Overview
Analytics is not just for internal stakeholders anymore. Companies like Atlassian, Pinterest, and Expedia provide analytics to their customers as part of a value-added service or as their core product offering. Customer-facing analytics applications provide valuable insights into a range of business metrics, from product performance and user behavior to billing and security.
But if you’re building an analytics application for customers, you might wonder, ‘which database is right for the job?’
Many turn to data warehouses such as Snowflake or lakehouses like Databricks to power analytics use cases. These types of databases are widely deployed and designed to support traditional analytics workflows like BI dashboards and reporting. However, delivering analytics to external users is a very different endeavor—these applications must provide subsecond performance at scale, high concurrency, and unrestricted drill-down on real-time and historical data.

An additional requirement is common for customer-facing applications: continuous availability. Unlike reporting analytics, where outages have a limited impact, customer-facing applications have no tolerance for downtime or data loss. Customer-facing means “always-on”—the alternative is to risk revenue, or worse, your customer’s loyalty.
So, what should you consider when building a real-time, customer-facing analytics application? Let’s first unpack the technical challenges of building analytics applications that can scale to hundreds of thousands of users and beyond.
Challenges
Interactivity: “The spinning wheel of death”
We all know it and hate it: the spinning wheel that indicates a bottleneck of queries in a processing queue. Depending on the purpose of the application, query latency is annoying at best, and detrimental at worst. While it’s generally OK to have an internal analyst wait several seconds or minutes for a report to process, response time is critical when the application’s end user is a customer or thousands of customers.
The root cause of the dreaded wheel comes down to the amount of data to analyze, the processing power of the database, and the number of users and API calls—i.e. the ability of the database to keep up with the application.
Now, there are a few ways to build an interactive data experience with any generic analytics database when there’s a lot of data, but they come at a cost:
- Precomputing: Precomputation is a common technique used in data retrieval and analysis; it’s a trade-off between time and space, query speed and update flexibility, online processing, and offline processing. The potential downside of precomputed queries is a costly and rigid architecture that doesn’t allow for ad hoc data exploration.
- Pre-aggregation: Typically seen as a way to speed up query times, pre-aggregating data is a way of organizing data before its queried. But this approach requires schema consistency and maintenance. Also, if the database you’re using isn’t designed to aggregate terabytes-to-petabytes of information quickly, it can be one of the biggest bottlenecks at execution time.
- Data retention limits: There are many factors to consider when deciding what data to make available for analysis, and for how long. But in general, limiting the data analyzed to only recent events doesn’t give your users the complete picture. Putting real-time information in context with historical data will provide the most comprehensive view.
The “no compromise” answer is an optimized architecture and data format built for interactivity at scale.
Availability: Necessity vs. ‘nice to have’
When building a backend for periodic internal reporting, or BI dashboards for use during business hours, planned (or even unplanned) downtime is generally tolerated. A few minutes of downtime during the day or an overnight maintenance window aren’t considered major disruptions. Most OLAP databases and data warehouses were built with this in mind—that’s why downtime is generally acceptable for analytics systems.
But now, your team is building a customer-facing analytics application for an unrestricted number of users. In this scenario, downtime can directly impact revenue and take up valuable engineering time. For this reason, resiliency—which means high availability and data durability—is an important characteristic of a database powering external-facing analytics applications.
Building resiliency into your analytics framework requires re-examining the design criteria. Can you protect yourself from a node or a cluster-wide failure? Can you afford data loss? What processes are in place to protect your application and your data?
Server failures are inevitable. A typical way to ensure resiliency is to replicate nodes and remember to make backups. But if you’re building applications for customers, the sensitivity to data loss is much higher. Even the ‘occasional’ backup is simply not going to cut it.
Cost: A consequence of growth?
The best applications have a number of things in common: many active users, an engaging experience, and seamless interactivity, to name a few.
To set your application (and its users) up for success, it’s important to build for high concurrency. Concurrency is what allows multiple users to access data at the same time. Databases that handle high concurrency can process more than a thousand queries per second (QPS). Concurrency is easier to account for when the user base of an application is smaller and finite, the way it is for internal reporting systems or BI workflows. It may not make sense, then, to use the same database in high-concurrency applications as you would for traditional analytics use cases.
Building an analytics backend for high concurrency comes down to striking the right balance between CPU usage, scalability, and cost.
One way to address concurrency is to invest in more hardware. If you increase computing power by spinning up more CPUs, you’ll be able to run more queries. And while this is true, it comes at a cost. With a general-purpose database or data warehouse, scaling for near-unlimited users also requires a near-unlimited budget to keep your application from crashing.
Solutions
Whether deployed or in development, your customer-facing analytics applications are critical to the “stickiness” of your product, the satisfaction of your customers, and the success of your business. That’s why it’s important to build the right data architecture.
