Oct 22, 2024
Introducing Apache Druid® 31.0
We are excited to announce the release of Apache Druid 31.0. This release contains over 525 commits from 45 contributors.
Learn MoreDo you want fast analytics, with subsecond queries, high concurrency, and combination of streams and batch data? If so, you want real-time analytics, and you probably want to consider the two Apache Software Foundation projects for open source real-time analytics: Apache Druid and Apache Pinot.
Here’s a quick guide to choosing between these two database options:
Druid may be a better choice if you:

Pinot may be a better choice if you:
If you’d like to learn more about why each database works the way it does, read on!
When you need insights and decisions on events happening now, you need real-time analytics.
Analytics is a set of tools to drive insights to make better decisions. Sometimes this is providing useful information to humans, using dashboards, charts, and other reports to enable better decisions. Sometimes this is providing actionable information to machines, making automated decisions.
Some analytics are not very time-sensitive, such as daily or weekly reports. Data warehouses and data lakes are designed to deliver these reports.
Real-time analytics features fast queries, usually under 1000ms, with aggregates and rollups while maintaining access to the granular data. It includes fast ingestion of both stream and batch data, and works at any scale, from GBs to PBs. It combines queries on current streams with historical batch data, providing insights in context. It supports high concurrency, with hundreds or thousands of concurrent queries, It is always on, with near-zero downtime (zero planned downtime) and continuous backup.
Both Apache Druid and Apache Pinot are databases designed for real-time analytics.
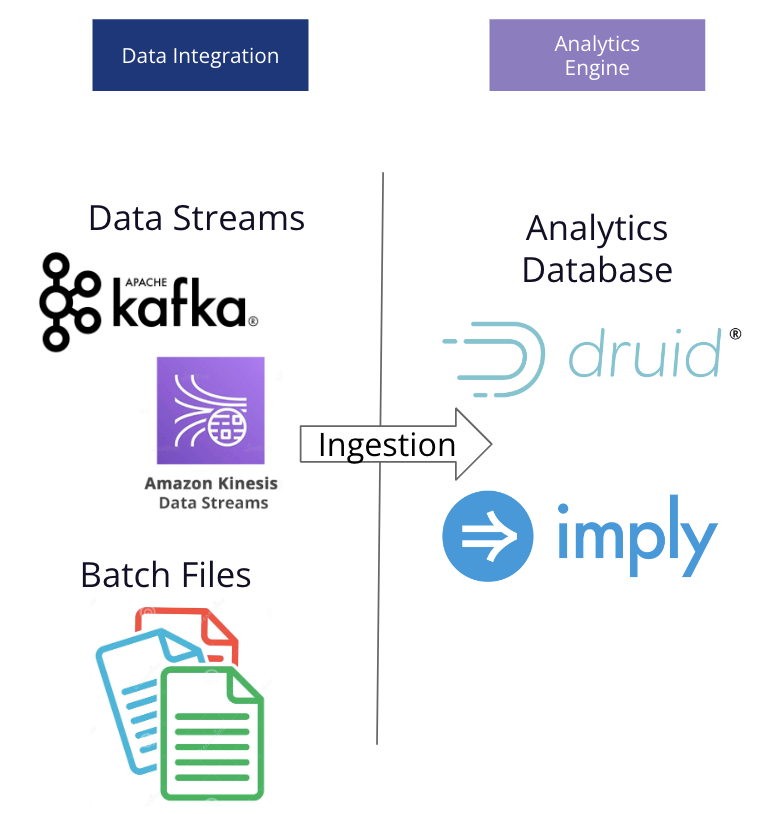
Druid has an elastic and distributed architecture to build any application at any scale, enabled by a unique storage-compute design with independent services.
During ingestion, data are split into segments, stored by column, fully indexed, and optionally pre-aggregated. This enables unique value over other analytics databases which force a choice between the performance of tightly-coupled compute and storage or the scalability of loosely-coupled compute and storage. Druid gets both performance and cost advantages by storing the segments on cloud storage and also pre-fetching them so they are ready when requested by the query engine.
Each service in Druid can scale independently of other services. Data nodes, which contain pre-fetched, indexed, segmented data, can be dynamically added or removed as data quantities change, while Query nodes, which manage queries against streams and historical data, can be dynamically added or removed as the number and shape of queries changes.
A small Druid cluster can run on a single computer, while large clusters span thousands of servers, and are able to ingest multiple millions of stream events per second while querying billions of rows, usually in under one second.
Performance is the key to interactivity. In Druid, “if it’s not needed don’t do it” is the key to performance. It means minimizing the work the cluster has to do.

