Elasticity is important, but beware the database that can only save you money when your application is not in use. The best solution will have excellent price-performance under all conditions.
Many application architects and developers are under pressure to standardize on a database. For you, perhaps this is Snowflake. It would be reasonable to assume that your analytics applications should also run on it. So why consider a different database, one that is purpose-built for analytics applications? The question answers itself: purpose-built. Snowflake’s architecture is not built for a modern analytics application and in fact works against it being a sustainable choice.
I’m not saying that Snowflake can’t do any analytics. Snowflake is a good choice for traditional business intelligence, such as reports and dashboards. These typically have low interactivity, few concurrent users, and are based on batch data that is refreshed only periodically. If you need high interactivity, concurrency, or real-time data, Snowflake just isn’t designed for this.
What is Snowflake Selling?
In general, analytics applications need two things:
The elasticity to make developers and system admins happy. As needs change and the system grows, you adapt quickly.
The query performance to make end users happy. When they click on something in your app, they get an answer in less than a second. Even better if the data freshness is real-time.
Snowflake’s main value proposition is simple: elasticity. Save money when your application is not in use, scale up to meet a spike in demand, and then scale back down. This requires an architecture that separates storage and compute.
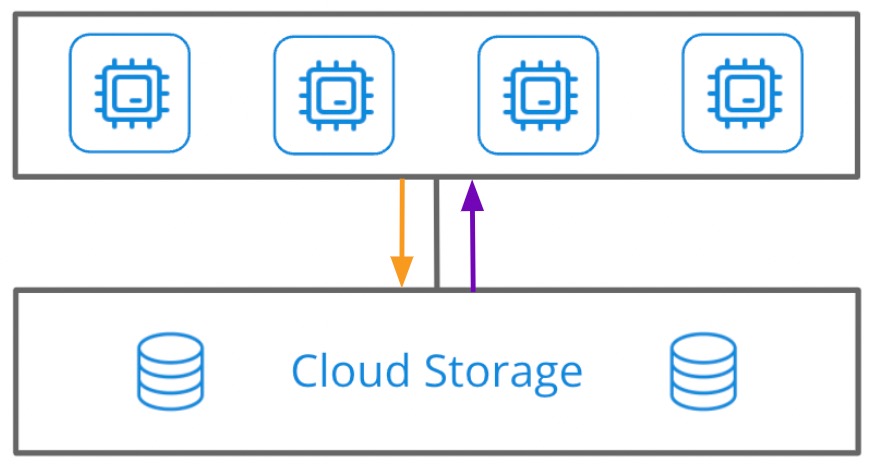
By storing data in a different layer than the computing power that processes queries, you can add or remove compute power when you need it–usually within a few minutes. However, this comes at the cost of query processing, since round-trips to the storage layer for data is very slow.
Fig 1: a 4-node cluster with separated storage and compute (query processing). Data movement between layers causes major query performance degradation, but adding/removing compute nodes is easy.
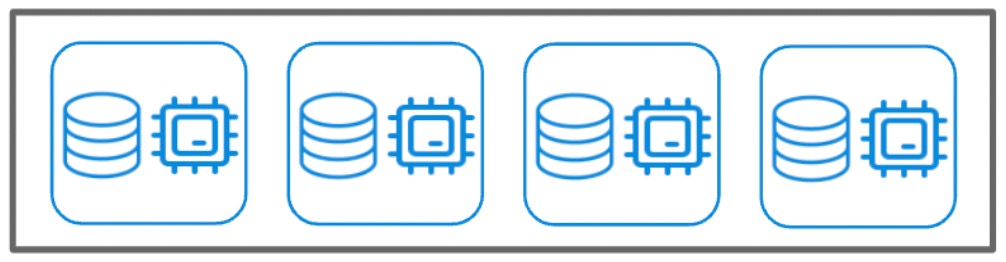
This is in contrast to Snowflake competitors Amazon Redshift and ClickHouse, who are focused on performance. So, they use a shared-nothing design where storage and compute are located on the same nodes of a cluster. The query performance is much better with this approach, but scaling to meet demand can be a multi-day effort (I detail this in an article about ClickHouse).
