Many use cases require “flattening” records. The need for this is exemplified in the existence of array-type columns. Such columns occur whenever an array of objects is ingested as a single column. Real-world examples of this range from items purchased in a grocery store to a list of countries visited by a person or even a chain of activities done on a web page by a user. Flattening the data out can help in association mining, finding user patterns on a travel site or web page, thereby enabling the system to make real-time (what online item you can buy) or forward- looking recommendations (product placement inside a store).
Now considering there are thousands of places to visit and millions of things to buy online, keeping an array-type column is the generic dense representation of the data (rather than keeping a column for each, leading to sparse representation). Hence there is the requirement to flatten or UNNEST the elements from the arrays to group by and aggregate individual elements to analyze patterns. Druid supports multi-value strings through multi-value dimensions (MVDs), which automatically flattens during a group-by. But Druid also has inherent array typed columns for different data types. Therefore, there’s a need for supporting operations on array-typed columns and a function that takes in an array of objects and emits out a series of rows of individual elements, which can be aggregated later. Moreover, an MVD can inherently be converted into an array-type column using druid functions such as MV_TO_ARRAY.
Other SQL systems have similar capabilities; they expect an ARRAY type of data, and then you put that into an UNNEST operator. Then, they “explode” out one new row for every value in the array.
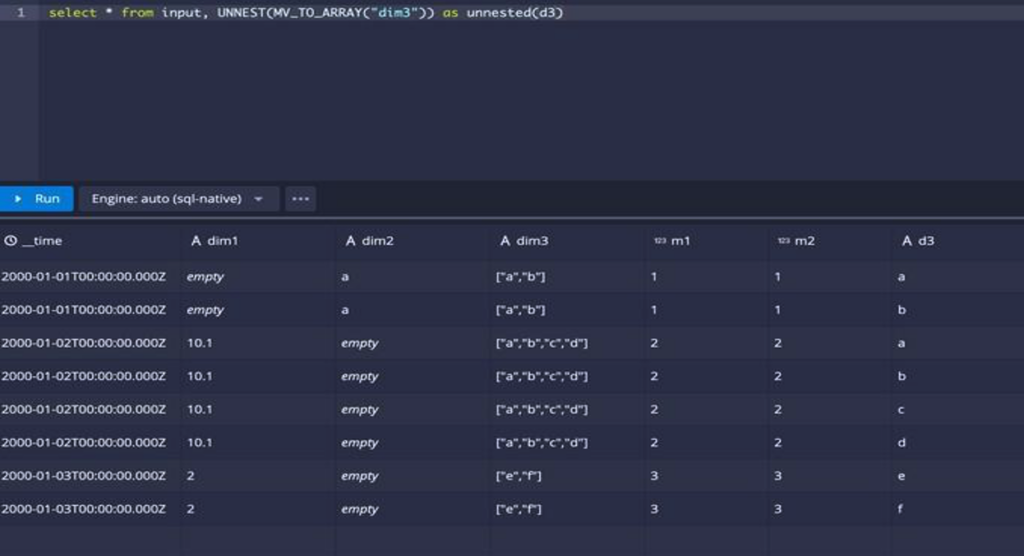
We implemented a similar function for Druid. For example, take the following table. We’ll call it input throughout the example.
