Introducing incremental encoding for Apache Druid dictionary encoded columns
Sep 27, 2023
Clint Wylie
Query performance at scale is one of the most important areas of Apache Druid to work on; it is what allows you to create interactive UIs that can slice and dice billions to trillions of rows in real-time. It is one of the primary focus areas for any change to query processing, where squeezing additional milliseconds here and there off of processing time can add up to quite a large improvement. It’s very satisfying work, though always a bit risky since sometimes experiments do not pay off as we hope.
In this post I am going to deep dive on a recent engineering effort: incremental encoding of STRING columns. In preliminary testing, it has shown to be quite promising at significantly reducing the size of segments, making more effective use of the same amount of hardware, at little to no performance cost.
A quick introduction to segments
Segment files
At ingestion time, Druid partitions table data into files called segments, first based on time, and then optionally by ranges or hashes of values contained in the input rows.
Segments are distributed among data nodes for query processing ahead of time, where they are memory mapped to provide an efficient way for the query processing engine to access data during execution.
Memory mapping
Memory mapping in the host operating system ‘maps’ the bytes of a file to a continuous virtual memory range, making the file appear as if it were just another chunk of memory. When data is read, it is ‘paged’ into physical memory in a cache that resides in the ‘free space’. It stays here, allowing re-use if it is read again, or if all the space is occupied is automatically evicted if other segments are read, or if other processes need to use the space.
The effects are particularly noticeable when there are repeated reads of the same data: parts of the files are retained in the page cache and memory read speeds are typically still an order of magnitude higher than disk read speeds. The ‘ideal’ historical process would have available as much free memory space as has been allocated for segment cache meaning all segments it is serving could be stored in this page cache.
In practice this isn’t usually feasible, so the ratio of free space to disk cache is typically chosen to best fit the use case and desired performance characteristics of the cluster.
Dictionary encoding
As a columnar format, segment files consist primarily of contiguous regions corresponding to the parts of individual columns.
A string-type column typically consists of 3 parts.
Since string value sizes vary from row to row, dictionary encoding is employed, where each distinct value is placed into a sorted dictionary and assigned an integer identifier representing its position in the sorted set of values. The actual column part we store in the segment then consists of a series of integers that map to the values in the dictionary, rather than the values themselves.
Besides the integer dictionary id column and the value dictionary, the third part consists of bitmap value indexes ordered identically to the value dictionary, where the set bits of the bitmap correspond to which rows of the integer column contain that dictionary identifier.
We store things like this for a few reasons. First, using dictionary encoding makes random access of individual rows an efficient computation. Integers are a fixed width, so we can compute the offset in the integer column for a specific row in code simply by multiplying the number of bytes per value by the row number.
The integer column parts are stored in fixed size compressed blocks and use a byte packing strategy to use the smallest number of bytes which can represent all values, so we can also compute which block a particular row belongs to in order to decompress it, and then seek to the desired row.
With this in mind, the value dictionary itself also needs to have three important characteristics to perform well for both value lookup and filtering:
Random ordered value lookup of the integer identifiers must be fast. This happens when the column itself is being selected and will appear in the query results, where the integer identifiers are replaced with their actual value in row order.
Druid needs to be able to quickly reverse lookup the dictionary identifier from an actual value, since filtering a column needs to be able to rapidly check if the value is contained within the dictionary. Certain types of filters, such as ranges, can use the fact that the dictionary is sorted to quickly find all of the values which fall into the desired range to select their associated value bitmap indexes. Since the values are sorted, we can do this with a binary search.
The dictionary must be easy to iterate over the entire set of values efficiently. Filters that cannot exploit features of the dictionary being sorted instead rely on being able to iterate over the entire set of values to test if each value satisfies the predicate to match the filter, computing the set of values which we can utilize the indexes to prune the overall set of rows to be scanned.
A new approach: front coding
Maximum performance for segment processing is achieved when a large number of segment files are kept ‘hot’ in the page cache in order to avoid reading from disk. Thus, nearly anything we can do to shrink overall segment size can have sizable macro effects: with smaller segments, larger number of rows to reside in the same amount of page cache.
A lot of work is already done by Druid already to make string columns small. It compresses the dictionary id integer column using LZ4, indexes are compressed using Roaring, however dictionary values are stored as plain uncompressed UTF8 strings.
The introduction of nested columns to Druid, which use value dictionaries that are shared between the nested fields, was the catalyst to investigate strategies to shrink the value dictionary overall. Could we add a technique to save some extra space?
Because of this shared nature, the dictionaries of nested columns can have significantly higher cardinality than regular strings, making them even more likely to take advantage of any size improvements we might be able to uncover. This topic is worth a full discussion of its own, but I’ll save that for another day.
Back in 2017, Roman Leventov proposed using incremental encoding to store string value dictionaries, so I started there. Looking into the issue and reading the associated papers, I set off to explore using an incremental encoding strategy called ‘front-coding’, which involves tracking the length of common prefixes of values so that only the suffix needs to be stored.