Druid doesn’t load data from disk to memory, or from memory to CPU, when it isn’t needed for a query. It doesn’t decode data when it can operate directly on encoded data. It doesn’t read the full dataset when it can read a smaller index. It doesn’t start up new processes for each query when it can use a long-running process. It doesn’t send data unnecessarily across process boundaries or from server to server.
Druid is self-healing, self-balancing, and fault-tolerant. It is designed to run continuously without planned downtime for any reason, even for configuration changes and software updates. It is also durable, and will not lose data, even in the event of major systems failures.
Whenever needed, you can add servers to scale out or remove servers to scale down. The Druid cluster rebalances itself automatically in the background without any downtime. When a Druid server fails, the system automatically understands the failure and continues to operate.
As part of ingestion, Druid safely stores a copy of the data segment in deep storage, creating an automated, continuous additional copy of the data in cloud storage or HDFS. It both makes the segment immediately available for queries and creates a replica of each data segment. You can always recover data from deep storage even in the unlikely case that all Druid servers fail. For a limited failure that affects only a few Druid servers, automatic rebalancing ensures that queries are still possible and data is still available during system recoveries. When using cloud storage, such as Amazon S3, durability is 99.999999999% or greater per year (or a loss of no more than 1 record per 100 billion).
Druid is deployed in a cluster of one or more servers that run multiple processes:
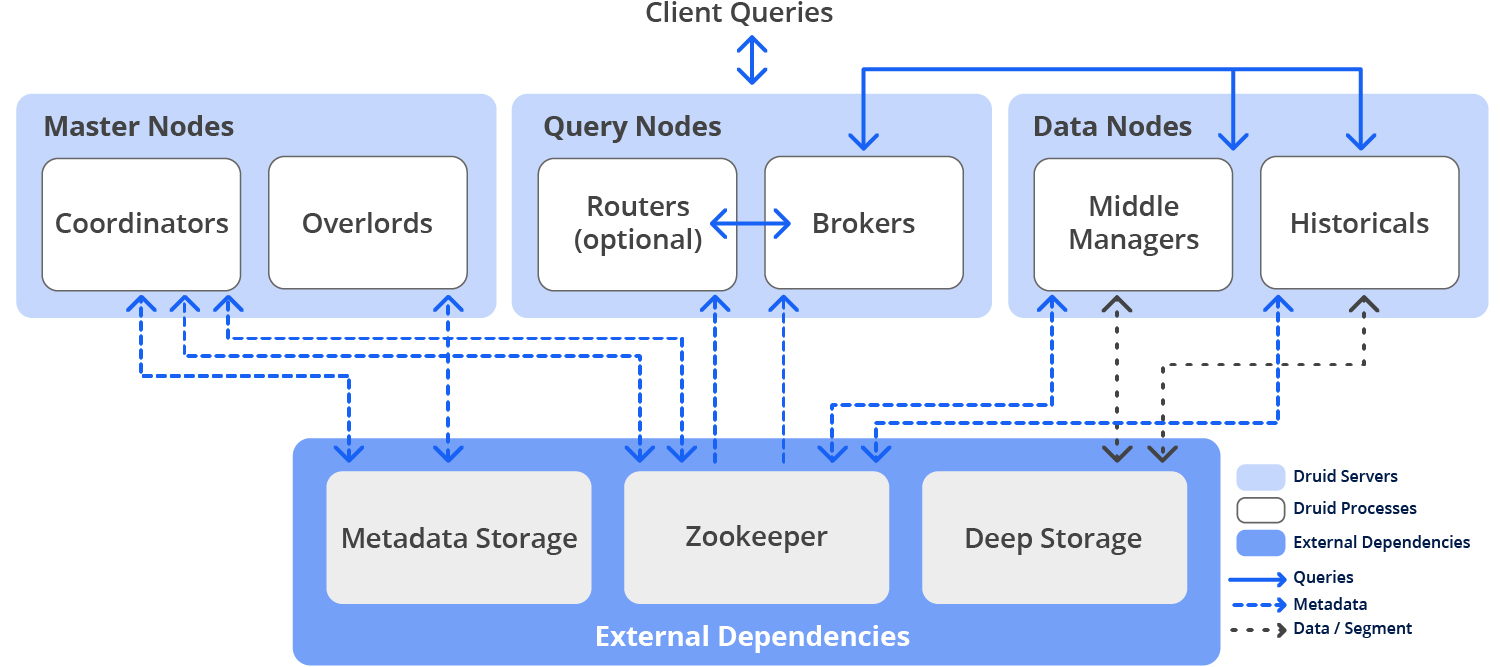
Usually, Druid processes are deployed on three types of server nodes:
In a small configuration, all of these nodes can run together on a single server. For larger deployments, one or more servers are dedicated to each node type.
