Apache Druid 0.23.0 contains over 450 updates from 81 contributors, including new features, significant performance enhancements, bug fixes, and major documentation improvements.
This is the first part of a two-part series that focuses on user-facing functionalities. If you want to learn more about the core engine changes, please see part two.
Visit the Apache Druid download page to download the software and read the full release notes detailing every change. This Druid release is also available with Imply’s commercial distribution of Apache Druid, including Imply Polaris, the cloud database service built for Druid that you can try out for free today.
New capabilities of Druid engine
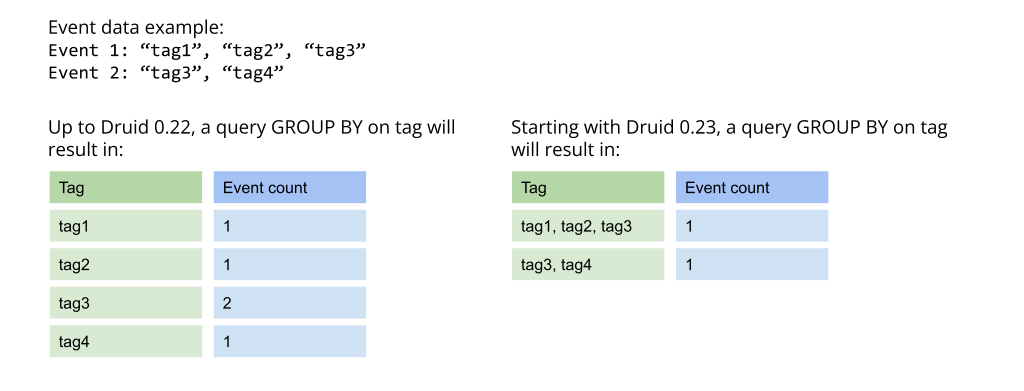
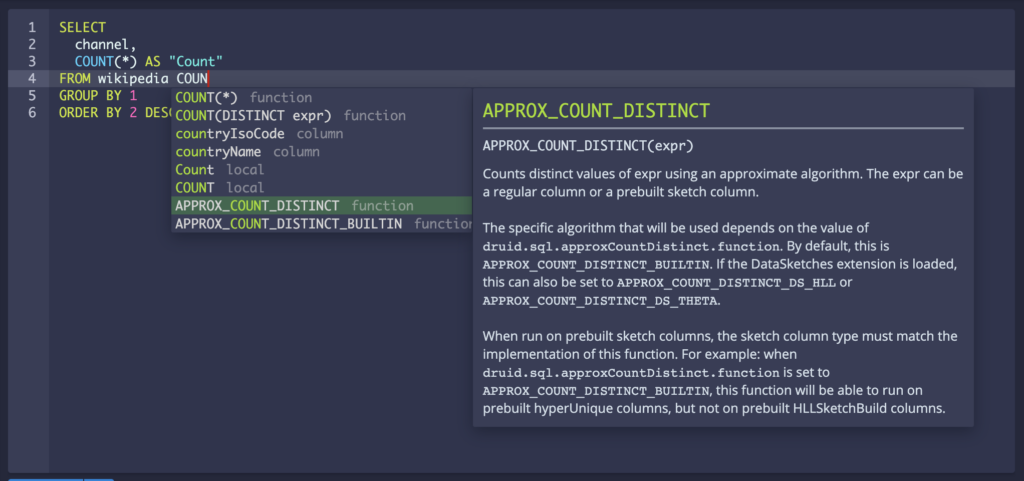
Druid is even better for tag data analysis – GROUP BY on multi-valued dimensions without unnesting
Tags, from social media to IoT sensors, are used everywhere to help label data points.
Druid is an excellent database for analyzing data from such sources. The best way to store tags in Druid is by using multi-valued dimensions.
In the past, GROUP BY queries on multi-valued dimensions resulted in exploded rows. This helped answer questions like “For a given tag, what data points are associated with it?”
But the exploded rows were not helpful when you asked the inverse question – “For a given set of data points, what are the tags associated with them?”
This improvement allows you to answer the latter question and can help you create features such as popular tags.
Example query:
select mv_to_array[tags] , count(*) from data group by 1
As part of the related change, we have also introduced MV_FILTER_ONLY, MV_FILTER_NONE to help make those queries more useful. For example, you can filter for data points that match a specific tag only
select mv_to_array[tags] , count(*) from data WHERE MV_FILTER_ONLY(tags, [‘x’])
You can find detailed documentation about this feature here.
Support additional timestamps in time-series event data
Often, time-series events have multiple timestamps associated with them. For example, an IoT sensor might send events once every minute in small batches, but each event has its own unique timestamp. Sometimes, it’s essential to be able to look at the latest event per batch instead of individual events.
