Apache Kafka, Flink, and Druid: Open Source Essentials for Real-Time Data Applications
Sep 15, 2023
David Wang
It’s not easy for data teams working with batch workflows to keep up with today’s real-time requirements. Why? Because the batch workflow – from data delivery and processing to analytics – involves a lot of waiting.
There’s waiting for data to be sent to an ETL tool, waiting for data to be processed in bulk, waiting for data to be loaded in a data warehouse, and even waiting for the queries to finish running.
But there’s a solution for this from the open source world. Apache Kafka, Flink, and Druid, when used together, create a real-time data architecture that eliminates all these wait states. In this blog post, we’ll explore how the combination of these tools enables a wide range of real-time applications.
Architecting real-time applications
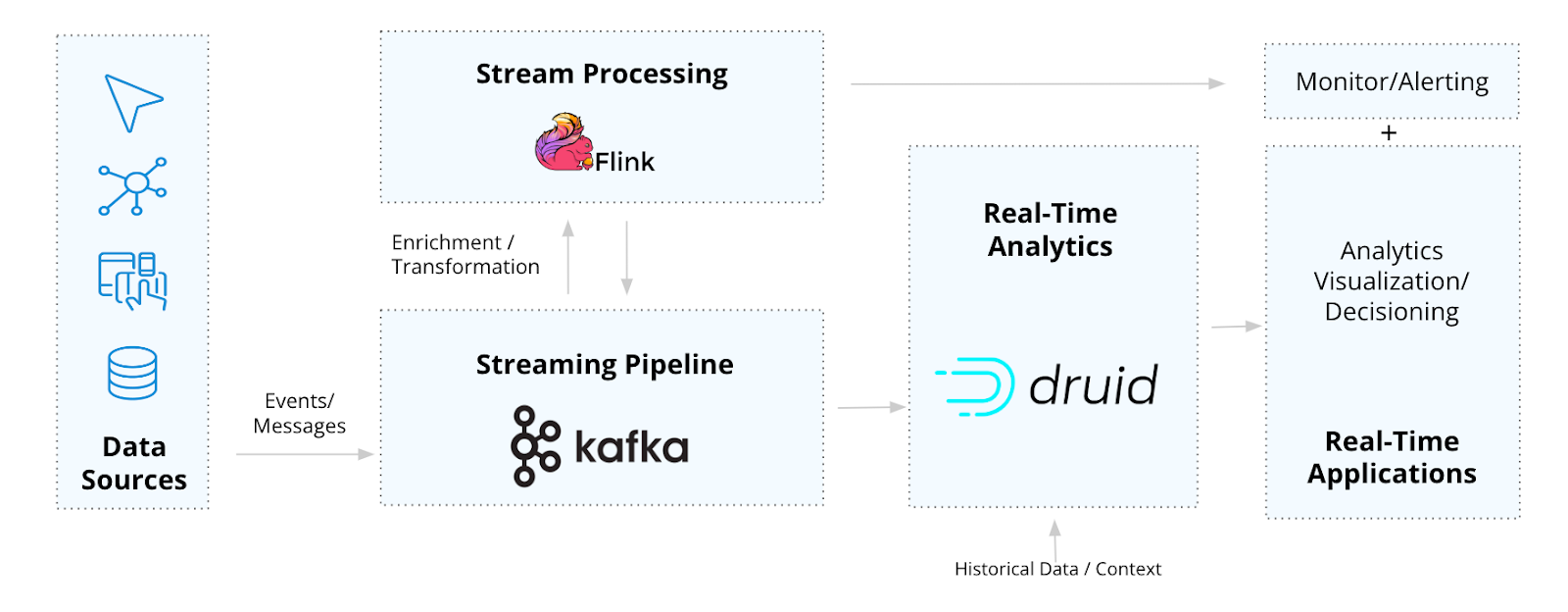
Kafka-Flink-Druid creates a data architecture that can seamlessly deliver the data freshness, scale, and reliability across the entire data workflow from event to analytics to application.
Open-source data architecture for real-time applications
Companies like Lyft, Pinterest, Reddit, and Paytm use the three together because they are each built from complementary stream-native technologies that together handle the full gamut of real-time use cases.
This architecture makes it simple to build real-time applications such as observability, IoT/telemetry analytics, security detection/diagnostics, customer-facing insights, and personalized recommendations.
Let’s take a closer look at each and how they can be used together.