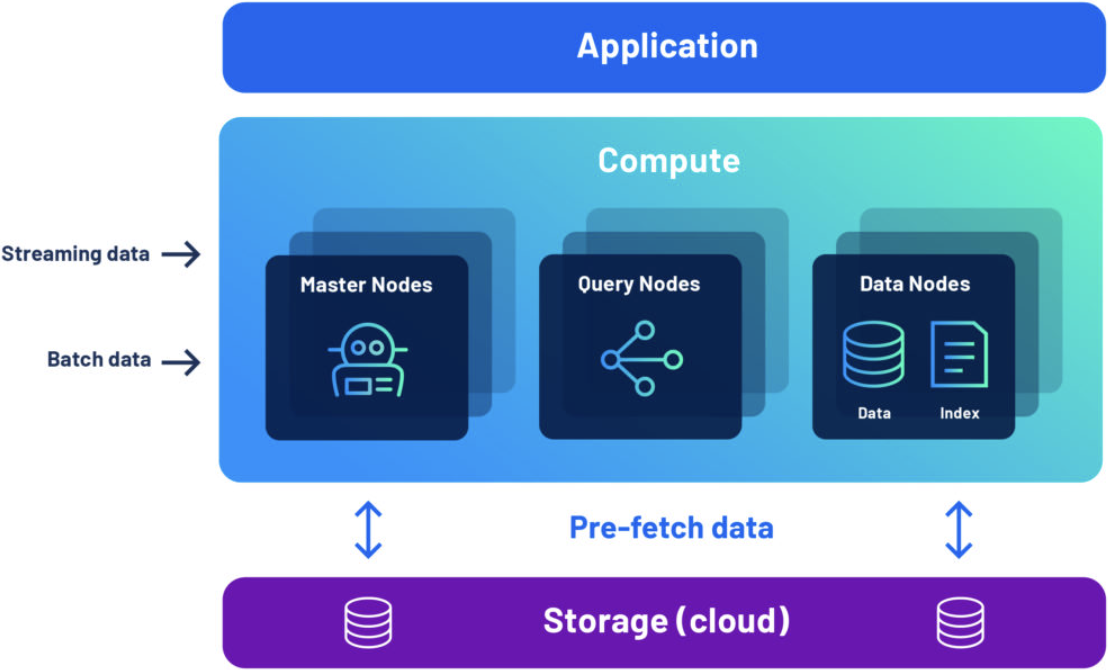
Apache Druid is the real-time analytics database built specifically for these types of applications. It enables subsecond performance at scale, provides high concurrency at the best value, and easily combines real-time streaming data and historical batch data. How does it do this?
- First, Druid has a unique distributed and elastic architecture that prefetches data from a shared data layer into a near-infinite cluster of data servers. This architecture enables faster performance than a decoupled query engine like a cloud data warehouse because there’s no data to move and more scalability than a scale-up database like PostgreSQL/MySQL.
- Second, Druid employs automatic, multi-level indexing built into the data format to drive more queries per core. This goes beyond the typical columnar format of a traditional analytics database with the addition of a global index, data dictionary, and bitmap index. This maximizes CPU cycles for faster data crunching.
- Third, Druid is designed to withstand server outages without losing data (even recent events). Druid implements HA and durability based on automatic, multi-level replication with shared data in S3/object storage. It enables the HA properties you expect as well as what you can think of as continuous backup to automatically protect and restore the latest state of the database even if you lose your entire cluster.
We recognize the time and effort that goes into developing real-time analytics applications. Fortunately, you’ve got the entire Druid community by your side. As of 2023, over 1,400 organizations use Druid to generate insights that make data useful, in a wide variety of industries and for a broad range of uses. There are over 10,000 developers active in the Druid global community. Find them on Slack, GitHub, and Twitter.
Example
Atlassian develops products for software developers, project managers, and other software development teams. The company’s Confluence Analytics Experience team builds customer-facing analytics features for Confluence, an industry-leading team workspace application. These features surface user behavior insights to Confluence customers, resulting in increased adoption and higher engagement on the Confluence platform.
The team of Atlassian developers building Confluence Analytics needed a real-time analytics database that could:
- Deliver an interactive experience to a large number of concurrent users
- Be flexible and extensible for new feature development
- Handle data and user growth without compromising performance
To meet these requirements, the team chose to integrate Druid into their analytics architecture. Druid replaced PostgreSQL as a query engine for event-based data. The PostgreSQL solution required the team to write custom code for handling large aggregations because of its inability to scale beyond two years of data retention at varying granularities. As a result, queries were high-maintenance and prone to error.
On top of that, pre-aggregations of data in PostgreSQL couldn’t keep up with users’ need for real-time information—leading to sub-optimal user experience. The application’s response time slipped from milliseconds to several seconds, making it difficult for users to interact with the data.
Since adopting Druid, the Atlassian team has seen massive performance improvements in the analytics features of Confluence, with low latency of 100ms or less. They’re able to easily increase data retention for up to five years or more. They also have the ability to do funnel analysis on up to two years of data with no impact on real-time data ingestion or aggregation. Click here to learn more about Atlassian’s journey with Druid.