Fig 2: a 4-node cluster with storage and compute (query processing) on each node. This eliminates the data movement that slows queries, but adding/removing nodes requires downtime to redistribute data.
With elasticity as their value proposition, it is clear why Snowflake chose separation of storage and compute. But they had to make an unavoidable trade-off with query performance. If you are on Snowflake, it is because you value this elasticity. Application not in use? Shut it down! Sudden spike in demand? Ramp it up!
This pay-as-you-go approach is great for something infrequently used. For example, your weekly dashboard for executives. What if, though, you build an app for external use and now need to support lots of concurrent users, sub-second response on high volumes of data, or real-time data? Frankly, don’t you want this to happen? Who wants to build an analytics app that doesn’t get used? Every developer wants to build an application that is so important, it is in use constantly by lots of people. What is essential is to support constant use economically.
With this as the context, let’s compare Snowflake and Druid across 4 areas vital to an important, rapidly growing, and constantly used analytics app: caching, indexing, concurrency, and real-time data. Along the way, I’ll explain how Druid’s architecture addresses both needs: elasticity and performance.
Caching
Snowflake’s architecture works against it when you need rapid query response. Because the computing power that processes queries is physically separated from the data, many round trips must happen, killing efficiency. Snowflake tries to solve this with caching, temporarily