Much of Druid’s ability to provide high performance and high concurrency while also being cost-efficient and resilient is enabled by a unique relationship between storage and compute, blending the “separate” and “local” approaches used by other databases.
Local storage uses high-speed disk, or other persistent storage technologies, like solid-state drives, to keep all data quickly available for queries. This is the design used by most transactional databases, such as Oracle, SQL Server, Db2, MySQL, and PostgreSQL. It provides good query performance, but it can be expensive, and very expensive for the large datasets common in analytics. Fortunately, Druid can provide the advantages of local storage without high expenses.
Many data warehouses use separate storage, where all ingested data resides on a remote storage system. On the cloud, that’s an object storage service, such as Amazon S3 or Azure Blob. On-premise, that’s a distributed storage system like HDFS. Databases with separate storage query data directly from that remote storage, potentially with some caching. This allows compute capacity to be bursted up and down quickly, which is great for infrequently-accessed data or irregular query load.
But there is a downside to the separate storage approach: these systems don’t perform as well as systems that store data locally on data servers. This doesn’t work well for high-performance application-oriented use cases: the system performs well when the cache is warmed up, but performance on cold cache is poor.
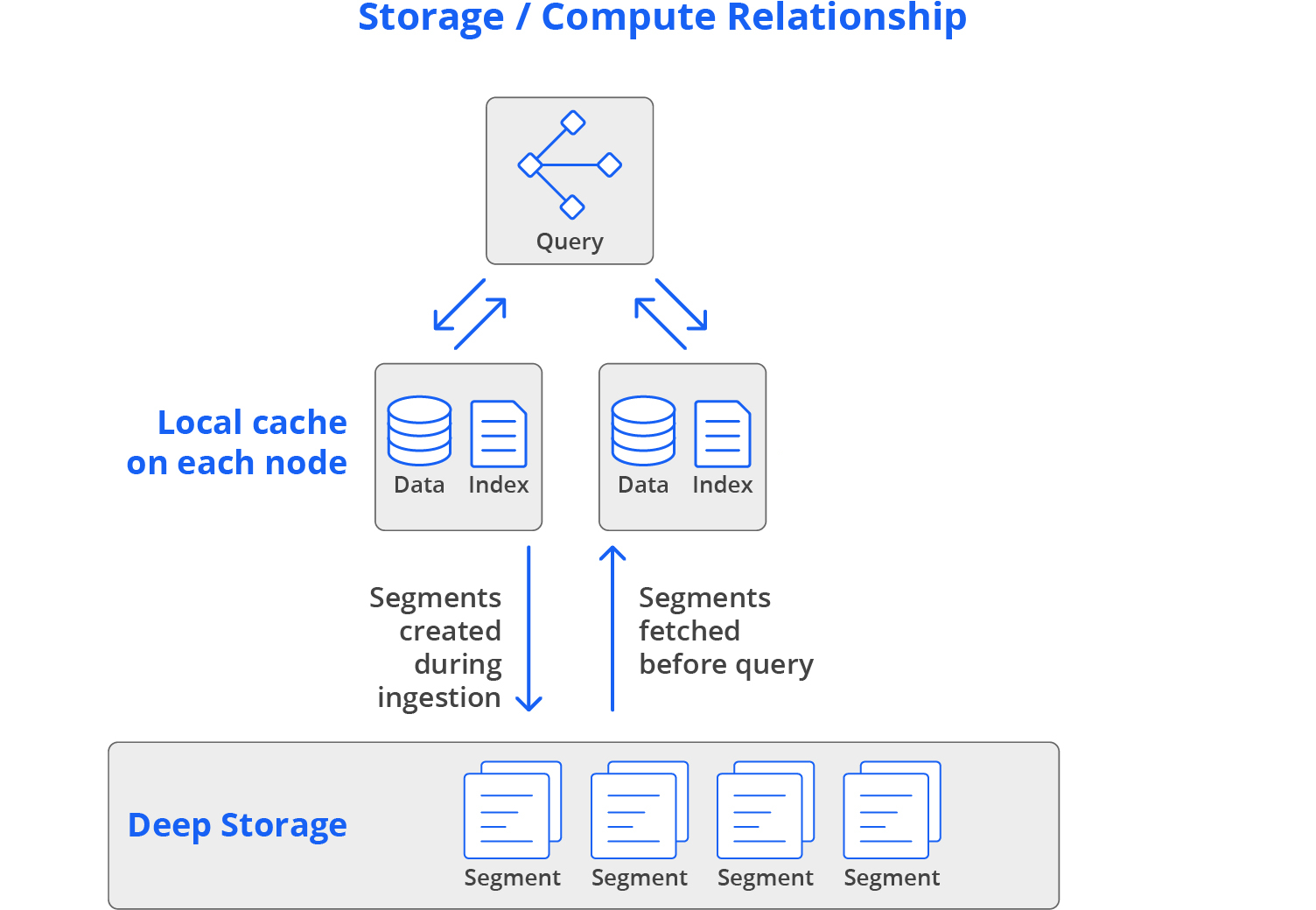
Druid blends the “separate” and “local” approaches. It uses separate storage, labeled “deep storage”, as a common data store. This makes it easy to scale Druid up and down: simply launch or terminate servers, and Druid rebalances which segments are assigned to which servers. Meanwhile, Druid also preloads all data into local caches before queries hit the cluster, which guarantees high performance; there is never a need to load data over the network during a query.
