Belle, Service Analytics, KakaoBank Zet, Analytics Engineering, KakaoBank
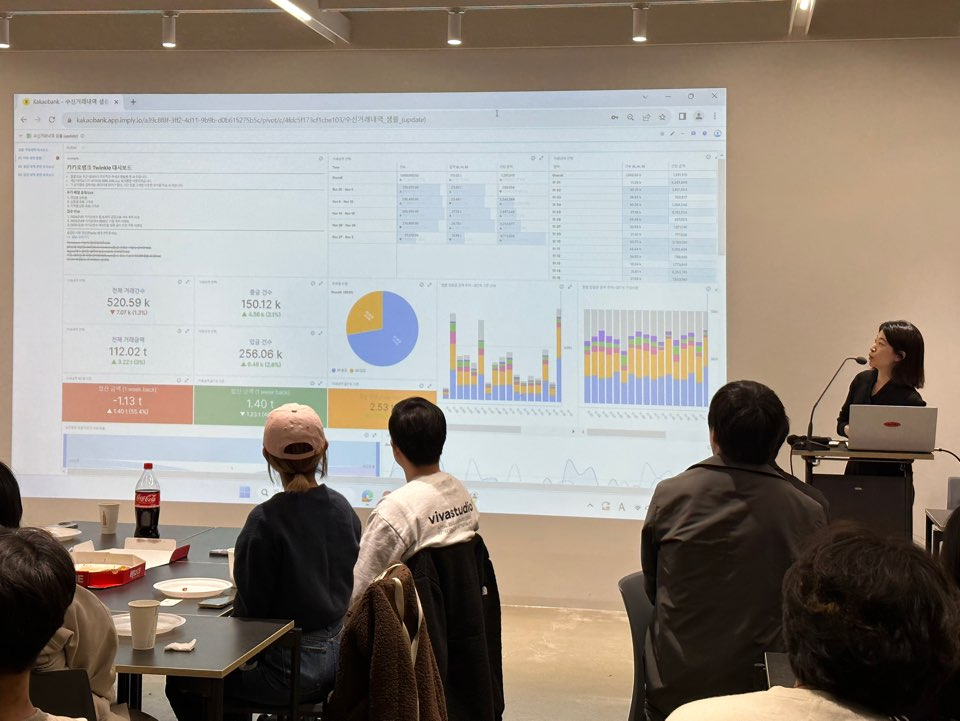
Belle, Data Scientist at KakaoBank, walks visitors through a demo at Druid Meetup Pangyo.
KakaoBank, a subsidiary of Kakao Corporation in South Korea, is a digital bank known for its user-friendly mobile platform. Launched in 2016, it has transformed traditional banking with seamless and innovative financial services, allowing customers to easily open accounts, apply for loans, and manage their finances through the mobile app.
As a mobile-first digital platform, KakaoBank accumulates a substantial amount of data. Therefore, analysts need a solution that can effectively analyze and pre-process large quantities of data, visualize the results, and respond to a high volume of parallel analytical queries. To power this high-concurrency, high-resolution analytical environment, KakaoBank chose Imply, specifically Apache Druid for storage and analysis, and Pivot for visualization.
The nature of banking data
Among the various Imply use cases at KakaoBank, perhaps the most interesting one is financial analytics. From a data perspective, the characteristics of banking data differ significantly from those of typical web and mobile services.