time
dim1
dim2
dim3
m1
m2
2000-01-01T00:00: 00.000Z
empty
a
[“a”, “b”]
1
1
2000-01-02T00:00: 00.000Z
10.1
[“a”, “b”, “c”, “d”]
2
2
2000-01-03T00:00: 00.000Z
2
[“e”, “f”]
3
3
UNNEST on this dataset is shown below:
1. An UNNEST on a Multi-value string dimension. As UNNEST works on arrays, MV_TO_ARRAY is used to convert an MVD to an ARRAY
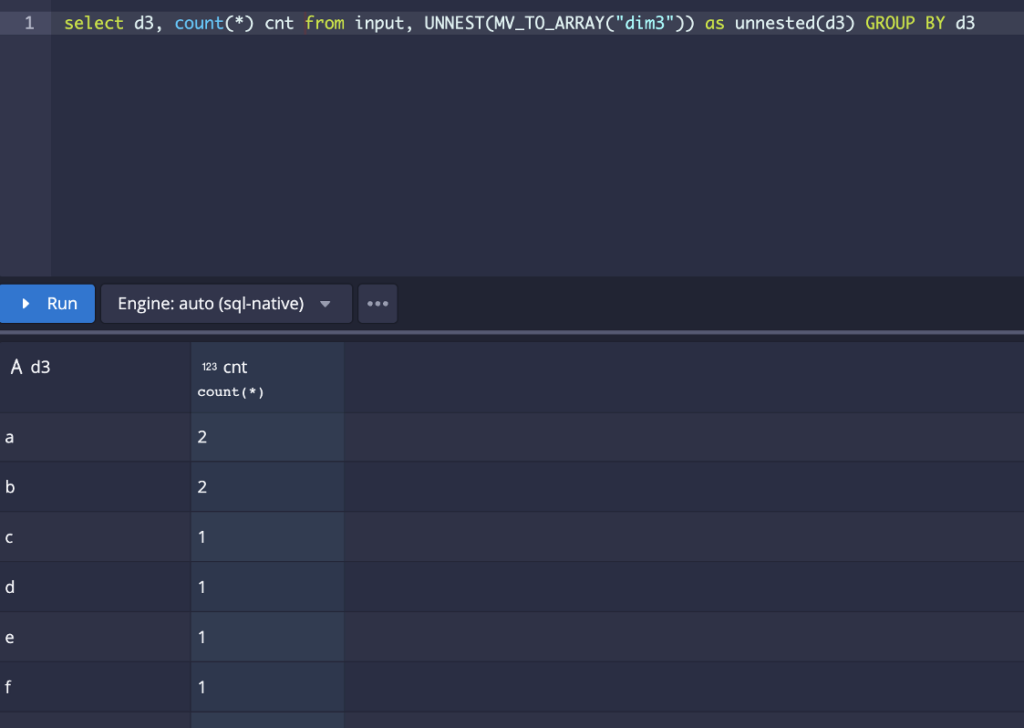
2. Druid supports GROUP BY, ORDER BY, etc. on the unnested column
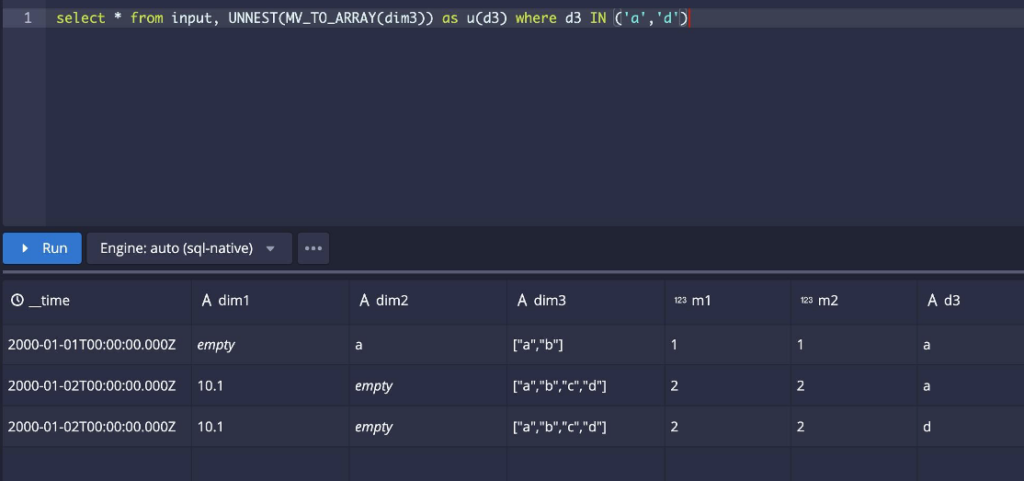
3. Additionally Druid supports filters on the unnested column
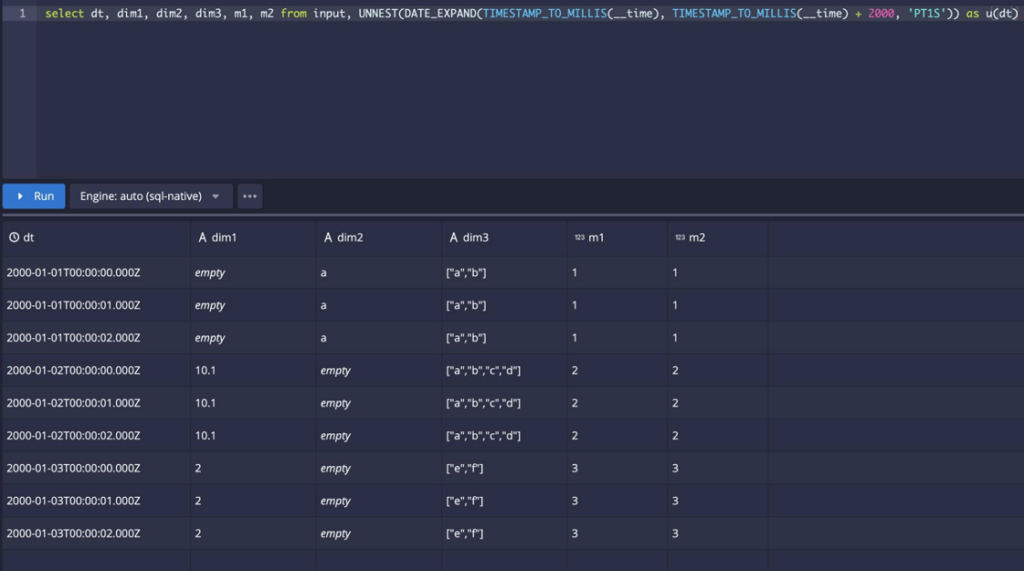
4. Assuming a hypothetical function that creates an array of timestamps, UNNEST can also be used on that array column to create new time cols
Execution Strategy
The UNNEST operation is well-suited for distributed processing. In Druid, rows are already divided into segments so that the operation can be done at the segment level to UNNEST one column in a row. Also unlike joins, a segment does not need any additional data (such as the broadcast table, lookup table, or another table). The information for unnesting a column for a row is just the column name to be unnested and a new column name if the user wants to output the unnested value to a new column.
UNNEST, overall, is a function over an existing table. This function takes an existing table and a column name to UNNEST and explodes each row of the column into rows with individual array elements in the original row. The approach taken by Druid is to push this operation to the individual segments of the table (or data source), and each segment can UNNEST rows in a distributed way. Conceptually, UNNEST is modeled as a data source on top of the existing data source through the use of a transformation.
To apply a transformation on a data source, Druid uses the concept of a segment map function where an existing segment of the base data source can be mapped to another segment following a mapping function. The concept of a segment map function is already baked into Druid during the join data source creation. We build on the existing architecture by defining a segment map function for the UNNEST case.
Imperatively, we model UNNEST as a data source. Since UNNEST is an abstraction of a data source over an existing data source, it requires the following elements:
A base data source (base)
The dimension to be unnested (column)
The output name of the column where the unnested values should be added (output name)
Native Query
The underlying principle here is an operation on a data source that works on a segment and creates additional rows. Joins have a similar principle where the number of rows can be more than the input table after the join operation. The current framework supports that in the following ways:
Having a join data source alongside a factory and then a specialized wrapper (JoinableFactoryWrapper.java ) around it creates a function to transform one segment into another by the notion of a segment function.
Having a separate implementation of segment reference through HashJoinSegment.java, which uses a custom storage adapter to access a cursor to the segment for processing.