In the vast majority of cases, data will already be cached in memory. And even if it isn’t, it will be available on the local disk of at least two data servers. This design gives Druid the elasticity, resilience, and cost profile of separate storage, with the high performance profile of local storage.
To reduce costs for less-frequently accessed data, Druid can query directly from deep storage, avoiding the need to keep segments pre-fetched into data nodes. It’s a common model to keep recent data in high-speed segments on data nodes, with older data only in deep storage. Druid automatically manages the placement of data based on rules (such as “store data older than 90 days on deep storage only”).
In deployment, Druid is part a pipeline that ingests data from multiple sources and powers analytics applications, visualization, and data exploration.
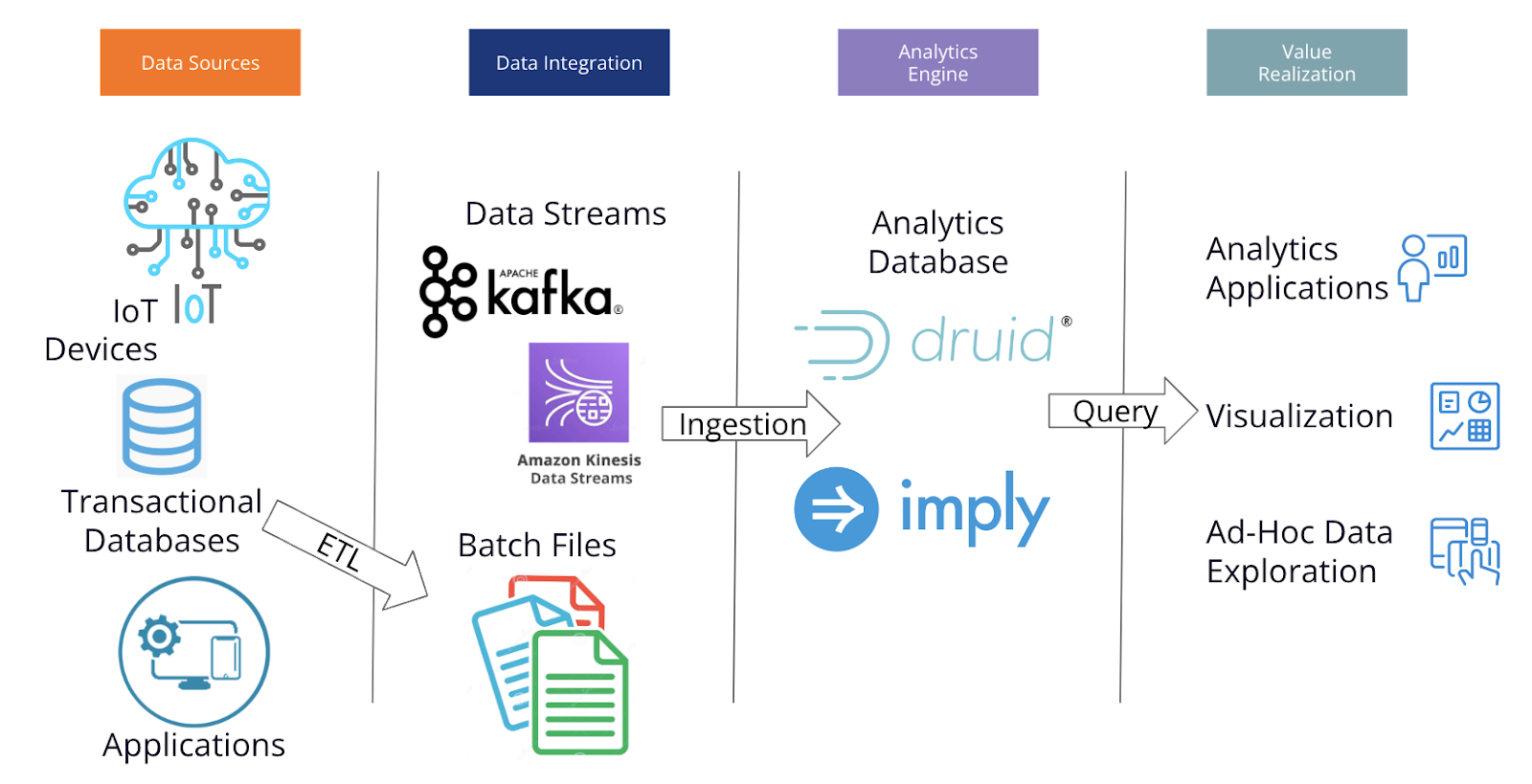
The design of Druid enables high performance at high concurrency by avoiding unneeded work. Pre-aggregated, sorted data avoids moving data across process boundaries or across servers and avoids processing data that isn’t needed for a query. Long-running processes avoid the need to start new processes for each query. Using indexes avoids costly reading of the full dataset for each query. Acting directly on encoded, compressed data avoids the need to uncompress and decode. Using only the minimum data needed to answer each query avoids moving data from disk to memory and from memory to CPU.