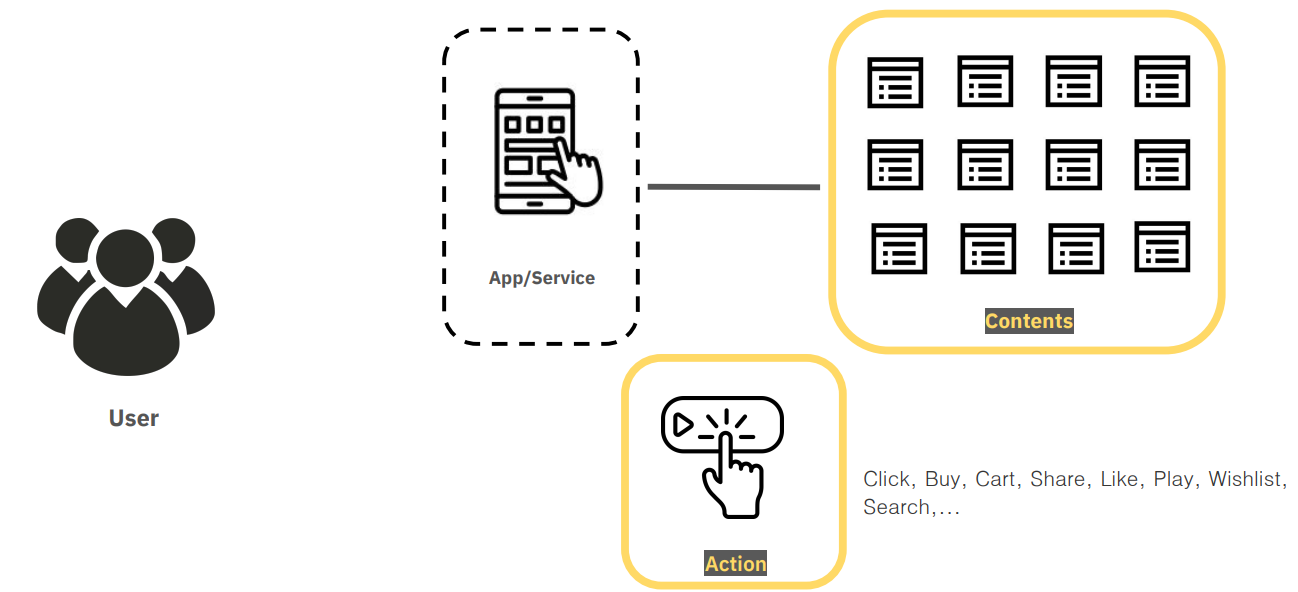
A sample analytics diagram for typical applications, such as e-commerce or streaming media.
In most mobile apps, the focus is on user behavior—collecting and analyzing data on user actions such as clicks, purchases, shopping cart additions, likes, plays, and searches. The ultimate goal of analyzing this data is to understand user behavior patterns. And during the times when the mobile device is turned off and the service is not being used, there is nothing to analyze.
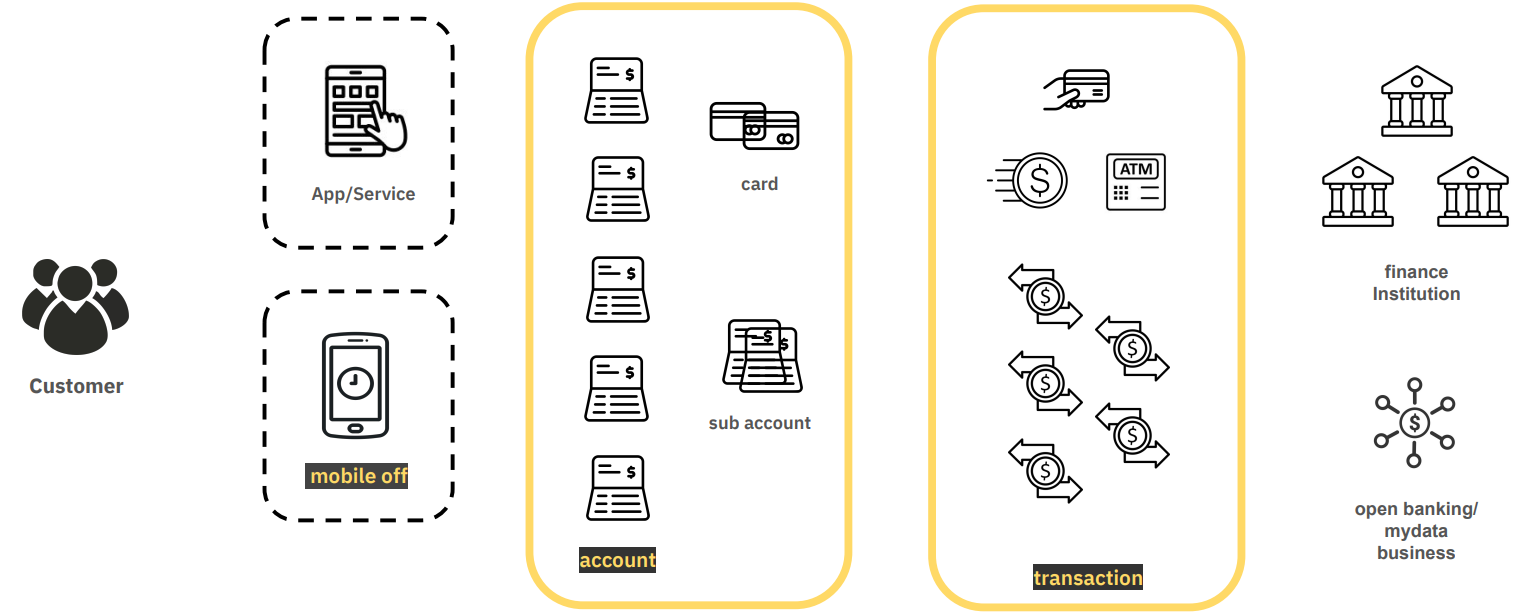
A sample analytics flow for an online banking application.