The goal is to move out the creation of the segment map function from outside the wrapper to individual data sources. In cases where the segment map function is not an identity function (like for join and also for UNNEST), the segment functions can be created accordingly for each data source. This makes the abstraction generic and readily extendable to other data sources we might create in the future.
We now have an UnnestDataSource class that deals with UNNEST, and UnnestDataSource.java is the implementation. The UNNEST data source has two parts:
DataSourcebase;VirtualColumnvirtualColumn;
The base data source is the one that gets unnested. It can be a table, query, join, or even an UNNEST data source.
The virtual column has the information about which column needs to be unnested and the column reference to be unnested. It supports either a single dimension
The name of the column that gets unnested appears in the expression field while the output column name is internally delegated as j0.UNNEST.
UNNEST Storage Adapters
We use a separate storage adapter for UNNEST, which takes care of creating cursors on the data source. Cursors are responsible for traversing over rows in a segment. The most recent implementation can be found at UnnestStorageAdapter.java. This adapter does the following:
Create the pre and post-filters on the UNNEST data source. All the filters specified on the query, which can be applied to any column on the base data source, constitute the pre-UNNEST filters. The others are the post-UNNEST filters. If UNNEST is used on a single column and not on a virtual column, that particular filter is also rewritten to the pre-UNNEST filter to reduce the amount of data UNNEST has to work with. The pre-UNNEST filters are passed on to the base data source cursor to reduce the number of rows sent to UNNEST.
Typically, string-based columns in Druid are dictionary encoded. The storage adapter, depending on the type of column being unnested, creates two different UNNEST cursors. One DimensionCursor takes advantage of the dictionary encoding to iterate over data while the ColumnarCursor addresses the rest.
These cursors are wrapped in the end with a PostJoinCursor, which takes in the post-UNNEST filter to filter out the appropriate rows needed in the query result.
UNNEST Cursors
The cursor of the base table gives a pointer to iterate over each row in a segment. On each call of advance(), the cursor jumps to the next row and the method isDone() is set to true when the cursor cannot advance any more, indicating the end of a segment. We need to define an additional cursor that, when advanced, goes over the next element of the array column, and the base cursor is advanced only when the end of the array is reached. There are two implementations of cursors, one for dictionary-encoded columns and the other for regular columns. To give a simple example, consider the table
time
dim1
dim3
2000-01-01T00:00:00.000Z
1
[“a”, “b”]
2000-01-02T00:00:00.000Z
2
[“c”, “d”, “x”]
2000-01-03T00:00:00.000Z
3
[“e”, “f”]
The base cursor is pointed to the first row at the start of the array. An UnnestCursor.advance() follows the operations described in the table below:
Operation
BaseCursor
UnnestCursor
Comment
advance()
Points to start of row 1
a
advance()
Points to start of row 1
b
advance()
Points to start of row 2
c
This advance call moved the base cursor as the end of the array on row 1 was reached
advance()
Points to start of row 2
d
advance()
Points to start of row 2
x
advance()
Points to start of row 3
e
This advance call moved the base cursor as the end of the array on row 2 was reached
advance()
Points to start of row 3
f
advance()
cannot advance
cannot advance
This advance call moved the base cursor as the end of the array on row 3 was reached. The baseCursor moved to a done state and so did the UNNEST cursor
Post Join Cursor
The previous case shows a regular UNNEST without any filters. The storage adapter wraps UNNEST cursor is wrapped in a post-join cursor which at the time of advance uses the value matcher of the filter to keep moving the cursor till the next match. Consider a filter like where unnested_column_over_dim IN (‘a’, ‘d’). That UNNEST operation proceeds like this:
Operation
BaseCursor
UnnestCursor
Comment
advance()
Points to start of row 1
a
advance()
Points to start of row 2
d
The cursor was moved to the next matching value and the base cursor was also advanced as the end of the first array was reached in the process
advance()
cannot advance
cannot advance
The baseCursor moved to a done state as no more rows were left to be served and so did the UNNEST cursor.
