Apache Druid: Making 1000+ QPS for Analytics Look Easy
Jul 25, 2023
David Wang
We saw in this blog post that scaling analytics for high queries per second (QPS) needs some consideration. If your queries are retrieving single-rows in tables with few columns or rows or aggregating a small amount of data, then virtually any database can meet your QPS requirements.
But things start getting hard if you have an analytics application (or plan to build one) that executes lots and lots of aggregations and filters across high dimensional and high cardinality data at scale. The kind of application where lots of users should be able to ask any question and get their answers instantly without constraints to the type of queries or shape of the data.
Apache Druid is a popular, open-source real-time analytics database that was designed from the ground up for interactive, sub-second queries at tremendous scale and load. Target uses Druid for analytics applications that execute over 4 million queries per day with an average response of 300ms; Confluent powers a customer-facing application requiring 350 QPS on data streaming in at 5 million events per second.
1000s of companies use Druid when there’s a live person or automated decisioning pipeline on the other end of a query. And they can do this under load with far fewer computing resources than with other databases.
You might be thinking “those queries must be pre-computed”. But they’re actually not; it’s all raw horsepower driven by Druid’s architecture. So how does it do it?
Because open source is awesome, there’s no black box voodoo magic or marketing hype at play here. This post takes you through the key design elements that enable Druid to uniquely achieve 1000+ QPS for analytics without breaking a sweat (or breaking the bank).
Optimized data format
For high QPS, the database has to do 2 things well: process each query lightning fast and do a lot of them at the same time. Since we’re talking about analytics queries that could involve reading a lot of data, the key to fast processing is to minimize the computing work. Druid’s architecture is very focused on CPU efficiency to process complex queries with potentially trillions of rows in under a second. And this starts with Druid’s data format.
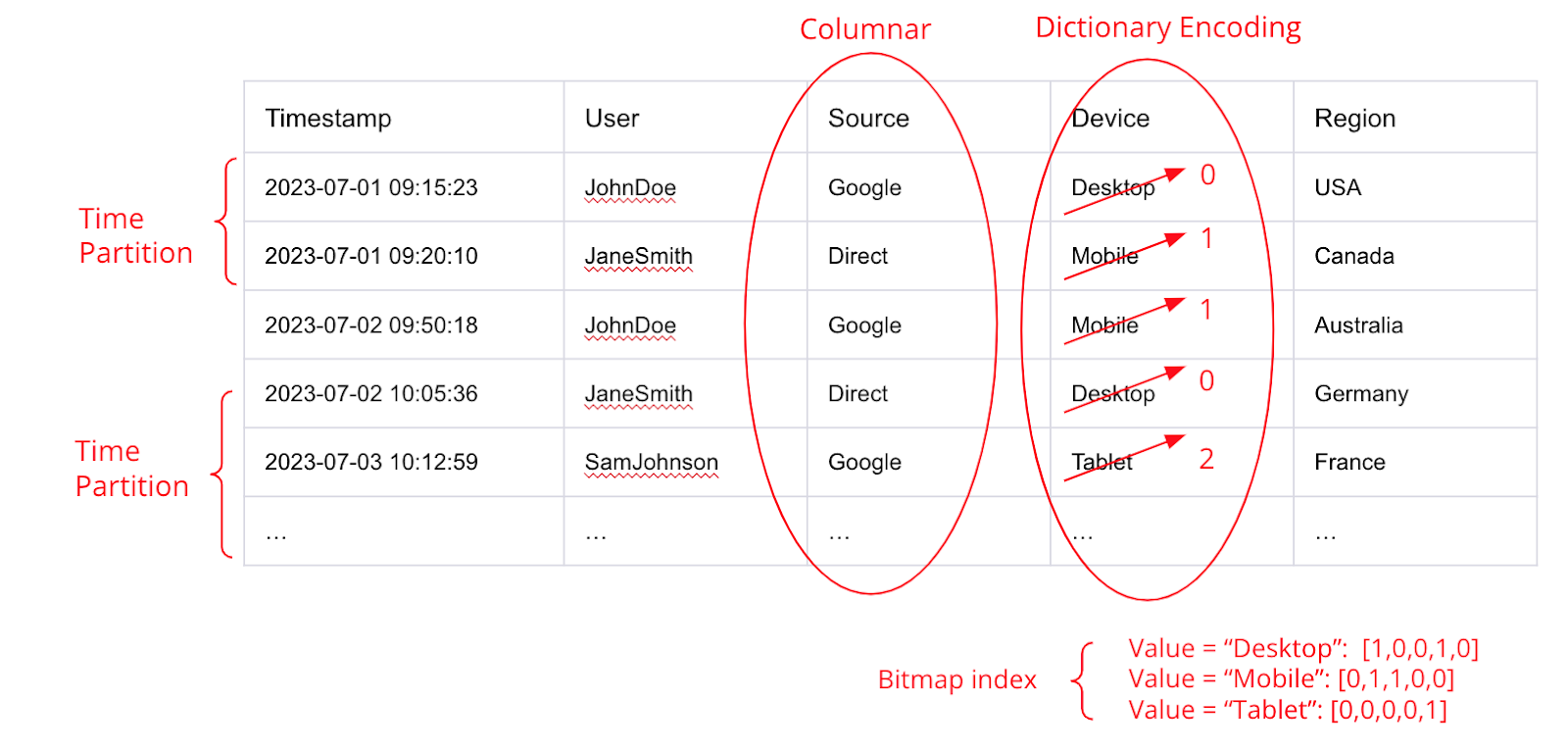
It’s common for analytics databases to store data in columns rather than rows. This way aggregate functions will only read the columns in the query. Druid stores in columns too, but it does much more to optimize how data is stored.