storing recently-used data at the compute layer. This will help for queries that are repeated or happen to be using the data already cached. The issue becomes optimizing the cache constantly. If you don’t know what your users will query next, or you are constantly adding data, caching is difficult to optimize.
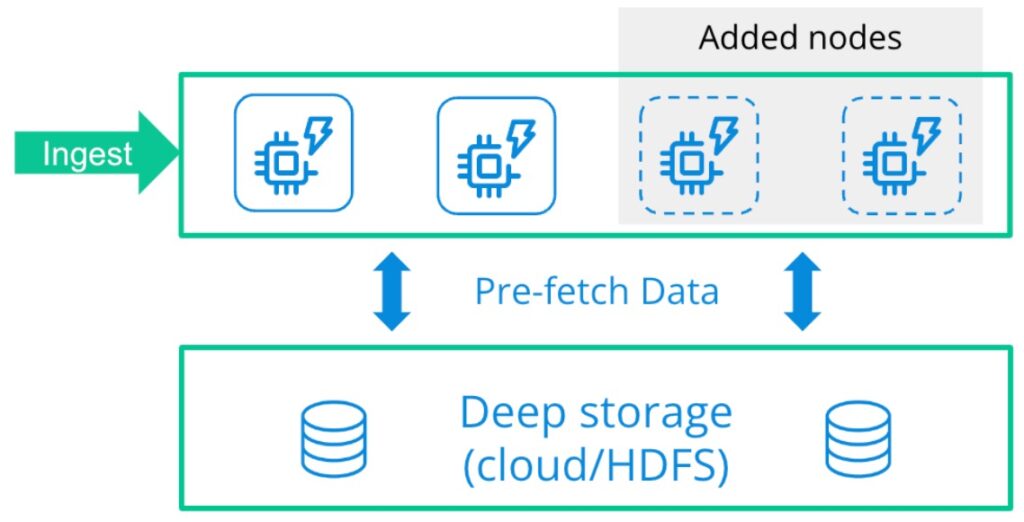
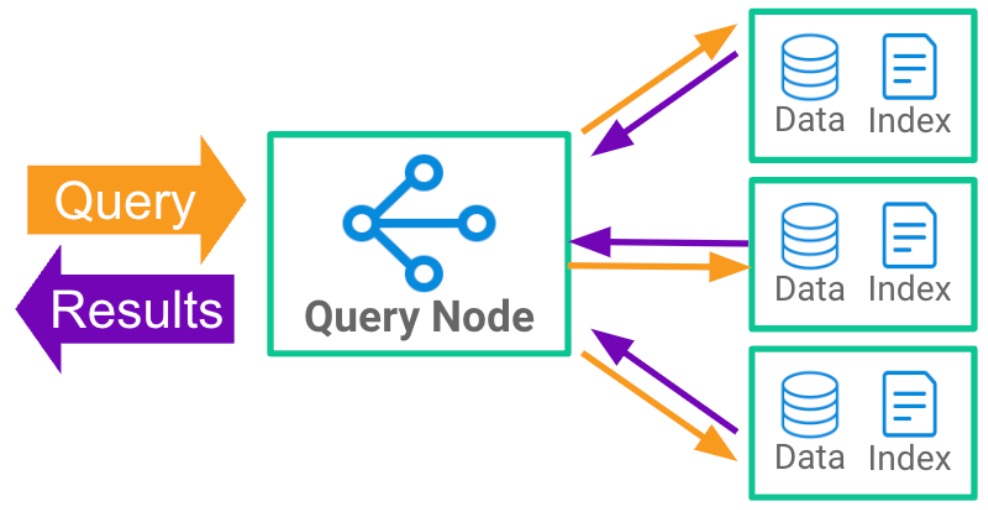
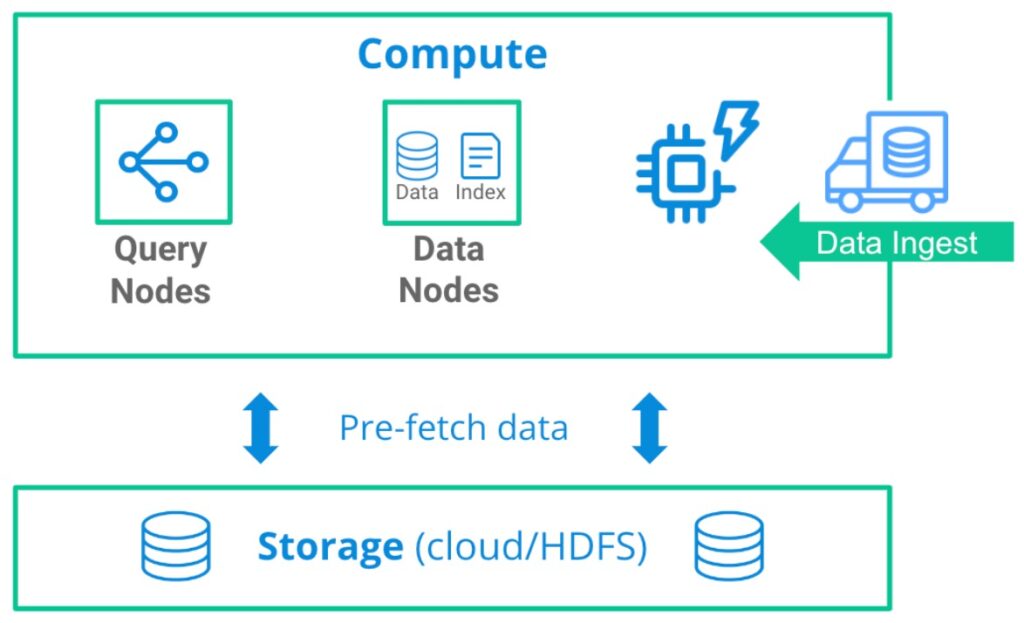
Druid solves this with a unique architecture that combines the flexibility of separate storage and compute (like Snowflake) with shared-nothing performance (like Redshift and ClickHouse). Instead of limited caching that must be constantly redone and optimized, Druid pre-fetches all data, enabling sub-second response for the first query and anything that comes next. Yet you can add and remove nodes as needed and Druid will automatically rebalance the cluster.
Fig 3: An overview of Druid’s architecture with separate storage and compute (query processing) for flexibility and prefetching for shared-nothing performance.
Indexing
Snowflake does not use secondary indexes. As with any database, you still order your data by a primary index (key), and they are betting that most of what you want can be done by scanning and then filtering by this key. Scans are slow in any case, and if you want high cardinality data (specific records, not ranges of records), it is a lot of wasted effort. Snowflake tries to hide this inefficiency by adding computing power (scaling up) and getting the results by brute force. This might work when only a few users are hammering away at the data, but scaling up will definitely cost you more.
