Overview
Confluent is a Silicon Valley based software company most well known for Apache Kafka®. Their streaming platform, based on Kafka, enables companies to easily access data as real-time streams. Confluent’s cloud-native platform is designed for real-time data and enables companies to connect applications that utilize real-time streams to make decisions immediately if need be.
Challenge
To meet their strict performance and availability SLAs for Confluent Cloud, their fully managed data streaming platform, Confluent built an internal-facing observability application powered by Apache Druid. Confluent turned to Druid because their existing NoSQL database could not keep up with their data growth.
With Confluent Cloud, Confluent manages a large number of multi-tenant Apache Kafka clusters across multiple cloud providers, including Azure, GCP, and AWS. To deliver the best user experience running on their infrastructure, it’s critical Confluent has real-time monitoring and operational visibility for their customer’s mission-critical workloads. Confluent’s first attempt at building an observability pipeline was with a NoSQL database to store and query telemetry data. As the volume of data grew, Confluent’s legacy pipeline struggled to keep up with their data ingestion and query loads. Next, they looked into off the shelf observability solutions but quickly determined these could not handle their requirements.
Solution
Confluent evaluated both Apache Druid and Clickhouse. They quickly ruled out Clickhouse because they found it required writing C++ plugins if they wanted to read custom format data from Kafka. Ultimately, they chose Druid as the database to power their next-gen observability platform.
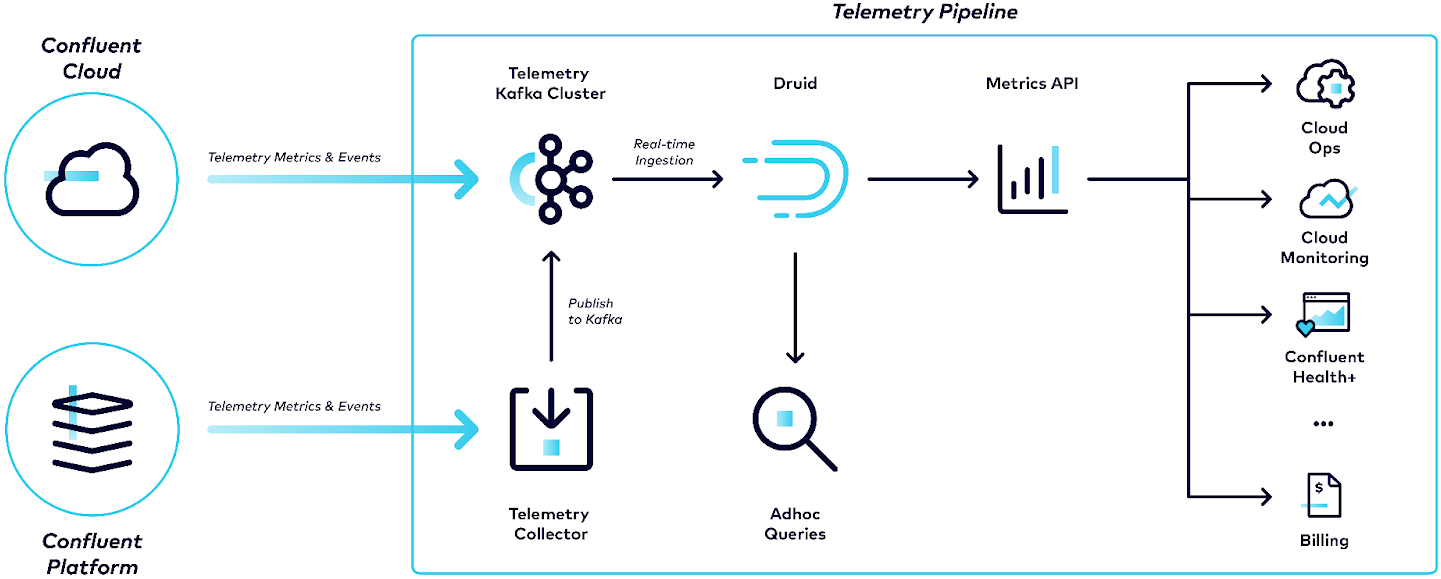
All Confluent Cloud clusters, as well as customer-managed, Health+-enabled clusters, publish metrics data to Confluent’s telemetry pipeline. Under the hood, the telemetry pipeline uses a Confluent Cloud Kafka cluster to transport data to Druid. From there, Druid’s real-time ingestion consumes high volumes of data from the Kafka cluster and ultimately provides low-level queries.
Confluent engineers often execute ad hoc queries directly against Druid for debugging purposes in their cloud infrastructure. This has helped Confluent tune configurations such as memory size, disk size, load-balancing thresholds, throttling thresholds, and more. With Druid, Confluent is able to have self-balancing enabled on Coniuent Cloud to continuously monitor resource utilization of their cluster and load load-balance when necessary.
Results
“Our North Star vision is to automate all of our Druid deployments using a one-click solution and make Druid completely self-service internally within Confluent to support a variety of use cases. And, we are striding toward this vision while continuing to power cloud-scale analytics!”
With Druid, they now handle 100x of the data volume and query load, deliver sub-second query latencies on high cardinality metrics, and get native Kafka ingestion. By ingesting over 3.5 million events per second and handling hundreds of queries on top of that, Confluent has real-time insights into the operations of thousands of clusters within Confluent Cloud. Confluent also leveraged Druid to build an externally-facing application, Confluent Health+, which extends performance and health insights to their customers.
For more information on Apache Druid and Confluent, watch the 2022 Druid Summit Keynote Session: Building Next-Gen Observability at Confluent
Source: https://www.confluent.io/blog/scaling-apache-druid-for-real-time-cloud-analytics-at-confluent/