In the previous versions of Druid, the LATEST(column) function only took one parameter and defaulted to using the “__time” column to find the latest value of the column. The new function LATEST_BY(expr, timestampExpr) takes a second parameter where you can supply an alternative timestamp.
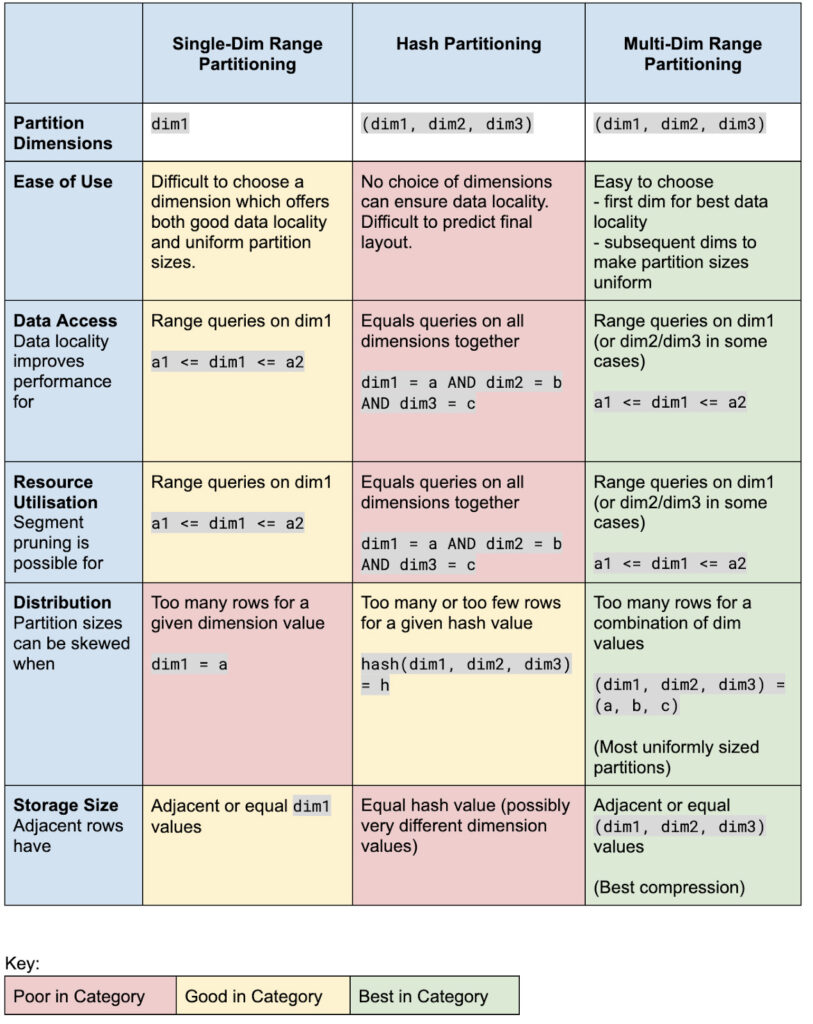
Multi-dimensional partitioning to improve query performance
Previously, Druid supported a few partitioning schemes that could be used to optimize query performance. Each partitioning scheme had its own limitations and tradeoffs. Druid now supports a new type of partitioning scheme – multi-dimensional (multi-dim) partitioning. You can see a comparison matrix below.
This partitioning scheme works well to improve query performance in most scenarios. If your queries are filtering on specific dimensions regularly, this would be a good strategy to try.