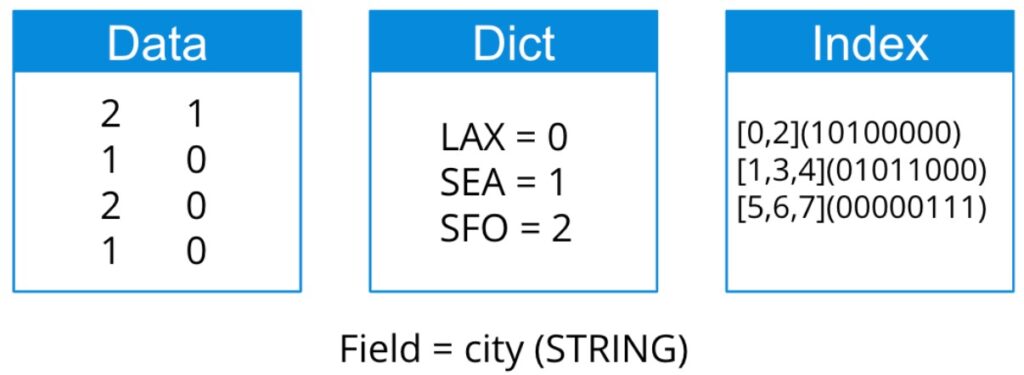
Druid automatically creates indexes that not only reduce scanning, but also ensure high cardinality queries are sub-second or very close to it. Druid data segments are columnar and compressed, making them highly efficient. Data is automatically indexed on data nodes during ingestion, making it essentially “pre-fetched” for queries from deep storage. It’s a combination that beats old-fashioned caching and brute force in price-performance. Most Druid use cases involve massive amounts of read-only data organized by time–perfect for this efficient storage design.
Fig 4: a Druid data segment showing compressed columnar storage with data dictionary and automatic indexing. In this very small example, there are 3 records for LAX, 3 for SEA, and 2 for SFO.
Concurrency
Snowflake claims you can “…support a near-unlimited number of concurrent users and workloads without degrading performance.” So it may come as a surprise to learn that the maximum concurrency of a Snowflake warehouse is only 8. Snowflake offers some advice on how to get the most out of this limit, which basically comes down to carefully monitoring what is going on and taking care not to overwhelm the system. How then can they make this “near- unlimited” claim?
I should show you the entire sentence: “Spin-up dedicated compute resources instantly to support a near-unlimited number of concurrent users and workloads without degrading performance” (emphasis added). I suppose this means that you can have near-unlimited users if you also have a near-unlimited budget to keep spinning up more computing power. Scaling out, not up, is how you solve concurrency, which is why Enterprise Edition customers of Snowflake can add up to 10 clusters per warehouse. But consider how burdensome and costly this may be with concurrent user growth. Again, with pay-as-you-go, you must hope that you don’t need to go anywhere with more than a few users.
Druid’s unique architecture handles high concurrency with ease, and it is not unusual for systems to support hundreds and even thousands of concurrent users (the Druid system at Target, for example, handles over 70,000 daily average users). Quite the opposite of Snowflake, Druid is designed to accommodate constant use at a low price point, with an efficient scatter-gather query engine that is highly distributed: scale out instead of scale up. With Druid, scaling out is always built-in, not a special feature of a more expensive enterprise version and not limited in how far you can grow.
Fig 5: illustration of Druid’s scatter-gather query engine that maximizes scale-out performance and enables high concurrency.