Druid is open source, and can be downloaded and installed from druid.apache.org – or read the blog, “Wow, That was easy”. You can also get commercial support and fully-managed Database-as-a-Service from Imply and others.
Pinot was developed by a team at LinkedIn, an organization that was already using Druid, so they were able to create a solution that has many similar elements.
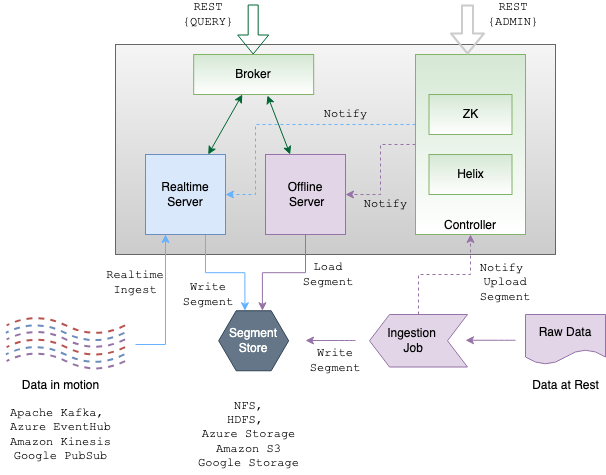
Just like Druid, Pinot splits incoming data into segments, which use columnar storage in both high-speed java processes and durable object storage (here called “Segment Store”). Pinot uses different processes for incoming streams (“Realtime Server”) and incoming batch data (“Offline Server”).
One way they are different is ingestion and indexing. In Druid, the schema of incoming data is automatically detected, then each field is automatically indexed using the best technology for the data type (bitwise indexes for integers, dictionary encoding for strings, and so forth). In Pinot, a human must define the schema manually for incoming data, then choose an index for each column. Pinot includes 13 different indexes, each designed for different data types and uses.
Pinot is open source, and can be downloaded and installed from pinot.apache.org. You can also get commercial support and fully-managed Database-as-a-Service from StarTree.
Druid and Pinot are far more alike than different. There are a few key differences worth considering.
Both databases are developed and used for real-time analytics of batch and streaming data. Both offer high query performance and low query latency, data aggregation, data storage across clusters of nodes,with partitioning and replication, and support for dashboards and other visualization. The key differences are indexing, ingestion, mixed workloads, and maturity.
 | ||
| Indexing | Auto-index applies the best index to each column | User must choose and manage indexes for each column |
| Ingestion | SQL or JSON spec. Can JOIN, rollup, and transform data as part of ingestion | JSON spec only. Transformation requires additional tooling (such as Trino) |
| Mixed Workloads | Query laning and service tiering to assign resources to queries based on priority. | All queries are in one pool, so can only assign priority by creating multiple Pinot clusters |
| Maturity | Over 2,000 known production deployments | Breadth of use unclear, probably around 200 |
Druid auto-indexes all data, automatically applying the best index for each column’s data type, such as text strings, complex JSON, and numeric values. High-efficiency bitmap indexes, inverse indexes, and dictionary encoding indexes are created and applied to maximize the speed of every query. There is no need to manage indexes in Druid.