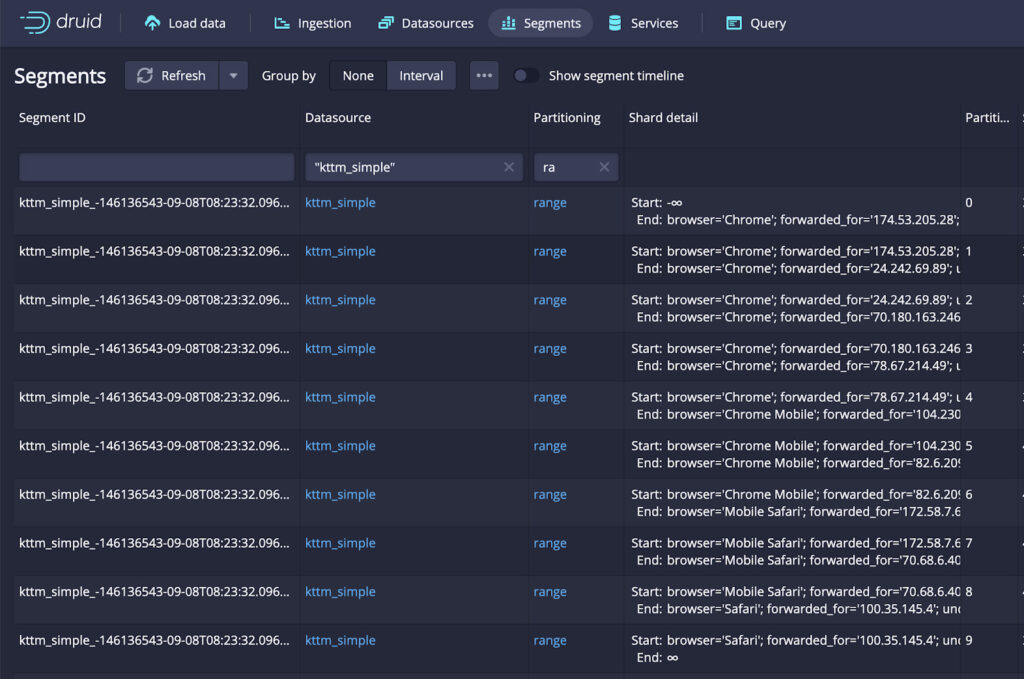
At the same time, we have also added details in the webconsole’s segments details view. As you can see below, the Shard details column now contains how the segments are partitioned and what data are contained within.
If you are looking for some tools to optimize query performance, multi-dim partitioning is definitely worth a try. You can read more about multi-dim partitioning in this blog post.
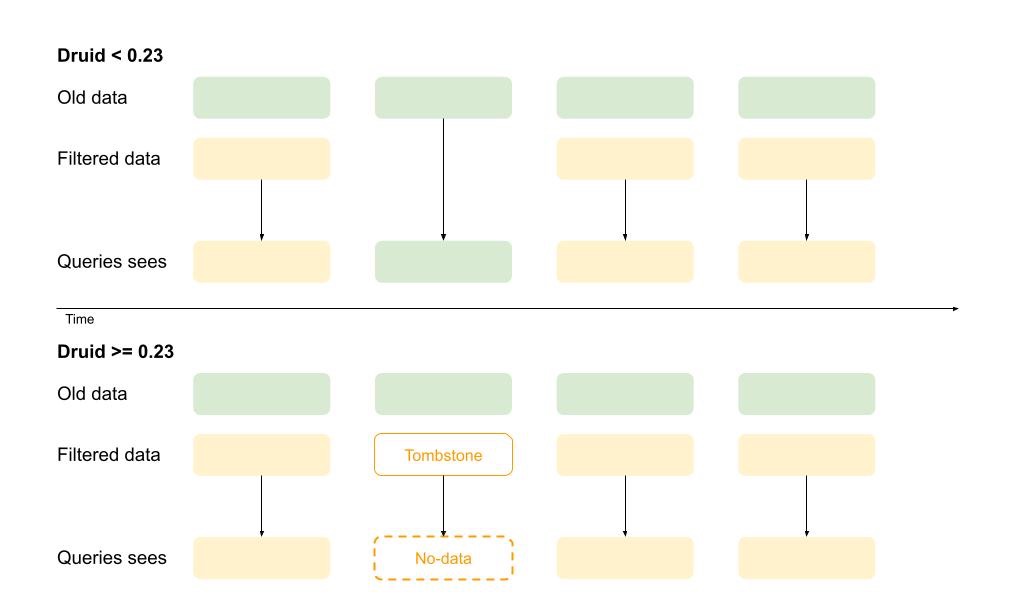
Atomic replacement and filtered deletion
Apache Druid supports data replacement. Druid partitions data by time grain, for example, by day, hour, etc. Before this release, if there was a gap in the new data replacing the old data, the old data would still be visible during querying. In this release, we have addressed this problem by introducing a tombstone. This means the replacement will always be atomic and complete, even if there are gaps in the replacement data.
There is a blog post that provides context and details of this change. You can read about it here.
This effectively allows you to delete data by reindexing your data with filters. While this is different from transactional deletes used in OLTP databases, it enables deletion using batch data reprocessing.
Future work in this area will enable you to use the auto-compaction system to do the filter deletes in the background. With the auto-compaction-based system, you can reduce the cost of storing historical data long-term by doing filter deletion operations on unused data as it ages.
Druid works even better with Kafka
Druid is a popular system for processing Kafka events. In this release, we are making the integration tighter by enhancing Kafka inputFormat. You can now extract not only the content of messages in Kafka, but also native Kafka fields such as:
Kafka event key field
Kafka event headers
Kafka event timestamp
You can learn more about how to configure those here.