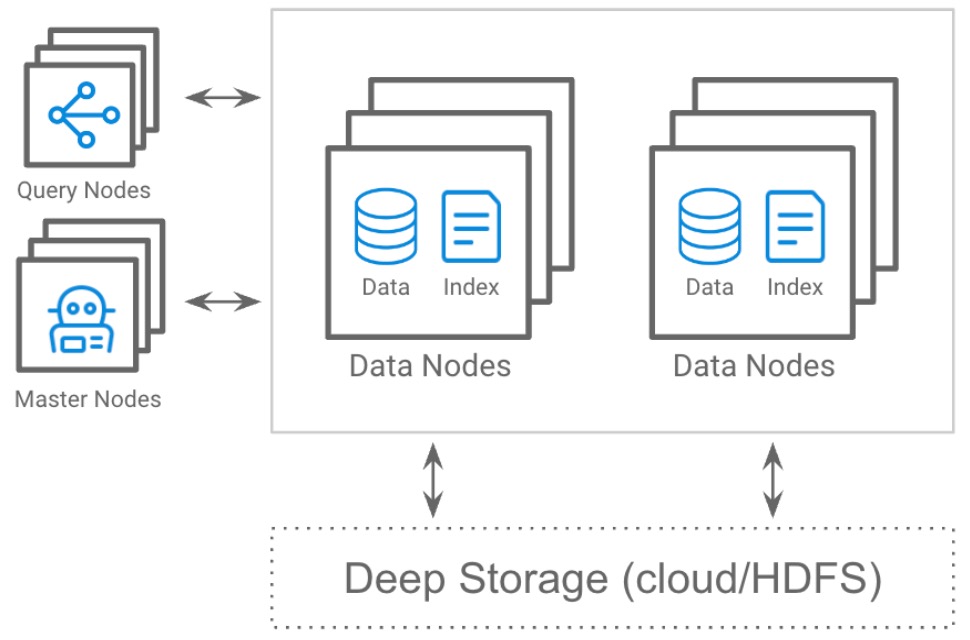
A Druid cluster has 3 major node types, each of them independently scalable, to allow a custom fit if you need it:
Data nodes for ingestion and storage
Query nodes for processing and distribution
Master nodes for cluster health and load balancing
This gives administrators fine-grained control and enables cost-saving data tiering by putting less important or older data on cheaper systems. Further, there is no limit to how many nodes you can have, with some Druid applications using thousands of nodes.
Fig 6: Druid’s independently-scalable and flexible node types. Data is also automatically replicated to deep storage for automatic backup and recovery from node failures.
Real-Time Data
Snowflake has connectors for streaming data such as Kafka and Kinesis. This isn’t a big deal–everyone has these (except for Druid, as you’ll see in a moment). But connecting to streaming data is not the same thing as being real-time. Snowflake has only one way to load the data: buffered in batches. Queries must wait for data to be batch-loaded and persisted in storage, and further delays happen if you check to make sure there are no duplicates (exactly once ingestion), a difficult proposition when thousands or even millions of events are generated each second.
Druid has native support for both Kafka and Kinesis–you do not need a connector to install and maintain. Druid can query streaming data the moment it arrives at the cluster, even millions of events per second (the Druid system at Netflix tracks 2 million events per second–115 billion each day). There’s no need to wait as it makes its way to storage. Further, because Druid ingests streaming data in an event-by-event manner, it automatically ensures exactly-once ingestion.
Fig 7: Druid can ingest millions of streaming events each second and query them immediately on arrival.
Conclusion
Snowflake’s elasticity makes it a good choice for infrequently used reporting and dashboards. But when developers from Netflix, Twitter, Confluent, Salesforce, and many others needed interactivity at scale and real-time data, they chose Druid.
The easiest way to evaluate Druid is Imply Polaris, a fully-managed database-as-a-service from Imply. You can get started with a free trial – no credit card required! Or, take Polaris for a test drive and experience firsthand how easy it is to build your next analytics application.
A First Look at Lumi Loglake: Query Logs Where They Live
TL;DR: Imply Lumi Loglake is a lakehouse (separated compute/storage) architecture for unstructured logs that reduces costs from 40% up to orders of magnitude on your hardware/AWS/Azure bill used to run your...
Imply Lumi Major Release Preview: Continuing the Journey Towards Decoupled Observability/SIEM
We are getting ready to introduce the next major expansion of Imply Lumi and the observability warehouse. When we introduced the industry’s first observability warehouse, the goal was clear: decouple the...
Imply Lumi's Grafana Loki integration is now in Private Preview. The same logs you've loaded into Lumi for Splunk are now queryable natively in Grafana using LogQL with no second pipeline, no duplicate storage,...