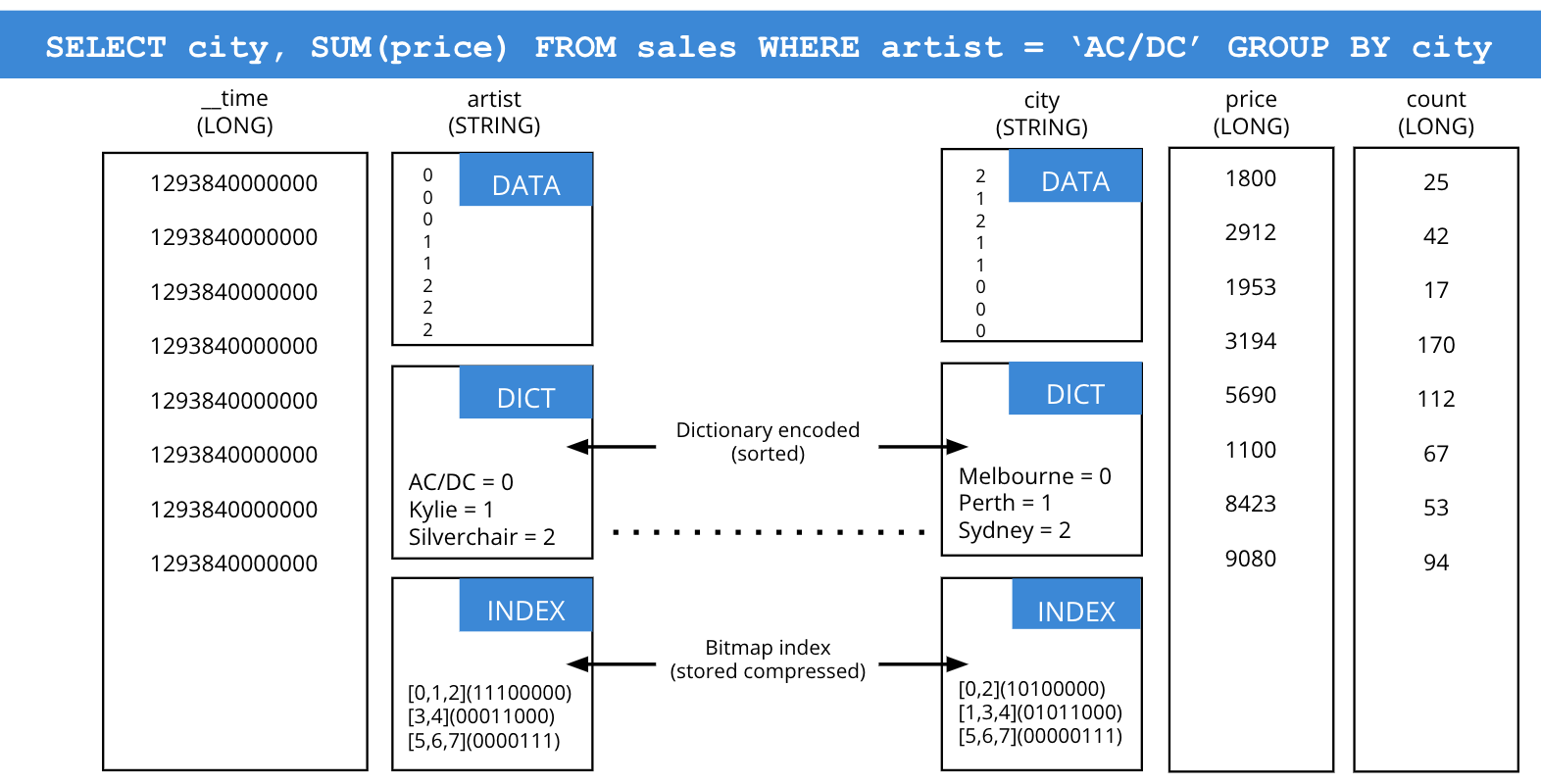
Indexing in Druid: automatic for each column and tightly integrated with the query engine.
Pinot supports at least 13 different indexes, so Pinot users must manage the indexing strategy for each column of each table. Some of these indexes promise improved performance for some use cases (one of these, the star-tree index, was chosen as the name of a commercial firm supporting Pinot).