For starters, Druid is optimized for time-series data. Druid utilizes a timestamp column as a primary dimension for organizing data in files known as segments. This column is indexed in a way that enables efficient filtering and querying based on time intervals or windows and quick locating of the relevant segments.
What this allows Druid to do is quickly locate and process only the relevant data when filtering by a time window of interest so you can ask questions like what happened in the last hour, how did that compare to last week, etc with very fast response times.
Additionally, Druid stores dimension columns with dictionary encoding and inverted indexes (aka bitmap indexes) and they are type-aware compressed, which both minimizes how much CPU is needed and reduces the amount of data storage.
While the use of indexes isn’t new, Druid’s implementation is out of the box: it’s built into its data format and is much easier to work with than anything else.
As data is ingested, Druid automatically manages and updates the indexes. This is in contrast with other databases where indexes require a lot of advance planning and maintenance. Druid doesn’t require anyone to maintain the indexes – they’re all automatic.
Scatter/gather with pre-loaded data
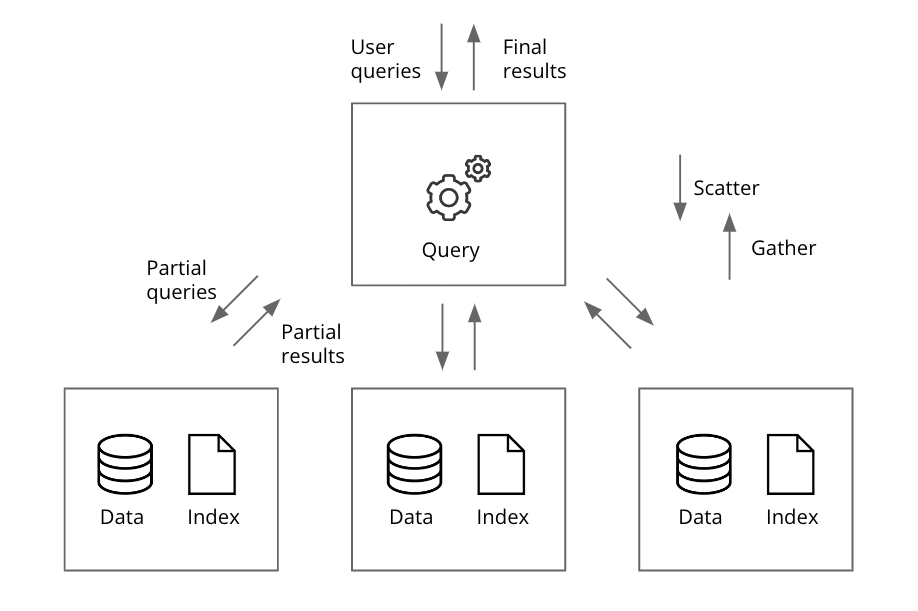
The relationship between storage and compute plays a key role in delivering high QPS for analytics: don’t read the full data set if you can read a smaller index, don’t send data unnecessarily from server to server and don’t move data from deep storage at query time if you need fast queries.
Druid embraces this thinking and at the heart of its interactive query engine is the scatter/gather technique. With scatter/gather, queries are scattered across multiple computing nodes that contain the relevant segments for parallel processing. Each node performs computations on its local subset of the data. Afterward, the results are gathered from those nodes for the final result.
But it’s not simply about running queries in parallel.
For the fast queries, Druid intelligently pre-loads the segments into the right data nodes so queries are not waiting for data to move from deep storage to where compute is (unlike cloud data warehouses, which separate compute and storage for reports/BI workloads). It’s intelligent because Druid determines the right performance-optimized and time-aware nodes across potentially thousands of nodes and millions of segments to get the right price for performance.
Extensive multi-threading and parallelization
Many modern databases are designed with multithreading to handle concurrent operations. This allows multiple execution threads to run concurrently, enabling parallel processing of queries.
That said, the degree of multithreading in Druid and its specific implementation is a unique technical characteristic of its architecture, which lends itself to be very effective at high QPS for analytics. Druid utilizes multithreading extensively with specialized thread pools, task schedulers, and resource management mechanisms to optimize high performance under load.
