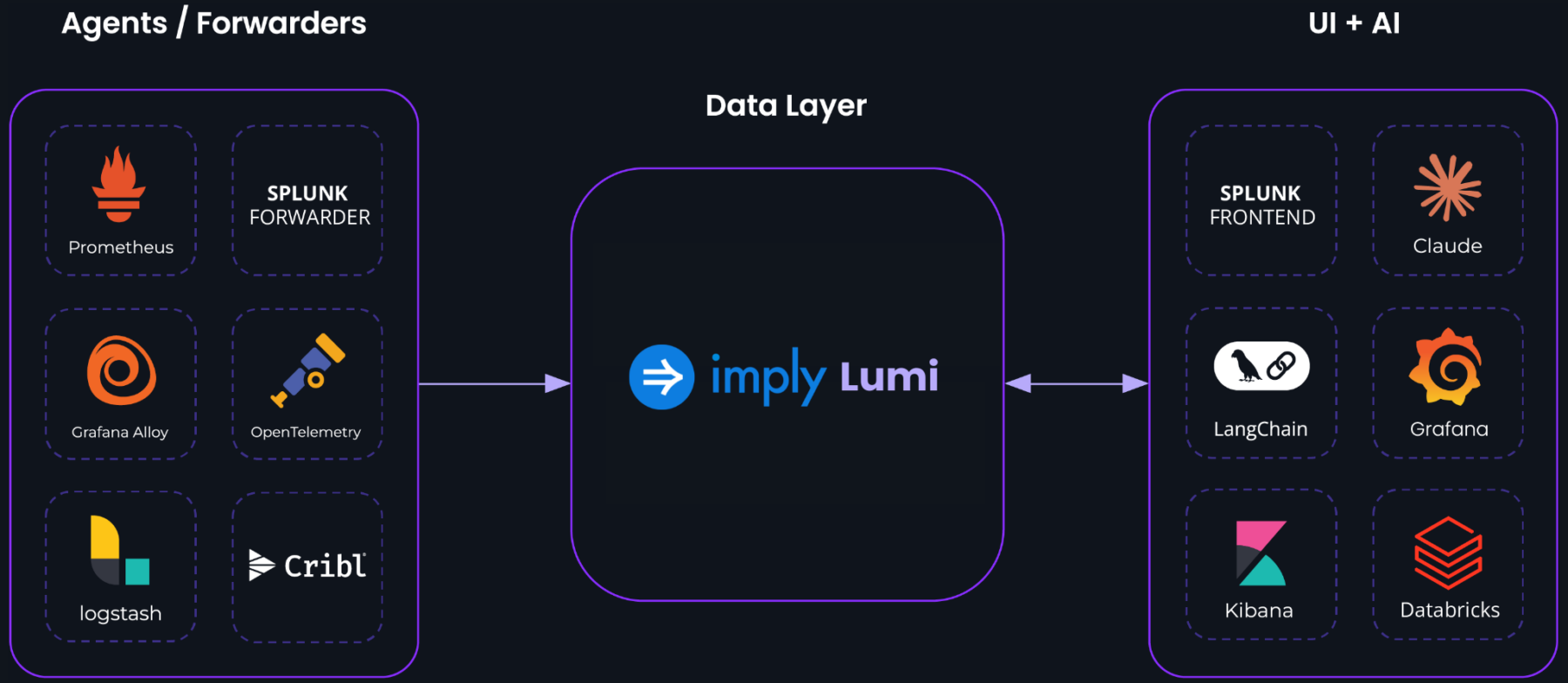
Imply Lumi
Query unstructured logs in your data lake for operational and security investigations
Imply Polaris
A fully managed, secure, cloud-native Druid-as-a-service that fast-tracks your path to real-time analytics
→ View Integrations
Observability
Security & Fraud
IoT & Telemetry
Real-time Analytics
Discover how leading organizations use Imply and the Druid ecosystem to run faster, scale bigger, and spend less.
→ See Success Stories
Insights & technology updates
Informative visual content
Upcoming Imply events
Press releases & news
Technical Imply documentation
Interactive Apache Druid courses
Customer knowledgebase & helpdesk
Resource hub for Druid developers
Hub for Apache Druid success stories
Community for Druid discussions
Lumi Loglake is out now, allowing enterprises to search unstructured logs directly in object storage. Learn more here.
Store more data, support more use cases, and spend less
Tightly coupled architecture
Open, decoupled architecture
Use Imply to work with your existing tools, load more data, and unlock new possibilities without changing how you work.
Why Imply
Ingest once, use anywhere,and unlock new possibilities.
See Imply Lumi In Action
A quick walkthrough of how to store more data, speed up queries, and cut costs — without changing your workflows.
AI and BI Ready
Conversational AccessAsk questions in Claude, ChatGPT and other AI tools to get instant answers from your observability data.
Model TrainingFeed months or years of high-fidelity data directly into your machine learning pipelines.
Business IntelligenceVisualize and explore your observability data in Tableau, Power BI, and other BI tools.
Powerful Integrations
Measurable Benefits