Ingesting JSON data easier with extended JsonPath functions
JSONPath library used by Druid to parse JSON data supports many JSON path functions for data processing. They are especially useful when you want to aggregate arrays within JSON before ingesting the array data. In this release, we’ve added support for using JSON path functions during data ingestion. You can see the full list of supported functions here.
Improved SQL error messages
Behind the scenes, Druid uses Apache Calcite™ library for query planning. In the past, the error messages generated by the planner could sometimes be cryptic.
For example, if you tried to issue the following query to Druid:
SELECT dim1 FROM druid.foo ORDER BY dim1
This query would fail because Druid didn’t support order by non-time columns for scan queries.
In prior releases, the error message would read:
“Error: Failed to plan query”
While technically correct, it’s not very helpful.
In this release, the same error reads:
“Possible Error: SQL query requires order by non-time column [dim1 ASC] that is not supported.”
Now, instead of Calcite emitting a generic error when a query cannot be planned, Druid now attempts to emit helpful errors when possible. Please give this a try and let us know your feedback.
At the same time, the webconsole UI has been updated to include more helpful query tips.
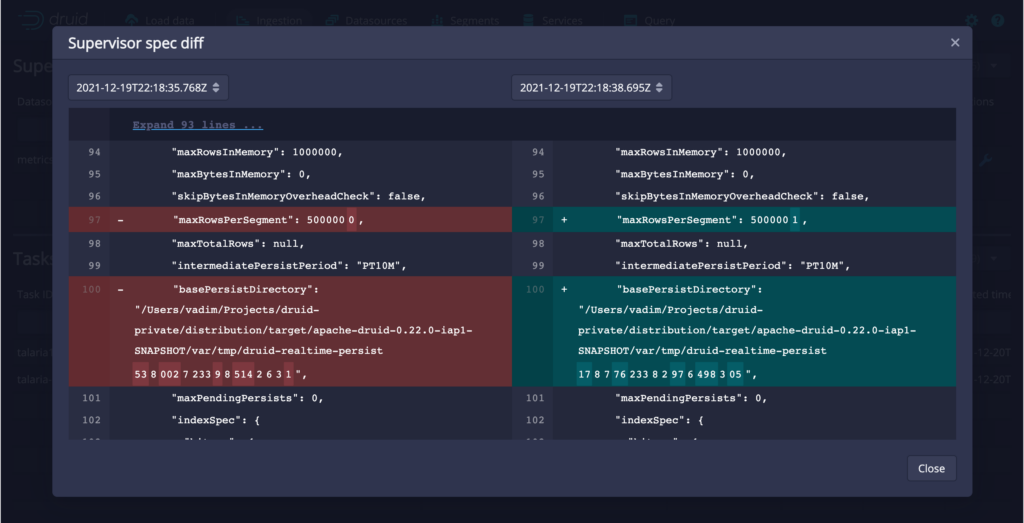
Ingestion: Ingestion spec diff view
The new webconsole in Druid 0.23 now displays the difference between ingestion specs. This can help you identify the changes more easily.
Query cancellation API
Druid is designed for rapid data exploration. Changing visualization and dashboard parameters doesn’t cancel active queries. In this release, we have introduced the Query cancellation API so that users building applications can cancel queries. You can use this to cancel queries that are no longer needed or causing problems. This can drastically reduce the query load on a Druid cluster.
You can learn more about the Query cancellation API here.
Adding safe divide function for SQL queries
Doing divisions is quite common in SQL queries. For example:
This query will likely fail in the real world, given you might have transactions of 0 items. And computers will not be happy if you ask them to divide by zero.
One option is to pre-process the data to avoid zeros, but that’s not always possible as you won’t know ahead of time what will be used as a denominator. Thus, we have introduced SAFE_DIVIDE, where the function will return 0 if either term is 0.
Summary
As you can see, Druid is a database that delivers cutting-edge performance while constantly improving on its core scenarios. Give it a try by downloading Druid here. To get started with Imply Polaris, sign up for a free trial here.
Try this out today
For a full list of all new functionality in Druid 0.23.0, head over to the Apache Druid download page and check out the release notes! And if you are interested in learning more, I’d like to invite you to check out the second part of the blog series covering more advanced scenarios.
Other blogs you might find interesting
No records found...
Jun 16, 2025
10 Years of Imply: From Apache Druid to What’s Next in Real-Time Analytics
We’ve officially hit double digits! Ten years ago, a few Druid-obsessed engineers asked a radical question: What if analytics didn’t have to be slow, stale, or stuck in dashboards? Back then, we were just...
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...