Apache Druid® is an open-source distributed database designed for real-time analytics at scale.
Apache Druid 28.0 is a feature-packed release that contains over 420 commits & 57 contributors.
This release contains important changes on the query engine side for better SQL compliance, some of which are not backward compatible. Please review the upgrade notes section of the release notes carefully before adopting the latest version.
For the multi-stage query engine (MSQ), we officially graduated async queries, querying from deep storage, and UNNEST from experimental status to GA. At the same time, we have added support for UNION ALL.
On the querying side, we’ve added experimental support for window functions.
For the ingestion system, nested column ingestion is now the default for auto-discovered columns, and it now creates arrays instead of multi-value dimensions for better query stability. Apache Kafka users can now ingest multiple Kafka topics into a single datasource.
Last but not least, this release introduces experimental support for concurrent append and replace. This allows streaming ingestion and compaction systems to gracefully handle late arrival data without causing fragmentation.
Please read on for the details on the above-highlighted features. We are excited to see you use the latest version and to share your questions and feedback in the Druid Slack channel.
Async query and querying from deep storage improvements
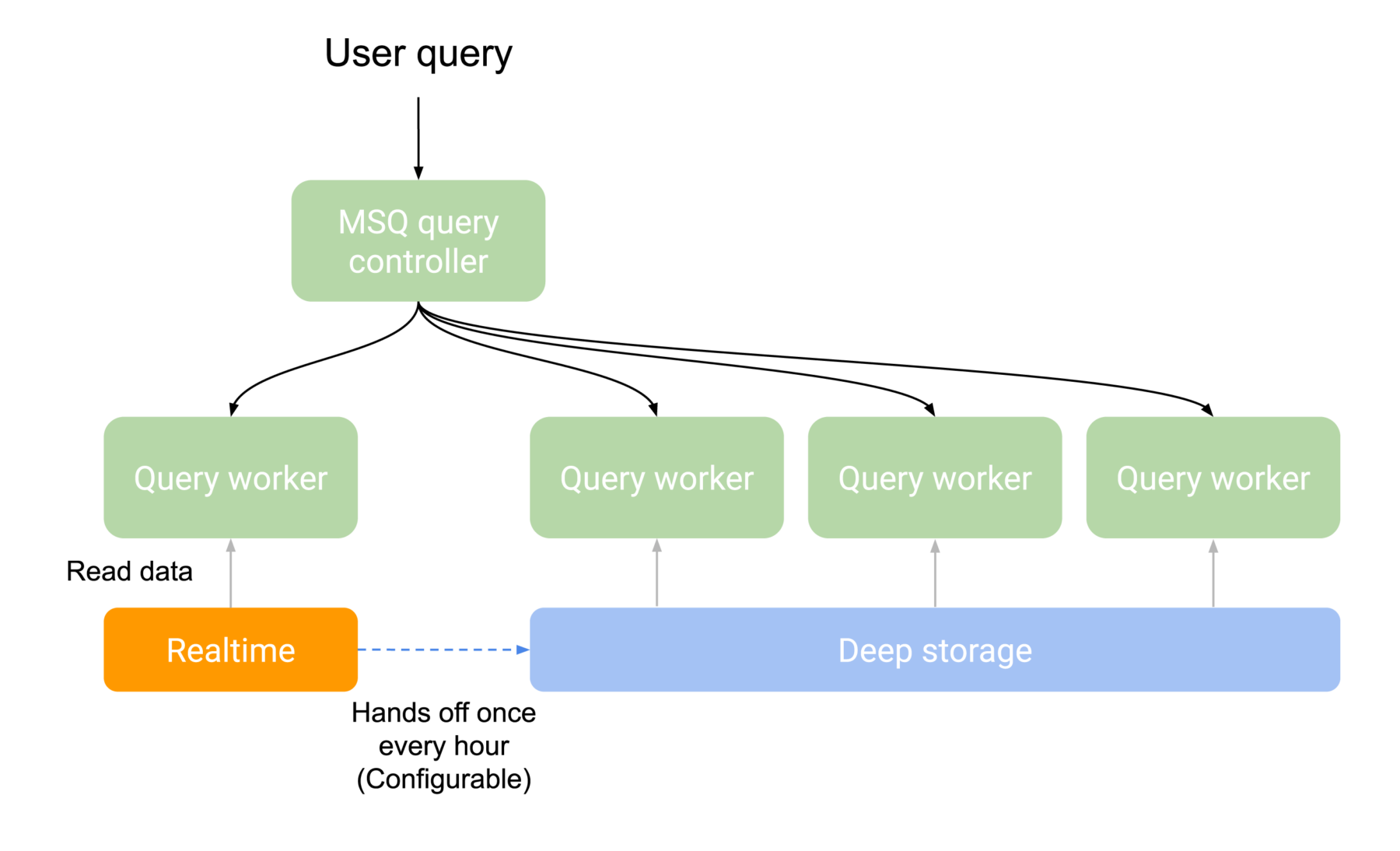
Earlier this year, Druid introduced the support for querying deep storage directly through the multi-stage query engine (MSQ). This is a major capability that enables users to use Druid both for low-latency analytics queries as well as for cost-efficient high-latency queries. However, there were a few limitations; for example, querying from deep storage did not include real-time data that was not yet committed to a segment file. This doesn’t match the common query pattern, such as downloading the last two weeks of data, where the user expects the results to include the last hour or so of real-time data.