Note that the row [e,f] was never received because of the following reasons:
Druid figured out that the post-UNNEST filter references a single column in the input table
The filter was rewritten on the dimension to be unnested and passed to the base cursor
Only the filtered row appeared to be unnested. In an array-typed column, if there is a single match, the entire row is returned by Druid. In this case, the rows returned by the base cursor are rows 1 and 2, so the post-UNNEST filter filters out the rest.
Druid uses Apache Calcite for planning SQL queries. The logical plan generated by Calcite is governed by rules developed by Druid to cater to the underlying native queries. We need 3 things to generate the SQL binding:
The query syntax
The rules to support the new syntax
Appropriate Druid-specific relations to convert to the native query from the logical plan
Query Syntax
We thought about the following when designing the query syntax:
An easy-to-understand syntax from the users’ perspective for UNNEST that’s similar to other databases for ease of use
The ability to UNNEST multiple columns in the same table
The ability to pass the output of UNNEST to another operation and setup chaining
Apache Beam and BigQuery use the concept of a lateral join or cross join for defining UNNEST. We follow a similar pattern for defining the query syntax for UNNEST. Our query takes the form:
select*fromtable,UNNEST(expression) as table_alias(column_alias)
This is similar to a cross-join (or correlation between the left data source (here table on the left) and the unnested expression on the table which is referenced as a table with a single column using the alias. The expression can be the dimension name for an array-typed column, a virtual expression, or even the Druid MVD column translated into an array. Here are some example queries:
SELECT dim1,dim2,foo.d45 FROM"numFoo", UNNEST(ARRAY["dim4", "dim5"]) as foo(d45)SELECT*FROM"numFoo", UNNEST(MV_TO_ARRAY(dim3)) as bar(d3)SELECT dim1, dim2, ud.d2 FROM"numFoo", UNNEST(dim2) as ud(d2)
A user can also UNNEST on a constant row like so:
select ud.d from UNNEST(ARRAY[1,2,3]) as ud(d)
Planning Rules
Planning these queries, however, faces some problems since some weren’t in place in Druid. A very simple UNNEST on an array from Calcite’s perspective generates the following logical plan:
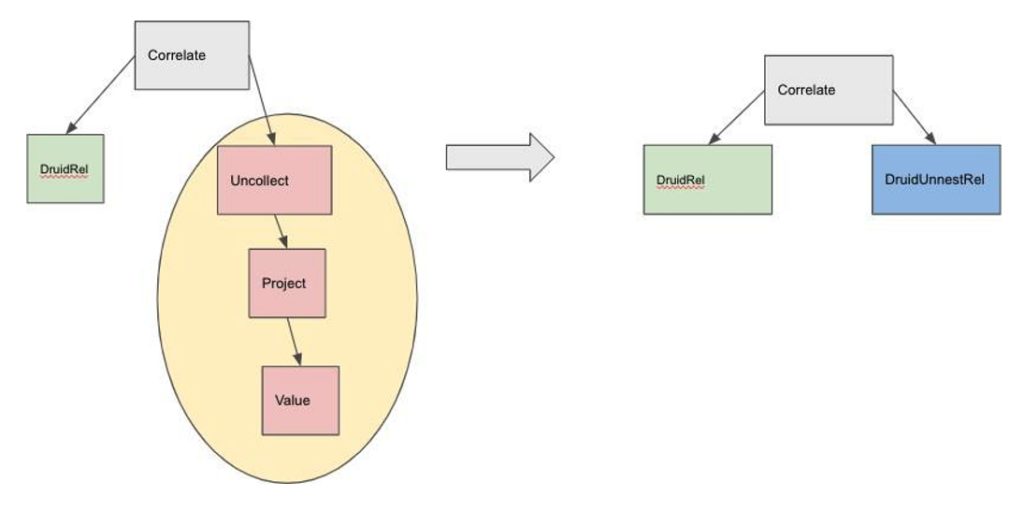
There is a common pattern seen during Uncollect (Uncollect (Apache Calcite API) ), which is basically what we needed for the UNNEST operation in Druid. The pattern is
This forms the first rule that we create: DruidUnnestRule.java. In this rule, we check if the data source is a constant expression or not. If we find an inline data source, we model this as a scan over an InlineDataSource. Otherwise, we transform the pattern to create a DruidUnnestRel. The picture below captures how the rule works
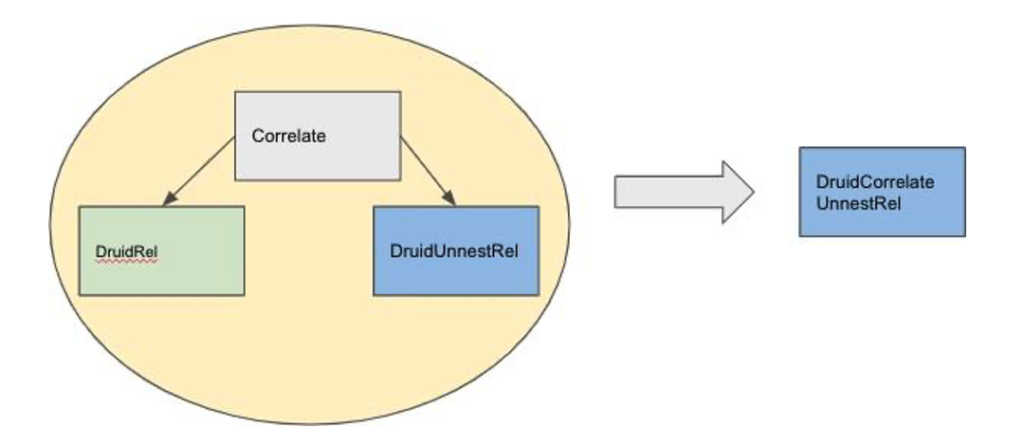
The second rule that we introduced is based on the pattern of
This works on the output of the DruidUnnestRule and transforms a correlate with the left child as a base data source and the right child as a DruidUnnestRel to a single DruidCorrelateUnnestRel. These two rules form the basis of the UNNEST operation done by Druid. Here’s a visual representation of the rule:
Finally, we can have filters either on top of the left data source or the right. The logical plan while using filters is shown below:
SELECT d3 FROM druid.numfoo, UNNEST(MV_TO_ARRAY(dim3)) as unnested (d3) where d3 IN ('a','b') and m1 <10138:LogicalProject(d3=[$17])136:LogicalCorrelate(subset=[rel#137:Subset#7.NONE.[]], correlation=[$cor0], joinType=[inner], requiredColumns=[{3}])125:LogicalFilter(subset=[rel#126:Subset#1.NONE.[]], condition=[<($14, 10)])8:LogicalTableScan(subset=[rel#124:Subset#0.NONE.[]], table=[[druid, numfoo]])132:LogicalFilter(subset=[rel#133:Subset#5.NONE.[]], condition=[OR(=($0, 'a'), =($0, 'b'))])130:Uncollect(subset=[rel#131:Subset#4.NONE.[]])128:LogicalProject(subset=[rel#129:Subset#3.NONE.[]], EXPR$0=[MV_TO_ARRAY($cor0.dim3)])9:LogicalValues(subset=[rel#127:Subset#2.NONE.[0]], tuples=[[{ 0 }]])
The filters on the left are brought to the top of uncollect with the following rule:
Calcite puts any filter on the unnested column already on the right side. The filter is not brought on top of the correlate and is stored inside the corresponding rel node for uncollect. This is done through DruidFilterUnnestRule.java
Equipped with these specific rules for Unnest and an additional ProjectCorrelateTransposeRule from Calcite, we form the basis of the SQL binding for UNNEST.