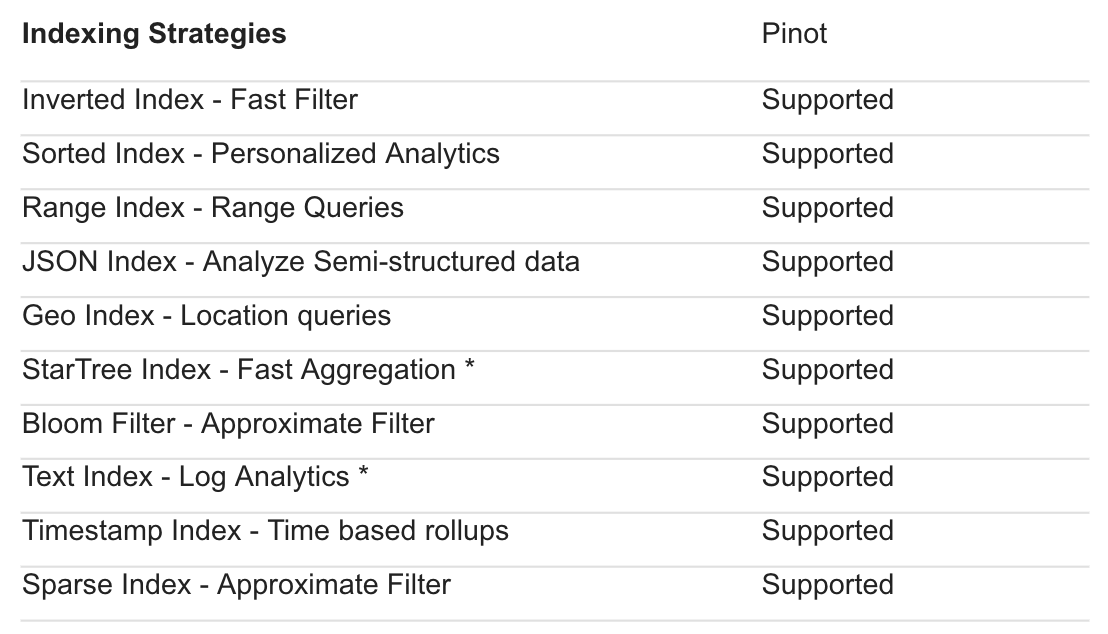
Indexing in Pinot: select an index for each column; duplicate columns if different indexes needed.
There have not been published benchmarks demonstrating performance differences between Druid auto-indexing and Pinot manually-managed indexes. Experiences where organizations have compared both systems have found some small performance advantages for each system, depending upon the use cases.
Both Druid and Pinot can ingest both batch data and streaming data.
In Druid, batch data can be ingested using either SQL commands or a JSON ingestion spec. During ingestion, different data sources can use SQL for transformation, using JOINs, rollups, and other SQL techniques.

Ingestion in Druid: SQL-based, with ability to use SQL to JOIN, UNNEST, and otherwise transform data as part of the process



Ingestion in Pinot: JSON specification only, with no ability to transform the data. Usually needs another system (Presto, Spark, or others) to prepare data before ingestion.
Pinot batch ingestion can only be performed using a JSON ingestion spec. Any data joining or other transformation must be executed by other tools, such as Hadoop Map-Reduce, before ingestion.
Both databases support stream ingestion from Apache Kafka (and Kafka-compatible APIs) and Amazon Kinesis. In Druid, incoming events are immediately placed into memory for immediate availability, using the same standard table structure as data ingested from past streams or batch ingestions. After an interval, this data is processed into segments for long-term availability. The same infrastructure can be used for batch ingestion, stream ingestion, and query processing.
In Pinot, special “real-time” tables must be created with dedicated infrastructure for stream ingestion, which is distinct from the infrastructure needed for batch ingestion, while yet more infrastructure is needed for query processing. After an interval, these real-time tables are flushed into Helix-managed segments and combined with data from the past.
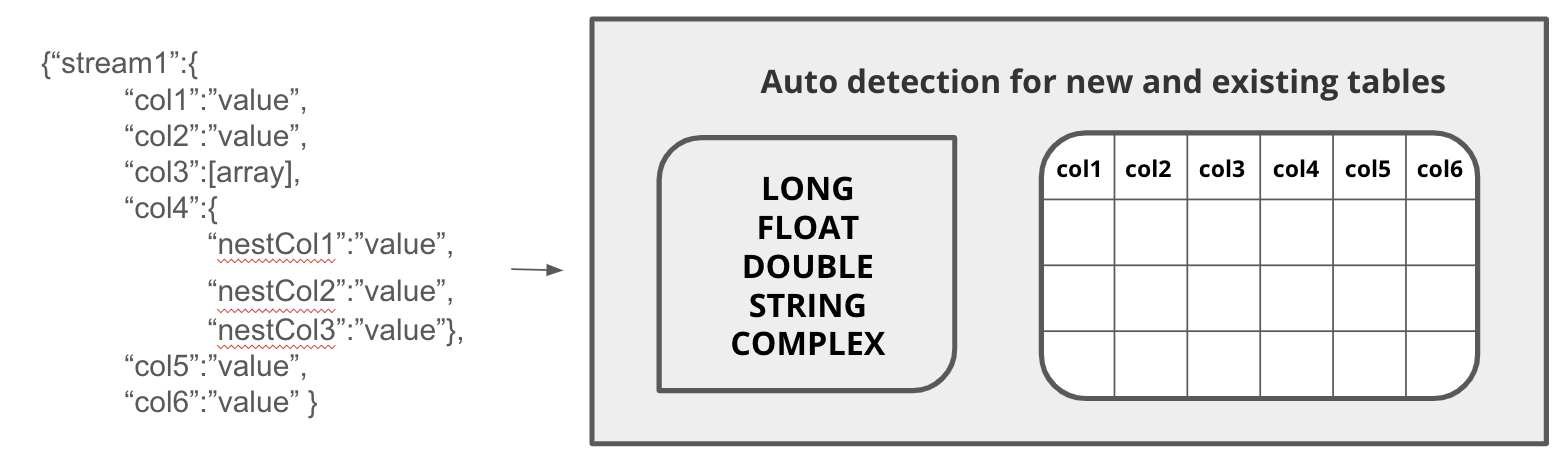
Schema auto-discovery in Druid, identifying each column and changing, if needed, as future data ingesting has a different shape. In Pinot, all columns must be explicitly typed and manually adjusted.
