, update_timestamp) from tbl GROUP BY1, 2
__time
update_timestamp
user_id
points
1:00pm
1:00pm
funny_bunny1
10
1:00pm
1:05pm
funny_bunny1
20
2:00pm
2:00pm
funny_bunny1
5
2:00pm
2:00pm
creepy_monkey1
30
2:00pm
2:05pm
creepy_monkey1
25
3:00pm
3:00pm
funny_bunny1
10
The result of that SELECT statement looks like:
hour_time
user_id
points
1:00pm
funny_bunny1
20
2:00pm
funny_bunny1
5
2:00pm
creepy_monkey1
25
3:00pm
funny_bunny1
10
A mitigation for the cost of these kinds of queries is to set up a periodic batch ingestion job that reindexes modified data into a new datasource for direct querying without grouping. Another mitigation is to do ingestion-time aggregation, and to use that LATEST_BY aggregation at ingestion time, appending the upserts through streaming ingestion into a rolled up datasource. Because appending into a time chunk adds new segments and does not perfectly roll up data, so rows may be partial rather than complete rollups, and you may have multiple of these partially rolled up rows, you would still need to use the GROUP BY query for correct querying of that data source. But if you set up autocompaction right, you will be able to significantly reduce the number of stale rows and improve your performance.
3. Upserts Using Deltas
This is similar to the previous method, but rather than appending the new value and then using LATEST as the aggregator, you would use the aggregator you usually use. This allows you to possibly avoid a level of aggregation and grouping in your queries since you would issue the same queries as usual. The example is a datasource with a measure column y that’s usually aggregated by SUM. Say that the old value of y for some x was 3 and you want it to be 2. Then you’d insert a y=-1 for that x, and that would allow you to have the correct value of y for any queries that sum y grouped by x. This could offer a significant performance advantage but may be less flexible since now the aggregation has to always be a SUM. In other cases, the updates to the data may already be deltas to the original, and so the data engineering required to append the updates would be simple. Another simplification here is that the update timestamp is no longer needed since all the data is used. Just as before, the same mitigations as the previous case apply to improve performance with autocompaction and rollup at ingestion time.
Below is an example table that would provide the same results as before with a different query:
SELECTFLOOR(__time toHOUR) as hour_time, user_id, SUM(points) from tbl GROUP BY1, 2
__time
user_id
points
1:00pm
funny_bunny1
10
1:00pm
funny_bunny1
10
2:00pm
funny_bunny1
5
2:00pm
creepy_monkey1
30
2:00pm
creepy_monkey1
-5
3:00pm
funny_bunny1
10
A Note on Deduplication
In the last two upsert processes described above, we alway needed some way to identify a time of update. For deduplication, the time of update is not necessary since all versions of a row are the same. We also would likely not want to use the LATEST aggregator for grouping, since ANY is good enough. Do you have a use case for upserts or deduplication? Do one of these three models work for you, or are you doing something else? Please contact us and let us know!
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....