In this release, the MSQ engine can query real-time ingestion nodes to retrieve the latest real-time data and automatically merge them into the final query result.
This welcome addition sets up Apache Druid to use segment files that have been pre-fetched to Historical processes, paving the way to improve query performance in the future.
Committers added support for using Azure BLOB storage for intermediate, durable storage. This enables MSQ to run well with fault tolerance support on Azure.
To make things easier for building applications, the querying API can support multiple kinds of result formats.
Async query is also available with Imply’s SaaS offering, Imply Polaris. Taking advantage of Imply Polaris’ fast auto-scaling capabilities, we arm users with the ability to run async queries on demand without impacting the performance of their analytical queries or their ingestion jobs.
Array ingestion and numerical array improvements
SQL-based ingestion now provides a way to create array-type columns as true arrays rather than multi-value string dimensions (MVDs). Prior to 28.0, incoming data was stored as a string and then implicitly unnested during querying, making the support of certain query patterns, such as numerical arrays, difficult.
In this release, Druid supports creating array-typed columns during SQL-based ingestion, and schema auto-discovery now supports auto-discovered arrays as well.
SQL UNNEST GA with MSQ support
Now, you might have noticed an implicit unnesting with MVDs as mentioned above. With arrays, this doesn’t quite work because sometimes people want to use arrays as grouping keys without unnesting them. To ensure these scenarios are fulfilled, we are making SQL UNNEST support generally available in this release as well.
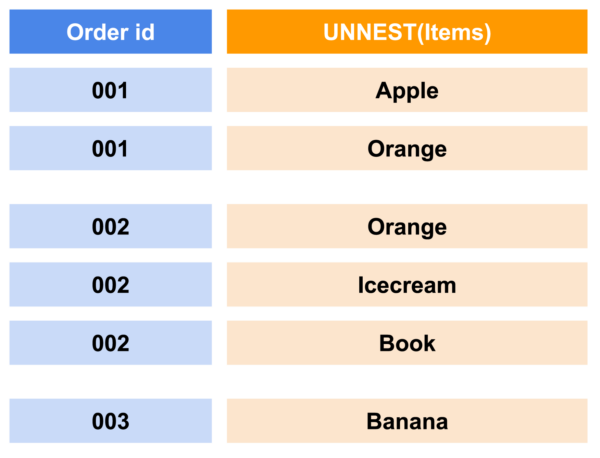
Having a “third dimension” to a table is common. For example, if you have a record representing a customer’s order, each of the line items in an order is usually represented as an array. To find the top-ordered items, databases need to provide a way for developers to select within the array of items.
One method is to convert the array of items into individual rows.
When using multi-value dimensions for the list of items, Druid automatically unnests the data to individual rows when you issue a group by query. With Druid 28, SQL UNNEST and the array data type allow you to decide whether to treat the list as an array or to UNNEST it into individual rows.
UNNEST works on both queries and ingestions. Coupled with the introduction of the asynchronous query, you can run reporting-style queries in a more flexible way when working with arrays.