In addition, Druid (but not Pinot) offers schema auto-discovery, where column names and data types can be automatically discovered and converted into tables without requiring explicit definition. This enables easier ingestion for wide data sets and can automatically adjust table schemas when data sources change.
Sometimes, you need to manage a mix of different requirements, with some high-priority queries that need the top performance mixed with lower-priority queries that don’t need to be as fast.
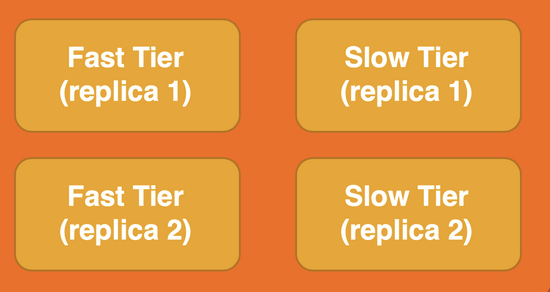
Query laning in Druid. Pinot lacks this capability.
Druid includes Query Laning, where any number of tiers can be created to separate queries with different priorities or any other reason for separation (such as segregating workloads from different business units). This ensures that, no matter how many lower-priority queries are being submitted, the high-priority queries always get the resources needed.
Druid also includes Query from Deep Storage, which provides a low-cost, lower-performance option (sometimes called a “Cold Tier”) for older and infrequently used data.
Pinot lacks the ability to segregate workloads by priority. (There is a cold tier option in the commercial StarTree Cloud service, but this is not supported by Apache Pinot).
First announced and released as open source in 2011, Druid is in use by over 1900 organizations. The Druid community, with Slack and Forum support, has thousands of active participants, while the Druid project management committee includes over 40 committers from 20 different global organizations.
In 2015, the creators of Druid founded Imply, which provides distribution, support, and Druid-as-a-Service. Imply is privately held; its most recent funding round raised investment to over $215 million and valued the company at $1.1 billion. Imply has been chosen by many global organizations to power real-time analytics, including Walmart, Salesforce, NYSE (Intercontinental Exchange), Splunk, Atlassian, Cisco, Citrix, TrueCar, PayTM, and Amazon Twitch. Many more, including Target Stores, Ancestry.com, Wikimedia Foundation, and Confluent use open source Apache Druid.
Pinot is a more recent entrant, released to open source in 2015. Initially developed at LinkedIn and Uber, the creators followed a similar path to Imply to create Startree in 2018. Also privately held, Startree has raised investments of $75m. The largest public reference customers using Startree appear to be Guitar Center and JustEat, though there are others using open source Apache Pinot, notably Uber Eats, and Stripe, Interestingly, LinkedIn uses both Druid and Pinot..
If your project needs a real-time analytics database that provides subsecond performance at scale, high concurrency, or combining real-time streams with historical data, you should consider both Apache Druid and Apache Pinot.
The easiest way to evaluate Druid is Imply Polaris, a fully-managed database-as-a-service from Imply. You can get started with a free trial – no credit card required! Or, take Polaris for a test drive and experience firsthand how easy it is to build your next analytics application.
Introducing Apache Druid® 31.0
We are excited to announce the release of Apache Druid 31.0. This release contains over 525 commits from 45 contributors.
Learn MoreAn Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreLast Call—and Know Before You Go—For Druid Summit 2024
Druid Summit 2024 is almost here! Learn what to expect—so you can block off your schedule and make the most of this event.
Learn More