Query from deep storage: Introducing a new performance tier in Apache Druid
Dec 15, 2023
Julia Brouillette
In the realm of building real-time analytics applications, data teams often face a familiar challenge: the need to still retain extensive historical data, from months to even years, for occasional but valuable analytics. While the bulk of queries need to be very fast on a smaller, fresher dataset, the ability to query this older data still serves purposes such as long-term trend analysis and report generation.
In the past, Druid users would have to load all the data they ingested onto Druid’s data nodes, to ensure sub-second query performance. This meant a potentially large memory and local storage requirement to retain historical data, even if you don’t often have to query all of that data as it ages.
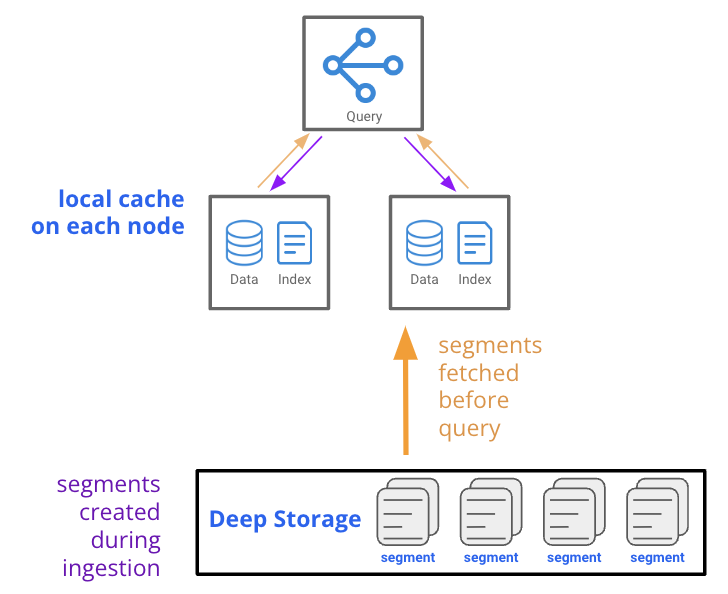
Fig. 1: In the standard Druid architecture, each segment has copies on data nodes managed by a Historicals process, with a duplicate in Druid’s deep storage layer.
To avoid the expense of having aged data on these nodes, Druid users would often dual-load their data onto two different systems—Druid (for the fast, interactive queries) and a data lake or data warehouse (for the infrequently queried, aged data)—as the lower-performance architecture of a data lake or warehouse enabled less expensive storage for infrequent, non-performance-sensitive queries.
What’s interesting to note is that Druid has always had a deep storage layer in its architecture, as illustrated in the diagram above (figure 1). The deep storage layer wasn’t initially intended for queries—it had a different purpose. This layer is used to facilitate easy scalability and data durability. However, the use of deep storage has now expanded with the release of Druid 28.0.
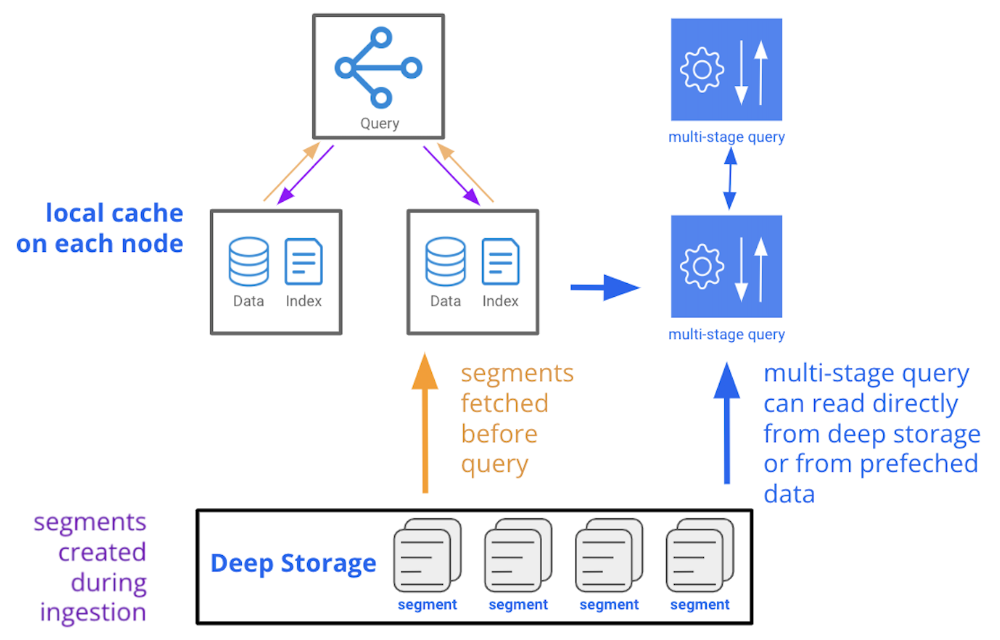
Now, Druid offers a simpler, cost-effective solution with its new feature, Query from Deep Storage. This feature enables you to query Druid’s deep storage layer directly without having to preload all of your data onto Druid’s data servers. This means only fresh data (or whatever is needed for real-time queries) is kept in memory or local storage, keeping old, infrequently accessed data in deep storage. Since object storage comes with higher latency, deep storage queries can be run asynchronously, so they don’t impact the latency of real-time queries.
Fig. 2: Druid can now query directly from deep storage, balancing performance and cost without keeping copies on data nodes.
This capability represents a significant evolution in the role of deep storage within Druid, allowing organizations to keep historical and real-time data efficiently in one system while optimizing the price-performance ratio.