However, banks tend to analyze data from a perspective other than user behavior, focusing instead on accounts and transactions. Even when services or mobile devices are turned off, numerous transactions occur—such as debit card payments, interest transfers for loans, and recurring payments—that are unrelated to user actions.
By analyzing this data, banks can improve different initiatives, such as understanding transactional trends including withdrawals, deposits, loans, overseas transfers, and more. Moreover, delving deeper into such data allows for analysis at a very granular level, providing an opportunity to make discoveries that were previously unnoticed.
Why KakaoBank uses Imply
Imply is particularly valuable for financial institutions aiming to dive deeper into a wealth of data. In the banking sector, operations predominantly rely on traditional architectures, leveraging data warehousing (DW) and Big Data for Business Intelligence (BI) to analyze transaction data.
While this setup was ideal for small-scale, structured analysis on batch data, new challenges arose. Specifically, KakaoBank needed to support a higher data resolution as well as increased concurrency. Ultimately, this led to handling a significantly larger dataset with a high rate of parallel queries compared to traditional, aggregate-based data mart operations. To address this, KakaoBank required a robust engine capable of processing a high volume of simultaneous, ad-hoc queries on massive datasets.
Venturing into new analyses brings forth two key requirements. First, there’s a need to support higher data resolution, and second, there’s a demand for increased concurrency. Ultimately, this leads to handling a significantly larger dataset with high concurrent queries compared to traditional aggregate-based mart operations. To address this, a robust engine capable of processing numerous ad-hoc queries on massive datasets is essential.
To tackle this challenge, KakaoBank has implemented a structure that preprocesses data on the big data platform, ensuring it’s conducive to in-depth analysis, and then loads it into Imply. The preprocessing involves analysts defining their analysis goals, creating sample datasets, and requesting data engineers to handle the tasks in Impala, generating Parquet files that are subsequently loaded into Imply. This iterative process enables effective analysis tailored to the unique demands of financial data exploration.
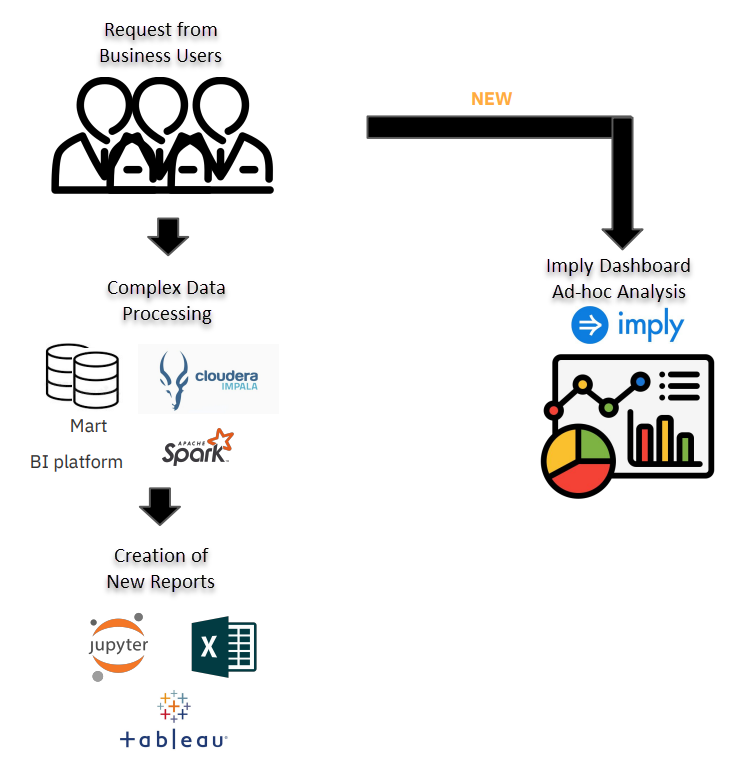
A high-level diagram of the KakaoBank data architecture
Business benefits
Previously, KakaoBank’s environment could support a limited number of ad-hoc queries on smaller, pre-aggregated datasets. This procedure was very formalized: business users would submit requests, which were then processed and visualized in reporting and business intelligence tools like Tableau.
However, the data analyst team found that accommodating unexpected, ad-hoc requests could be very time consuming. By utilizing Pivot, Imply’s engine for building intuitive visualizations, the data analyst team could easily build interactive graphics. This enabled the analyst team to reduce their workload and allow business users to independently access data and perform ad hoc analysis.