Multi-topic Apache Kafka ingestion
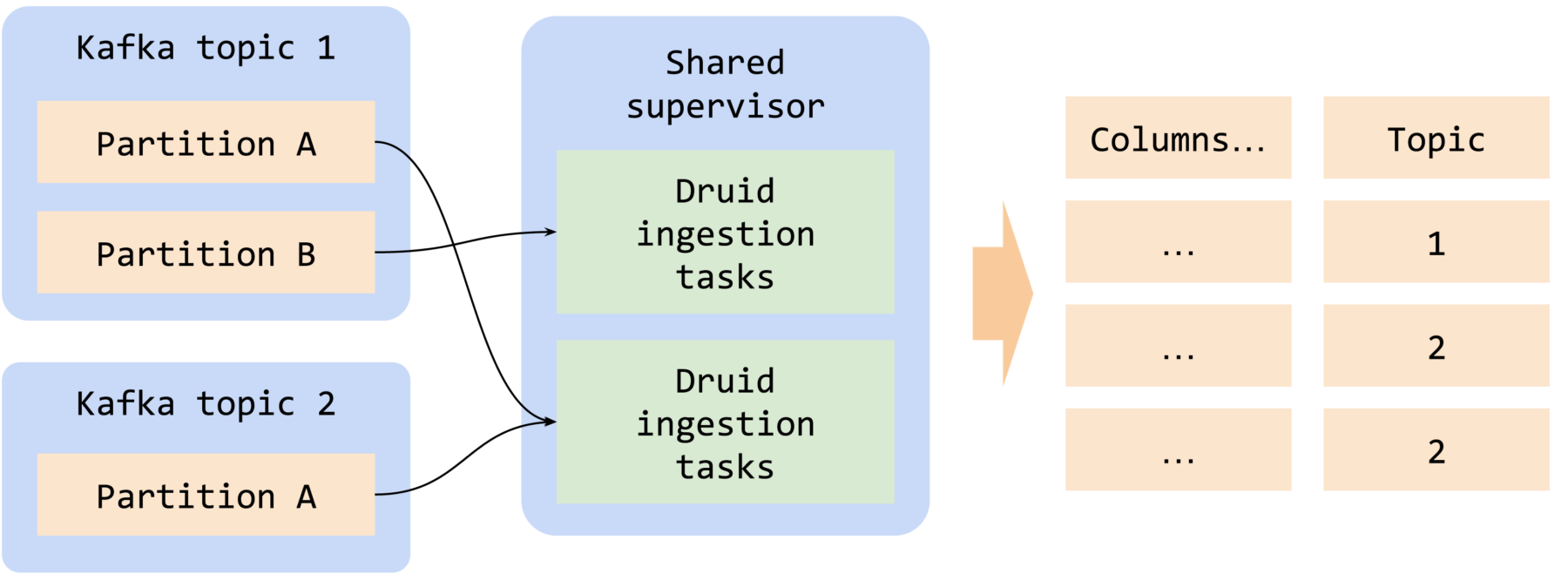
Project contributors recognize that Kafka topics might only have a few messages an hour. Rather than maintaining dedicated resources in Druid to consume from these low-traffic topics or accept higher ingestion latency to spin up tasks on demand, Druid 28 enables you to use the same ingestion task to process data from multiple Kafka topics. It’s implemented in a very flexible way. Instead of specifying topic names, you specify a regular expression that matches potential topics, with the task resource evenly distributed across all matching topics.
To help you identify the source topic, you can ingest the Kafka topic’s name into a column in the destination datasource.
This feature also allows self-service onboarding of new Kafka topics. Combined with schema auto-discovery on ingestion, you can set up an ingestion system that allows anyone to onboard data into Druid without having to create new ingestion jobs or data sources. All you need to do is ask your users to send data into Kafka topics that match a certain format string, and new data becomes queryable automatically.
Multi-topic Kafka ingestion has also been available in Imply Polaris since October 2023.
UNION ALL with MSQ support
At times, you might want to query across multiple data sources or even merge them together and put the merged results into a new table. This is where UNION ALL support comes in. In this release, you can use simple queries like the following to combine data sources.
SELECT * FROM datasource_1
UNION ALL
SELECT * FROM datasource_2
Window function improvements (Experimental)
The Druid project members have substantially improved SQL window functions. In Druid 28.0, you’ll find not only the baseline OVER…ORDER BY operation, but also functions like LEAD(), LAG() to RANK(), as well as doing a cumulative sum. Look out for further improvements to these functions, in both the test passing rate and in test coverage, as this feature begins to graduate from experimental over the coming releases.