Druid’s Query from Deep Storage offers several key benefits:
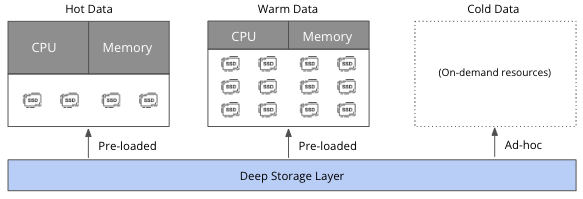
Optimal price-performance ratio: With Druid’s Query from Deep Storage capability, users can size their clusters for real-time analytics while using additional compute resources on demand for querying historical data. Historically, data in Druid is typically cached on local storage drives as data is ingested, processed, and loaded in memory.
The ability to query from deep storage (common deep storage formats are cloud object storage or HDFS) eliminates the need for high-performance storage and compute resources for infrequent access to large datasets. This makes Druid more elastic, offering users the ability to scale resources up or down based on usage while only paying for what’s being used.
Simplified data architecture: On-demand querying from deep storage broadens the scope of data available for querying without the need to scale your Historical processes in Druid or manage a separate system (like Presto or another data lake or data warehouse) for historical analysis. For example, an e-commerce platform using Druid for real-time customer behavior and transaction data analytics can also perform complex queries on two-year-old data to analyze past purchasing trends, seasonal variations, and long-term customer behavior. This more infrequently accessed data in deep storage becomes readily available for analysis, all in one system, without requiring a sustained increase in infrastructure resources.
Keeping all data within a single system also provides a higher level of reporting consistency. Modern data systems use approximation and statistical algorithms to ensure performance at scale. Unique values calculated in one system will be different from those calculated in another system. So in addition to simplifying data architecture, Druid’s ability to handle real-time and non-real-time workloads lends itself to more consistency in reporting.
Druid’s querying from deep storage feature makes it a valuable add-on to real-time analytics applications. Let’s explore a few examples:
Cost-effective ad-hoc analysis
The ability to enable on-demand ad-hoc analysis is a powerful feature for analysts using Druid. This functionality allows users to query data beyond the retention period of the real-time Druid cluster, providing a cost-effective solution for in-depth exploration of historical data, albeit with higher latency.
In Druid deployments of the past, the amount of historical data in the cluster was limited by data storage costs. Analysts seeking to dive into historical data beyond this period would encounter limitations, necessitating workarounds like age data to a data lake for ad-hoc historical querying.
With the introduction of Druid’s Query from Deep Storage capability, users can seamlessly extend their historical analysis beyond the real-time cluster’s retention period. While this approach incurs higher latency (compared to Druid’s typical subsecond query performance) due to data retrieval from deep storage, its cost-effectiveness makes it an attractive alternative. Developers and analysts can now engage in on-demand historical analysis without workarounds, simplifying the process and making it easier to perform historical data exploration.
Exports and downloads
Druid now empowers developers to integrate export and download features into their applications, allowing users to access and download large datasets or reports generated from historical data, providing them with valuable insights and a deeper understanding of trends, patterns, and historical performance.
In the past, exporting and downloading substantial datasets or reports from Druid could be challenging. This could lead to increased resource usage as the system loads data into memory for export, impacting real-time query latency. Large export queries could time out and fail to complete.
Druid’s Query from Deep Storage capability enables the efficient and cost-effective retrieval of large datasets or reports, ensuring users experience a smoother process without the potential costs and impact on real-time performance. Now it’s easy to export data of any size, for archives, migration (such as between open source Druid and Imply Polaris, a Database-as-a-Service based on Druid), or any other reason.
Complex reporting
Druid excels at powering real-time analytics applications, but sometimes, users need to run resource-intensive queries for in-depth reporting, such as those involving large complex joins. Recently added support for query-time Broadcast Joins and Shuffle Joins makes these complex queries possible, accommodating diverse data needs. The ability to perform large joins at both ingestion and query time provides flexibility, particularly for existing schemas and self-joins. Moreover, the introduction of Shuffle Joins at ingestion time eliminates reliance on external tools for data preparation, making the architecture simpler and more suitable for a range of real-time and non-real-time use cases.
Druid’s join capabilities, combined with Query from Deep Storage, enable seamless integration of large datasets, providing a more efficient and cost-effective solution for handling complex analytical tasks alongside real-time analytics.
The expanded role of deep storage in Druid
With the development of Druid’s Multi-Stage Query (MSQ) engine, Druid’s historical analysis capabilities have expanded significantly with the ability to query directly from deep storage. It simplifies the data architecture by eliminating the need to sustain large amounts of local storage to accommodate ad hoc historical analysis. This expanded role for deep storage opens up new possibilities for complex queries and reporting on historical data, making deep storage not just a reliable backup but also a functional part of the total analytics system.
To summarize, deep storage in Druid serves multiple purposes:
Data redundancy and fault tolerance: The deep storage layer acts as an extra copy of the data, providing redundancy. If the main cluster goes down or faces issues, the data in deep storage can be used to recover and rebuild the cluster.
Cluster scaling: When scaling a Druid cluster by adding or removing nodes, the data movement across nodes can be resource-intensive. Deep storage helps mitigate this by allowing the cluster to maintain historical data on each node, reducing the need for extensive data shuffling during scaling operations.
And now,
Long-running queries: The capabilities of deep storage have been expanded to support long-running, ad hoc queries directly on data stored in deep storage. This is beneficial for more complex analytical workloads that require access to historical data over a longer period.
Join the Druid Community
We are on a mission to help you—developers, engineers, architects, and builders—become the new analytics heroes!
New to Druid? Check out our Developer Center, where you can learn all things Druid with articles, lessons, how-to tutorials, and design recipes. You can also join the Druid community on Slack to keep up with the latest news and releases, chat with other Druid users, and get answers to your real-time analytics database questions.
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...