Search and Real-Time Analytics are Different Domains. Using the Right Tool for Your Requirements Is the Key to Success.
From a great distance, Search Engines and Real-Time Analytics Databases look similar. Both enable asking questions and getting answers from large datasets, and both use immutable segments to store data for parallel query.
For real-world projects, though, the two are very different. Understanding what each does well will let you decide whether you need one or both to reach your goals.
Search Engines and Elasticsearch
Since its initial release in 2010, Elasticsearch has grown to be the most commonly used open source search engine. It’s based on Apache Lucene, an open source Java search engine library that’s been around since 1999 and powers many other search engines, including Apache Solr, MongoDB AtlasSearch, and OpenSearch.
In Elasticsearch, source data (or “corpus”) is ingested into indexes, which are logical groupings of data similar to “databases” in relational database systems. Each index has one or more types, which define data structures, similar to relational tables. Each type will have one or more documents, which are like rows in a table, with specific information about a piece of source data, stored in JSON and parsed through analyzers and tokenizers, creating a collection of fields. While this has some similarities to relational tables, it is more flexible – different documents in the same type might or might not have the same fields.
These indexes are stored in shards, which are immutable storage segments on a cluster. Sometimes there will be one or more replicas of a shard created, to support faster parallel searches and also to provide resilience when infrastructure fails. An Elasticsearch cluster is one or more servers, called “nodes”, with the shards distributed across data nodes, with other nodes providing client and coordination services.
Elasticsearch doesn’t use the SQL language common to databases. Instead it uses its own query language, expressed in JSON, to perform searches.
What makes a search different from a query? The most important difference is relevance. A database query will return every result that matches the query parameters, in the order that the data appears in the database (or it can be ordered, grouped, and otherwise arranged by the query). A search, though, is ranked. It will bias towards the most relevant results first, with fuzzy matching placing less relevant results further down the returned list. For example, entering a search of “Hamilton” into imdb.com, a website that uses a version of Elasticsearch, will bias results towards the popular play “Hamilton”, as this is the most common search on the term – but further down the list will be other items, such as the actor Linda Hamilton.
Real-Time Analytics Databases and Druid
Druid was first launched in 2011, trying to solve a very different problem: how to ingest a billion events in under a minute and query those billion events in under a second. Druid is an open source database, a top-level project of the Apache Software Foundation. Over 1400 businesses and other organizations use Druid to power applications that require some combination of speed, scale, and streaming data.
In Druid, source data is ingested from both files (batch ingestion) and data streams including Apache Kafka and Amazon Kinesis (stream ingestion). Data is columnarized, indexed, dictionary encoded, and compressed into immutable segments, which are distributed across one or more servers. Logically, data is stored as tables, using standard relational concepts, with queries normally using SQL.
There are four characteristics of Druid that make it different than other databases:
Subsecond performance at scale
Humans and, sometimes, machines quickly and easily see and comprehend complex information and to hold interactive conversations with data, drilling down to deep detail and panning outward to global views. Many Druid solutions support interactive conversations with large data sets, maintaining subsecond performance even with dozens of PB of data.
High concurrency
Large numbers of users can generate multiple queries as they interact with the data. Architectures that support a few dozen concurrent queries aren’t sufficient when thousands of concurrent queries must be executed simultaneously. Druid provides high concurrency affordably, without requiring large installations of expensive infrastructure.
Real-time and historical data
Real-time data is usually delivered in streams, using tools like Apache Kafka, Confluent Cloud, or Amazon Kinesis. Data from past streams and from other sources, such as transactional systems, is delivered as a batch, through extract, load, and transform (ELT) processes. The combination of data types allows both real-time understanding and meaningful comparisons to the past.
Continuous Availability
Druid is designed for nonstop operations. All data is continuously backed up, for zero data loss. When hardware fails, the Druid cluster continues to operate, requiring widespread failures to cause downtime. Planned downtime is never needed, as scaling up, scaling down, and upgrades can all be executed while the cluster continues to operate. Data from streams is ingested using exactly-once semantics, so stream data is also never lost, even in the event of a full outage of a Druid cluster.
When to use Elasticsearch? When to use Druid?