Concurrent append and replace (Experimental)
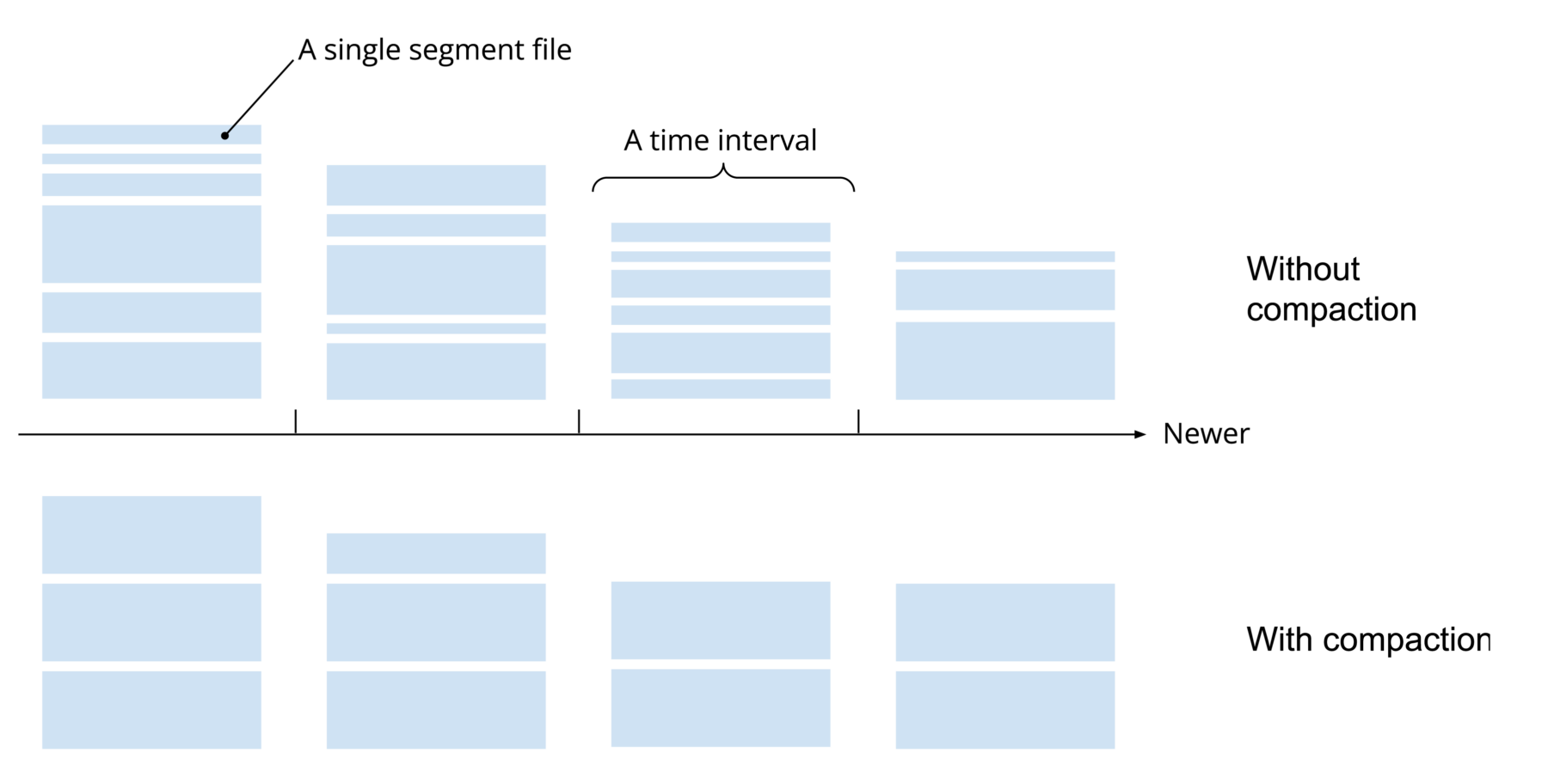
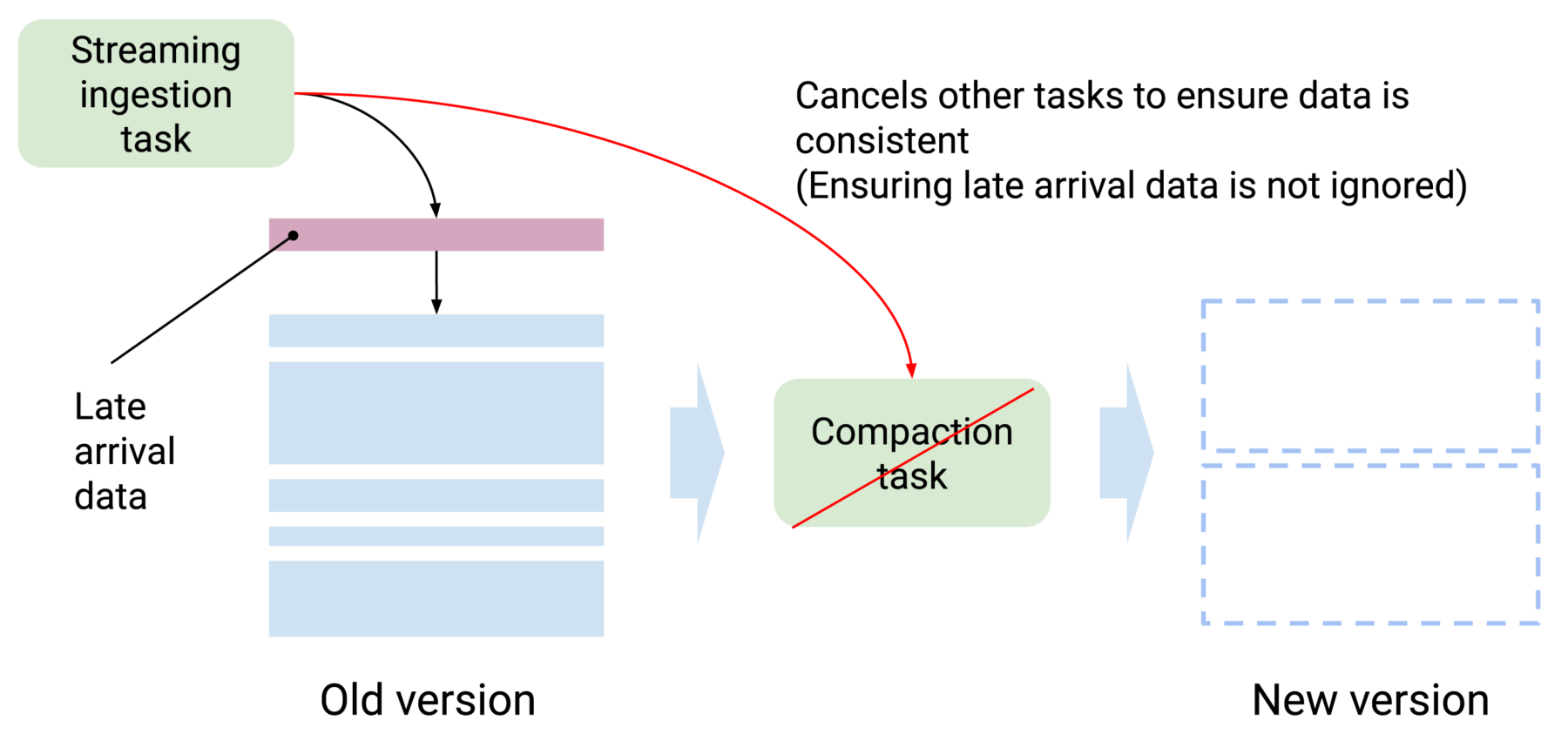
A highly fragmented cluster is not only slow on the query side but also hard to operate and maintain due to the high number of segments the system needs to keep track of.
You may be familiar with using compaction to reduce fragmentation and to optimize data layout. A core of contributors have been working hard to introduce an exciting new experimental feature: concurrent compaction.