KakaoBank’s new process (post-Imply)
KakaoBank utilizes Imply to leverage financial data, incorporating a diverse range of high-resolution charts on a single screen. Moreover, large-scale dashboards load within subseconds with Imply. While traditional tools faced performance challenges in constructing such dashboards, KakaoBank has been able to enhance its analysis capabilities significantly through Imply Pivot.
The next step involves expanding the use of Imply Pivot beyond business users directly involved in operations. KakaoBank aims to empower many more employees within the organization to use it as a tool for understanding financial data. By strengthening analytical capabilities and promoting a high level of data understanding, KakaoBank anticipates gaining a competitive edge through differentiation.
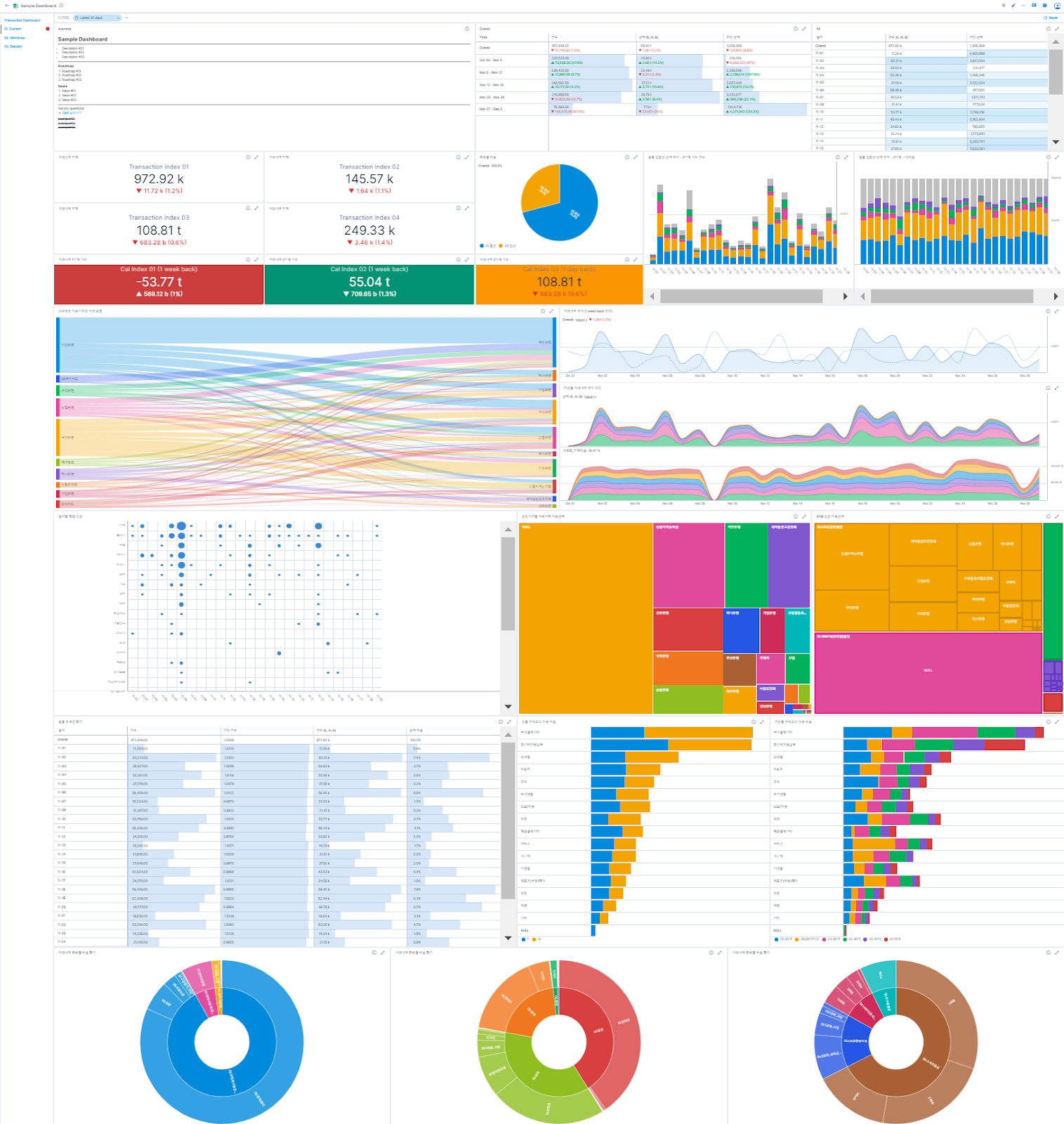
A sample dashboard used by the KakaoBank team.
(* The data shown in the pictures were generated for demo purposes, and was not taken from real customers.)
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....