Best for Elasticsearch
Could use Either
Best for Druid
Enterprise Search
Operational Visibility
Interactive Data Exploration
On-premise Object Storage
Security & Fraud Analytics
Real-Time Analytics
Understanding User Behaviour
External Analytics
IoT & Telemetry
Elasticsearch is the better platform for enterprise search, where using search semantics to return results in order of relevance is needed. In the past, some also used Elasticsearch as an inexpensive option to store large objects, such as images, videos, and big documents; today, storage has mostly moved to object stores, such as Amazon S3 and Azure Blob.
There are several use cases where both Elasticsearch and Druid are viable. For operational visibility, security & fraud analytics, understanding user behavior, and analyzing IoT and telemetry data, Elasticsearch may be a better option if performance, concurrency, and uptime are not important to the project and the customer doesn’t want to use SQL skills and tools. If there are needs for SQL queries, sub-second response, high concurrency, continuous availability, or immediate availability of streaming data, Druid is the better choice.
Druid is the better platform for interactive data exploration, where subsecond queries at scale enable analysts and others to quickly and easily drill through data, from the big picture down to any granularity. Druid is also the better platform for real-time analytics, when it’s important to have every incoming event in a data stream immediately available to query in context with historical data.
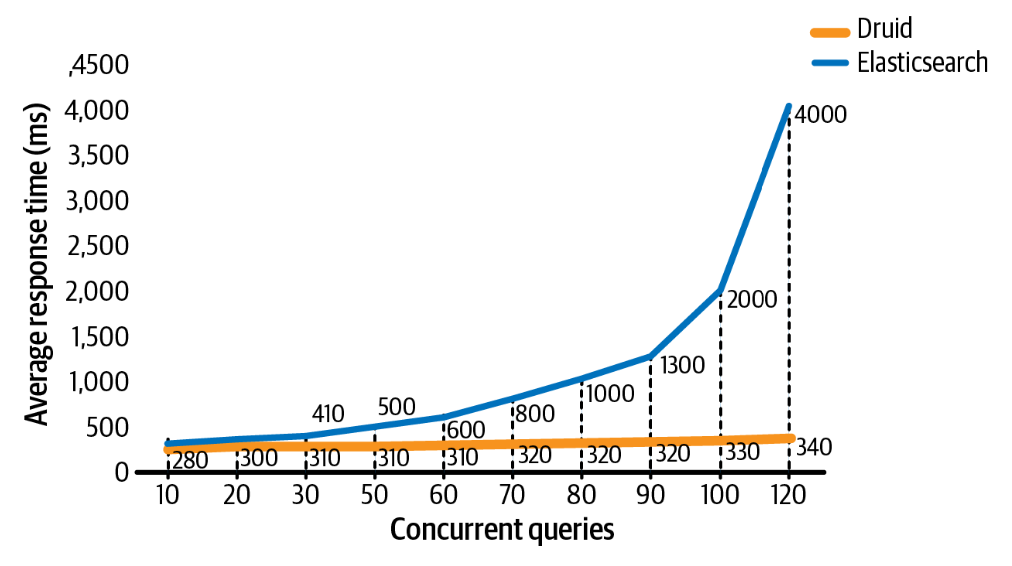
Druid’s high concurrency also makes it the better choice for applications where analytics are extended to customers or partners, where it’s difficult to predict how many queries must be supported at the same time. One organization that chose to upgrade from Elasticsearch to Druid is Nielsen Research, as their application enables their clients to visualize and analyze consumer behaviors.
When only 10 queries were running concurrently, Nielsen found the same latency, with about 280ms per query. As concurrency increased, though, Druid latency only increased slightly, while Elasticsearch latency became over 14x longer. For this project, using Druid allows Nielsen Marketing to support over 11 billion events per day across hundreds of concurrent queries, all while reducing costs by over 30%, from $80K to $55K per month.
Other blogs you might find interesting
No records found...
May 21, 2026
A First Look at Lumi Loglake: Query Logs Where They Live
At Databricks Data + AI Summit, we will preview Imply Lumi Loglake, a new step toward a more decoupled model for observability and machine data. The idea is simple: Point Lumi at your logs. Start querying....
Imply Lumi Major Release Preview: Continuing the Journey Towards Decoupled Observability/SIEM
We are getting ready to introduce the next major expansion of Imply Lumi and the observability warehouse. When we introduced the industry’s first observability warehouse, the goal was clear: decouple the...
Imply Lumi's Grafana Loki integration is now in Private Preview. The same logs you've loaded into Lumi for Splunk are now queryable natively in Grafana using LogQL with no second pipeline, no duplicate storage,...