Here are some key aspects of Apache Druid’s approach to threading:
Process-specific parallelization: To say Druid is a distributed architecture would be a bit of an understatement. Druid parallelizes everything through multithreading. From ingestion, to indexing, to segment processing, to query execution are all done in parallel across multiple threads. This approach to parallelization enables efficient utilization of CPU resources and speeds up query execution and data processing.
Thread pooling: Druid employs thread pools, which are pools of reusable threads, to manage and control the execution of tasks. Thread pools allow for efficient thread reuse, minimizing the overhead of thread creation and destruction, and enhancing performance by enabling concurrency and workload parallelization.
Resource allocation and isolation: Druid’s threading approach involves allocating and isolating specific threads or thread pools for different tasks, such as query processing, data ingestion, and background maintenance. This allows for fine-grained control over resource allocation and prioritization, ensuring optimal performance for different aspects of the system.
Dynamic scaling: Druid’s threading model supports dynamic scaling of thread pools based on workload demands. This means that the number of threads can be adjusted dynamically to match the current workload, enabling efficient resource utilization and scalability. If you need to scale for concurrency, then easily borrow from a different pool.
These characteristics of Apache Druid’s approach to threading are built to address the requirements of real-time analytics and data exploration use cases where high QPS is critical. The configurability in Druid also enables developers to customize their environments and scale and optimize process-specific resources and thread pools easily.
Fine-grained data replication per segment
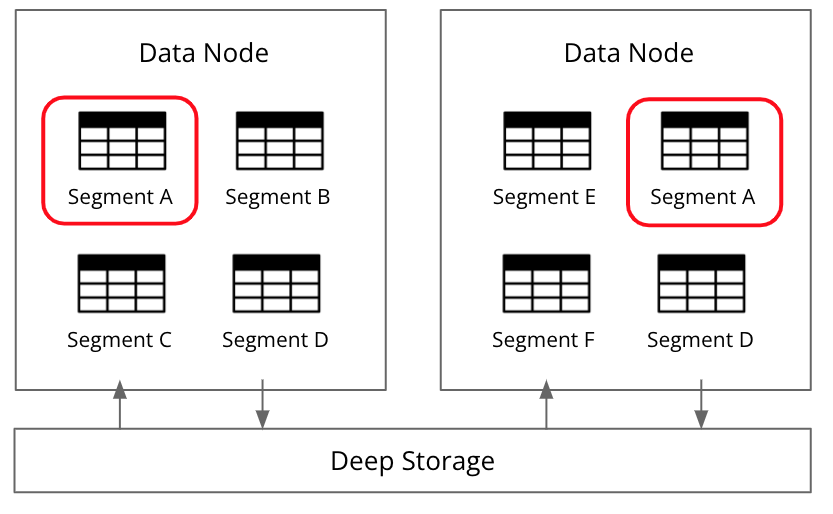
Earlier we saw that Druid stores data in segments – ie. files that are primarily partitioned by time and contain a few million rows. Druid replicates data at the segment level vs node-level (which is common in PostgreSQL, MySQL, and Oracle). Segment-level allows for fine-grained control over replication and this plays a key role in high concurrency and high availability too.
With segment-level replication, the same segment can be processed concurrently on different nodes. As you can see in the picture below, Segment A is replicated on multiple data nodes. And with scatter/gather, concurrent queries for Segment A can then be executed on all of the nodes that contain that data segment, enabling better parallelization and resource utilization for better query performance and concurrency.
While this is a simple view of segment-level replication, Druid scales to support very diverse analytics queries across millions of segments across thousands of nodes without a developer managing the segments or the nodes. At scale, it’s a pretty phenomenal orchestration: the creation of segments, the automatic pre-loading of data into the optimal nodes, the movement of segments for load-balancing, and concurrency to support 1000+ QPS – all done automatically.
It’s like this really neat ultra-precision of data distribution meets parallelization meets hands-free developer experience.
Druid is purpose-built for high QPS
Clearly one of the reasons why 1000s of companies turn to Apache Druid is that it is built for analytics applications with high QPS requirements. And it’s pretty unique in this respect.
Recently, Imply completed (and won) a proof-of-concept (POC) at a company building a customer-facing data product. Their core application is used by over 500 million users around the world and they needed to build an application that provides platform usage-insights to customers.
As it is a customer-facing application, performance is critical and the POC required 1300 QPS on complex aggregations and filters on very large data sets. Competing with Clickhouse and Apache Pinot, Apache Druid with Imply far exceeded the expectations, delivering 1400 QPS! It’s also worth noting that the customer valued time-to-market and the ease by which Druid scaled and the Imply team brought too.
So if you’re building or supporting an analytics application requiring high QPS, you’ll be in good hands with Druid. To give it a try, download Apache Druid or try out Imply Polaris, the cloud database service for Druid, for free.
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....