To retain our desired dictionary properties discussed earlier, we divide the values into buckets which contain a fixed number of values. Fixed buckets allow Druid to quickly determine which bucket a dictionary id will be stored in, while still allowing it to perform binary search by searching among the first values of each bucket and then performing a linear scan to locate a value within the bucket, and everything remains easy to iterate for those use cases involving iteration.
Implementation details
My first prototype of a front-coded value dictionary (‘V0’) in 2022 deviated a bit from the standard representation. Values were stored in the buckets as a prefix on the first value of the bucket rather than the immediately preceding value because it was a lot easier to implement, and I needed to prove if performance was competitive with the standard UTF8 encoded implementation. After proving feasibility, a better ‘V1’ was added that switched to storing the values in a more typical manner, where the values are stored based on the prefix of the preceding value.
Digging down to the code level, Druid defines an interface called Indexed which is used as the definition for value dictionary implementations (among other things). So, the primary code change was adding a new FrontCodedIndexed, containing the methods for reading and writing the buckets of values. We adapted ‘variable byte’ encoding for integer values from JavaFastPFOR to save a little extra space when writing both string value lengths as well as prefix lengths. Since these integers had no need for random access since they were embedded in the bucket values, each value having a variable size was not problematic.
Front coded indexed layout:
version
bucket size
has null?
number of values
size of “offsets” + “buckets”
“offsets”
“buckets”
byte
byte
byte
vbyte int
vbyte int
int[]
bucket[]
The ‘offsets’ store the starting location of all buckets beyond the first bucket (whose offset is known to be the end of the ‘offsets’ position). The ‘offsets’ are stored as plain integer values instead of vbyte encoded to allow for fast access of the bucket positions, but are probably a good candidate for delta encoded byte packing to further decrease their size.
bucket layout:
first value
prefix length
fragment
…
prefix length
fragment
blob
vbyte int
blob
…
vbyte int
blob
blob layout:
blob length
blob bytes
vbyte int
byte[]
Getting a value first picks the appropriate bucket, finds its offset in the underlying buffer, then scans the bucket values to seek to the correct position of the value within the bucket in order to reconstruct it using the prefix lengths, working backwards through the bucket until the value is completed.
Finding the index of a value involves binary searching the first values of each bucket to find the correct bucket, then a linear scan within the bucket to find the matching value (or negative insertion point -1 for values that are not present). As mentioned above, the binary search behavior of returning the actual position or theoretical insertion point is used to help find values which fall within a range to use with range based filters.
The value iterator reads an entire bucket at a time, reconstructing the values into an array to iterate within the bucket before moving onto the next bucket as the iterator is consumed.
Performance and storage efficiency analysis
Since front-coding is a ‘value aware’ encoding, the size difference can vary quite a bit depending on the underlying source data. Data with large common prefixes, such as URLs and file paths, can have very dramatic space savings: up to 40% in some cases..