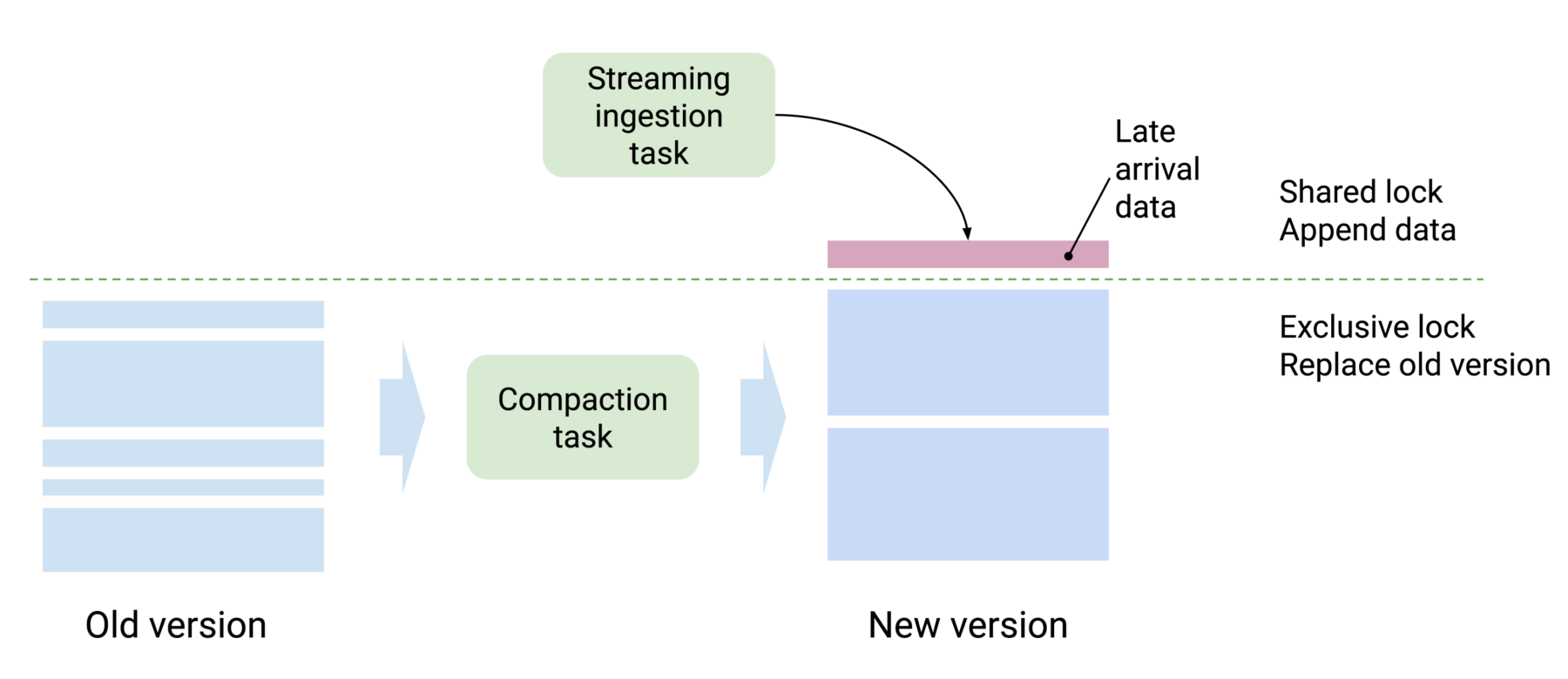
Compaction tasks are often used to re-partition or merge data into optimal shapes for better query performance. Prior to 28.0, Druid tasks could not share a lock on a time interval. When a streaming ingestion task tries adding more data to a time interval, for example, Druid will stop any compaction task that operates on the same time interval. When you have late arrival data that keeps coming, it will result in compaction tasks that never finish.
In this release, Druid gains two new lock types – append and replace. Those two lock types can work in conjunction. A compaction task would use an exclusive replace lock to replace segments with less fragmented versions. Meanwhile, the streaming ingestion task can keep appending new data with a sharable append lock.
We will be continuing to mature this feature over the next few releases, with a goal to turn on auto-compaction by default for all data sources without the need for operators to do this manually.
ANSI SQL support improvements
Druid uses Apache Calcite library as the SQL query planning layer. Calcite has been upgraded to 1.35, providing many desired bug fixes on query planning and correctness. The upgrade may, however, introduce unintended behavior when running queries. Given this is a core library, there is no option to feature flag or turn the behavior changes off due to the Calcite upgrade.
Ensure you pay close attention to query failures post-upgrade to Druid 28.
Druid 28 also enables NULL support, strict boolean logic, and three-valued logic by default, bringing Druid closer in line with ANSI SQL standard behaviors. Those three changes have their own feature flags. While we strongly encourage you to keep them on by default, you can temporarily switch to the older behavior to give you a longer timeline for transition.
Try this out today!
For a full list of all new functionality in Druid 28.0.0, head over to the Apache Druid download page and check out the release notes.
Alternatively, you can sign up for Imply Polaris, Imply’s SaaS offering that includes all of Druid 28 capabilities and a lot more.
Stay Connected
Are you new to Druid? Check out the Druid quickstart and head to our new Developer Center, which contains a lot of useful resources.
Try out these functions and more through Python notebooks in the Imply learn-druid Github repo.
Check out our blogs, videos, and podcasts!
Join the Druid community on Slack to keep up with the latest news and releases, chat with other Druid users, and get answers to your real-time analytics database questions.