Currently, UNNEST is a beta feature and is behind a context parameter on the SQL side. The context can be set through QueryContext as
{"enableUnnest":true}
Supporting Filters
UNNEST supports filters on any column. Filters on the query if applicable on the left data source are pushed into the input data source while filters on the unnested column are pushed onto the PostJoinCursor. For example
1. If there is an AND filter between a column on the input table and the unnested column
select*from foo, UNNEST(dim3) as u(d3) where d3 IN (a,b) and m1 <10Filters pushed down to the left data source: dim3 IN (a,b) AND m1 <10Filters pushed down to the PostJoinCursor: d3 IN (a,b)
2. If we are unnesting on a virtual column involving multiple columns, the filter cannot be pushed into the left data source and appears only on the PostJoinCursor.
select*from foo, UNNEST(ARRAY[dim1,dim2]) as u(d12) where d12 IN (a,b) and m1 <10Filters pushed down to the left data source: m1 <10 (as unnest ison a virtual column it cannot be added to the pre-filter)Filters pushed down to the PostJoinCursor: d12 IN (a,b)
3. If there is an OR filter involving unnested and regular columns, they are transformed first using the regular column to be pushed into the left data source while the entire filter now appears on the PostJoinCursor.
select*from foo, UNNEST(dim3) as u(d3) where d3 IN (a,b) or m1 <10Filters pushed down to the left data source: dim3 IN (a,b) or m1 <10Filters pushed down to the PostJoinCursor: d3 IN (a,b) or m1 <10
4. If there is an OR filter using a virtual column on multiple input columns, the filter cannot be rewritten and pushed to the input data source and the entire filter appears on the PostJoinCursor
select*from foo, UNNEST(ARRAY[dim1,dim2]) as u(d12) where d12 IN (a,b) or m1 <10Filters pushed down to the left data source: NoneFilters pushed down to the PostJoinCursor: d12 IN (a,b) or m1 <10
Sum of parts
With the entire process, we can now write UNNEST queries in Druid. Here is an example spec to ingest data
And here are some example queries for UNNEST. We do support multiple levels of unnesting. Give it a try, and let us know how UNNEST helps solve your use case.
-- UNNEST on constant expressionselect*from UNNEST(ARRAY[1,2,3]) as ud(d1) where d1 IN ('1','2')-- UNNEST a single column from left datasourceselect dim3,foo.d3 from"numFoo", UNNEST(MV_TO_ARRAY("dim3")) as foo(d3)-- UNNEST an expression from left datasourceselect*from"numFoo", UNNEST(ARRAY["dim4","dim5"]) as foo(d45)-- UNNEST on a query datasourceselect*from (select*from"numFoo"where dim2 IN ('a', 'ab') LIMIT4), UNNEST(MV_TO_ARRAY("dim3")) as foo(d3)-- UNNEST on a join datasourceSELECT d3 from (SELECT*from druid.numfoo JOIN (select dim2 as t from druid.numfoo where dim2 IN ('a','b','ab','abc')) ON dim2=t), UNNEST(MV_TO_ARRAY(dim3)) as unnested (d3)-- UNNEST of an UNNESTselect*from"numFoo", UNNEST(MV_TO_ARRAY("dim3")) as ud(d3), UNNEST(ARRAY[dim4,dim5]) as foo(d45)with t as (select*from"numFoo", UNNEST(MV_TO_ARRAY("dim3")) as ud(d3))select*from t,UNNEST(ARRAY[dim4,dim5]) as foo(d45)-- UNNEST with filtersselect*fromfrom"numFoo", UNNEST(MV_TO_ARRAY("dim3")) as foo(d3) where m1 <10and d3 IN ('b','d')select*fromfrom"numFoo", UNNEST(MV_TO_ARRAY("dim3")) as foo(d3) where d3!='d'select*fromfrom"numFoo", UNNEST(MV_TO_ARRAY("dim3")) as foo(d3) where d3 >'b'and d3 <'e'
UNNEST was made possible by the team at Imply and I owe a huge shoutout to Eric Tschetter, Gian Merlino, Abhishek Agarwal, Rohan Garg, Paul Rogers, Clint Wylie, Brian Le and Karthik Kasibhatla for helping me bring UNNEST out to the Druid community.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...