The benefit varies with other kinds of data. UUIDs and other very unique data sets see as little as 1% difference. Very low cardinality columns also see only minor benefits, and when the cardinality is lower than the bucket count, it can be even worse than using plain UTF8.
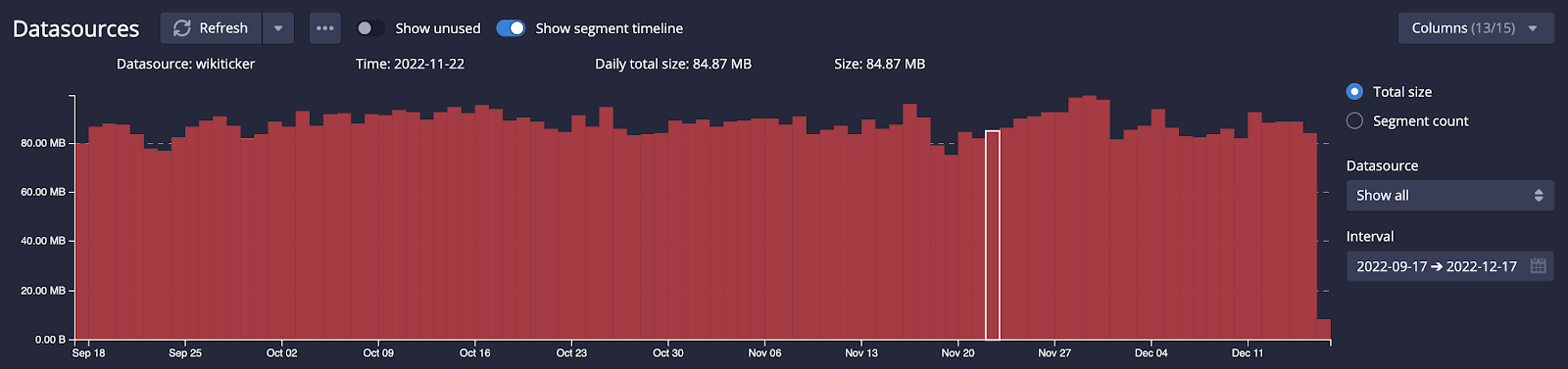
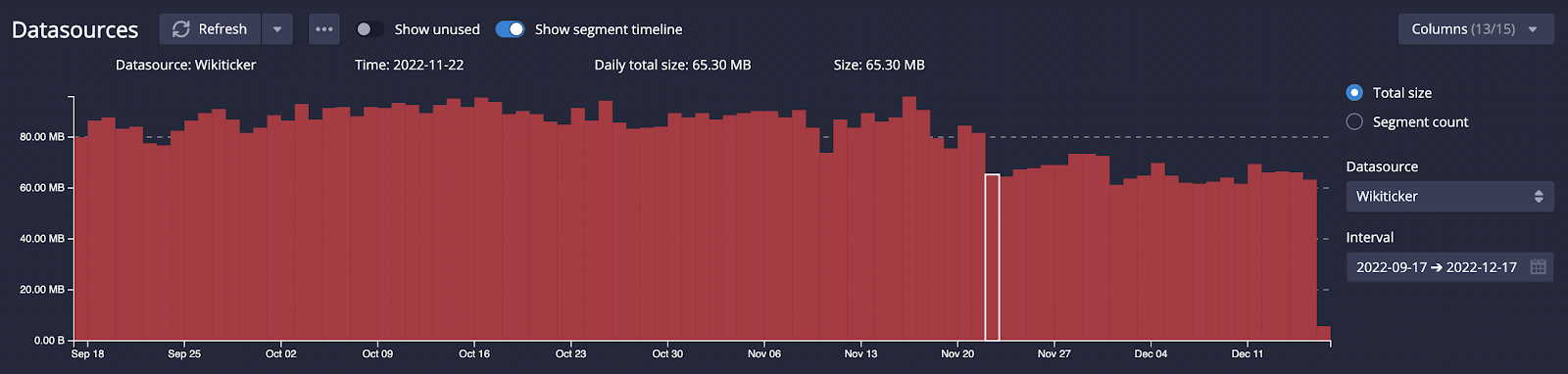
Using the classic Druid example of Wikipedia edits, the size savings of even using version 0 of the format were immediately obvious:
The step up from version 0 to version 1 gave small, but noticeable improvements, too – even in this very small example data set.
In terms of read performance, the difference between ‘UTF8’ and ‘frontCoded’ encoding is negligible, down to a handful of nanoseconds depending on the operation. In some cases things are even faster due to the smaller overall size, not to mention the time spent optimizing this implementation to minimize the amount of data that actually needs to be read: the front-coded implementation defers translating the raw bytes into Java strings until it is absolutely necessary.
The complete set of benchmarks is available in the PR descriptions for v0 and v1. These focus on the micro level, measuring raw speeds for individual queries in the ‘hot’ case where data is cached in memory. What these benchmarks do not adequately capture are the macro effects that overall smaller segment sizes provide, more rows are able to fit in the same amount of memory, which should reduce overall disk reads. Smaller overall segments also allow us to fit more data in the same amount of compute hardware.
Trying it for yourself
A new property stringDictionaryEncoding is available in the tuningConfig’s indexSpec.
Here are some examples of setting stringDictionaryEncoding, using ‘version 1’ with bucket sizes 4 or 16 respectively.:
Take care when applying this new encoding: segments written like this will be unreadable by Druid versions older than 26.0.0. That is part of the reason why this mode is not the default yet.
What’s next?
Front-coding seems to provide a nice improvement to overall segment sizes in Apache Druid. I am proposing making front encoding the default in Druid in time for Druid 28, where backwards compatibility concerns will be resolved at least for operators migrating from Druid 26 or 27. Before this change is merged, I also intend on allowing defining a system default indexSpec, so the behavior can be opted out of at a system level.
There is also a lot of room left for future work to continue iterating and improving the Druid segment format to get greater performance release-by-release.
There’s a new version of the original paper linked in PR 3922. Together with another paper from 2020, both of which detail additional (much fancier) improvements like Re-Pair, which uses an additional lookup to replace repeated fragments with smaller symbols.
I – and the rest of the project – are looking forward to investigating these techniques to determine at what cost additional size improvements can be gained.
Additionally, it seems to be ideal to be able to vary which encoding and with what parameters are used on a per column basis instead of setting it at the segment level. This is actually true for the other forms of compression as well, and both could be addressed as a follow-up improvement. To fully automate this, it would also entail collecting statistics at indexing time, so that we could better determine the best storage strategy using inputs such as value cardinality, value distribution, etc.Try it out in your clusters, I’d love feedback about where it works and where it doesn’t to help guide the parts I focus on next. You can find me on the Apache Druid slack in the #dev channel, or start a thread on the dev mailing list, dev@druid.apache.org.
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....