Native support for semi-structured data in Apache Druid
May 02, 2023
Karthik Kasibhatla
Background
We’re excited to announce that we’ve added native support for ingesting and storing semi-structured data as-is in Apache Druid 24.0. In the real world, data often comes in semi-structured shapes- data from web APIs, data that originates from mobile and IoT devices etc. However, many databases require flattening of these nested shapes before storing and processing in order to provide good performance during querying. Take a simple event processing use case in a company- various teams are logging events into a multi-tenant table, but each team has its own setup and cares about different metadata fields for analyses. To handle the data, ETL/ELT pipelines need to be set up to flatten the data and prior schema has to be agreed upon upfront. As a result, not only is the developer flexibility severely limited, but also the rich relationships between the various values within the nested structures is completely lost due to flattening them out.
The advent of document stores such as MongoDB has allowed for nested objects to be stored in their native form, generally improving flexibility and developer experience working with nested data. However, these document stores come with their own set of limitations for real-time analytics, making them unsuitable for building data applications . For example, MongoDB doesn’t have native support for SQL and developers could only query the document stores using specific APIs, whereas SQL is better suited for analytical workloads
Apache Druid has a lot of tricks up its sleeve to support low latency queries, often with sub-second latency, on very large data sets but Druid also only worked with fully flattened data as the Druid segments were only able to natively store data in that format. This could be accomplished using the flattenSpec during ingestion.
With this new capability, developers can now ingest and query nested fields and retain the performance they’ve come to expect from Druid on fully flattened columns- enjoying the best of both worlds in-terms of flexibility and performance for their data applications. For the most part, our internal benchmark exercises show that query performance on nested columns is very similar to flattened data or better.
How does it work?
So what does semi-structured data actually look like? We use the sample data in nested_example_data.json for illustrative purposes. When pretty-printed, a sample row from the file looks like this-
Apache Druid 24.0 supports both native and SQL ingestion for batch data (check out Druid’s Multi-Stage Query framework) and native ingestion for streaming data with nested columns.
While this capability is specifically built so users can ingest nested data as-is and query it back out, for SQL-based batch ingestion, the SQL JSON functions can be optionally used to extract nested properties during ingestion as illustrated below.
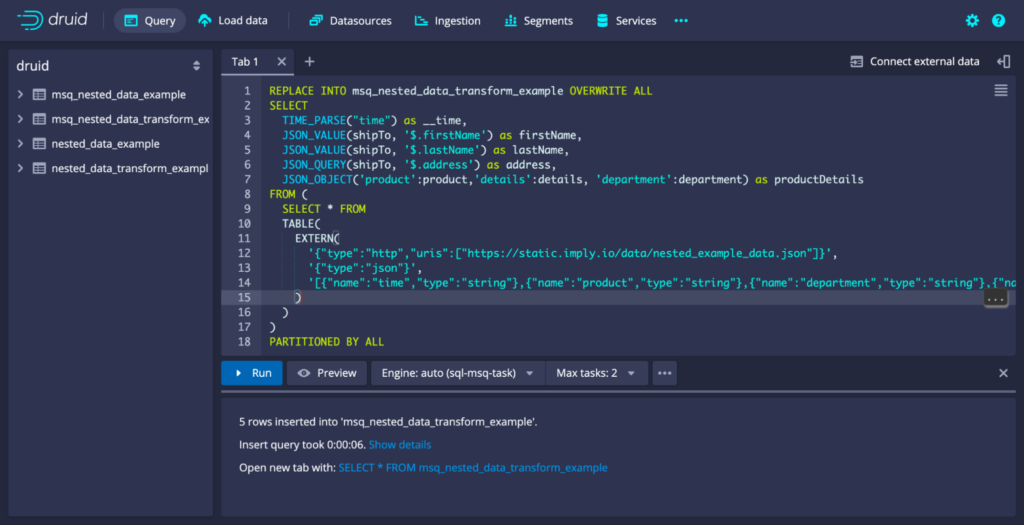
For classic batch ingestion, nested data can be transformed via the transformSpec within the ingestion spec itself. For example, the below ingestion spec extracts firstName, lastName and address from shipTo and creates a composite JSON object containing product, details and department.
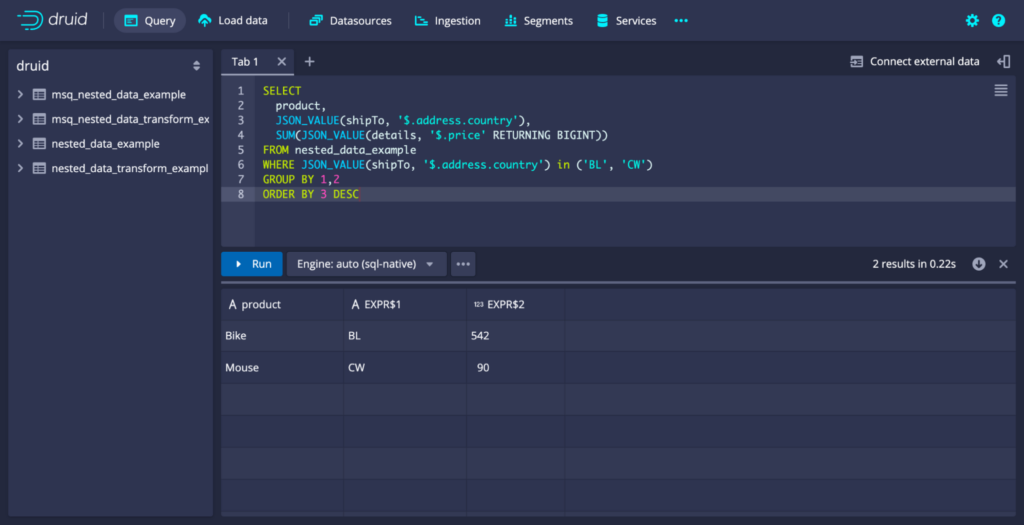
During query time, the SQL functions can be used to enable aggregating and filtering queries on raw nested data that is ingested as-is. Below is a screenshot of a sample query run on the data set.
What’s next?
Apache Druid 24.0 has support for a vast array of capabilities to support nested data in Druid. However, we’re excited to add more functionality and improvements in the upcoming releases.
We’re keen to add support for nested columns for Avro, Parquet, ORC, Protobuf in addition to JSON format, bringing the native support of semi-structured data much closer to parity with Druid’s flattenSpec.
With the current support for nested columns, users can extract individual keys and values from within the nested structures. We’d like to give users the ability to define an allow and/or deny list so that users don’t spend resources decomposing fields that are only used in their raw form.
This is an exciting new capability we’ve introduced in Apache Druid 24.0 and we’re just getting started.
Want to contribute?
We’re always on the lookout for more Druid contributors. Check out our incredible Druid community and if you find an area which you feel excited about, just jump in!
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...