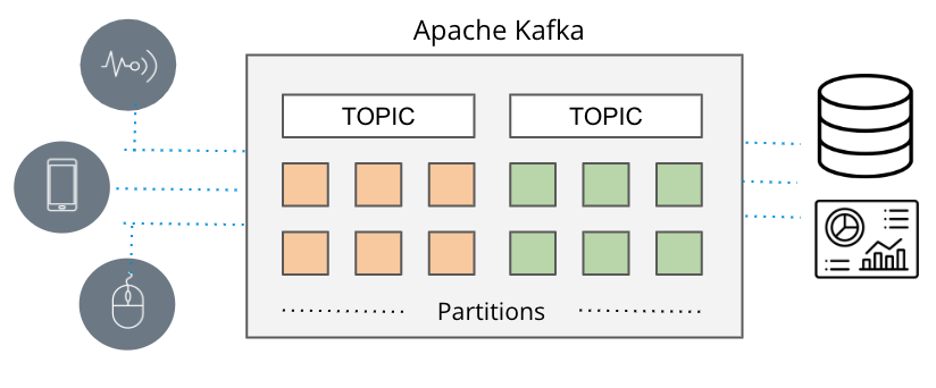
Streaming pipeline: Apache Kafka
Apache Kafka has emerged over the past several years as the de facto standard for streaming data. Prior to it, RabbitMQ, ActiveMQ and other message queuing systems were used to provide various messaging patterns to distribute data from producers to consumers, but with scale limitations.
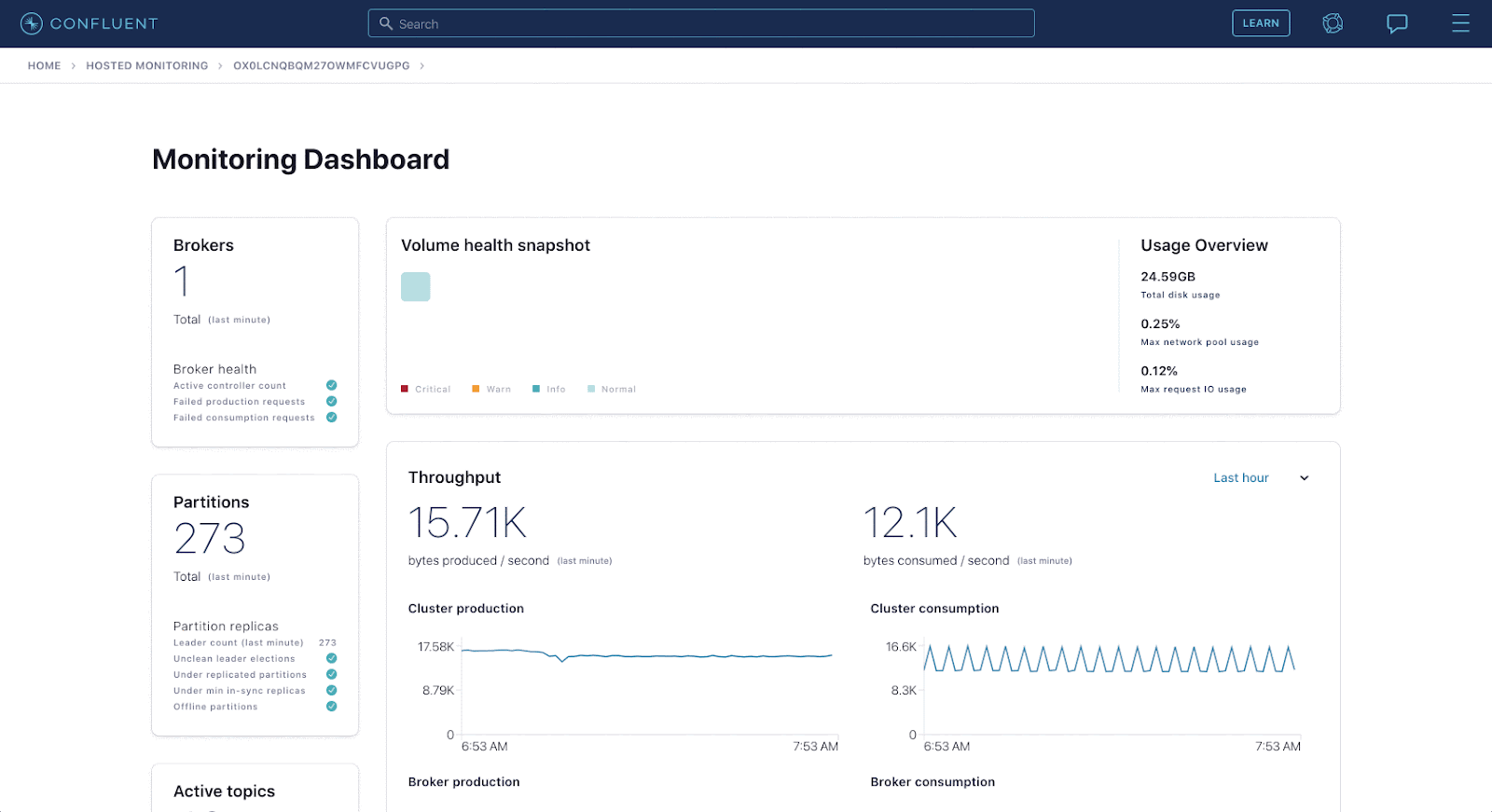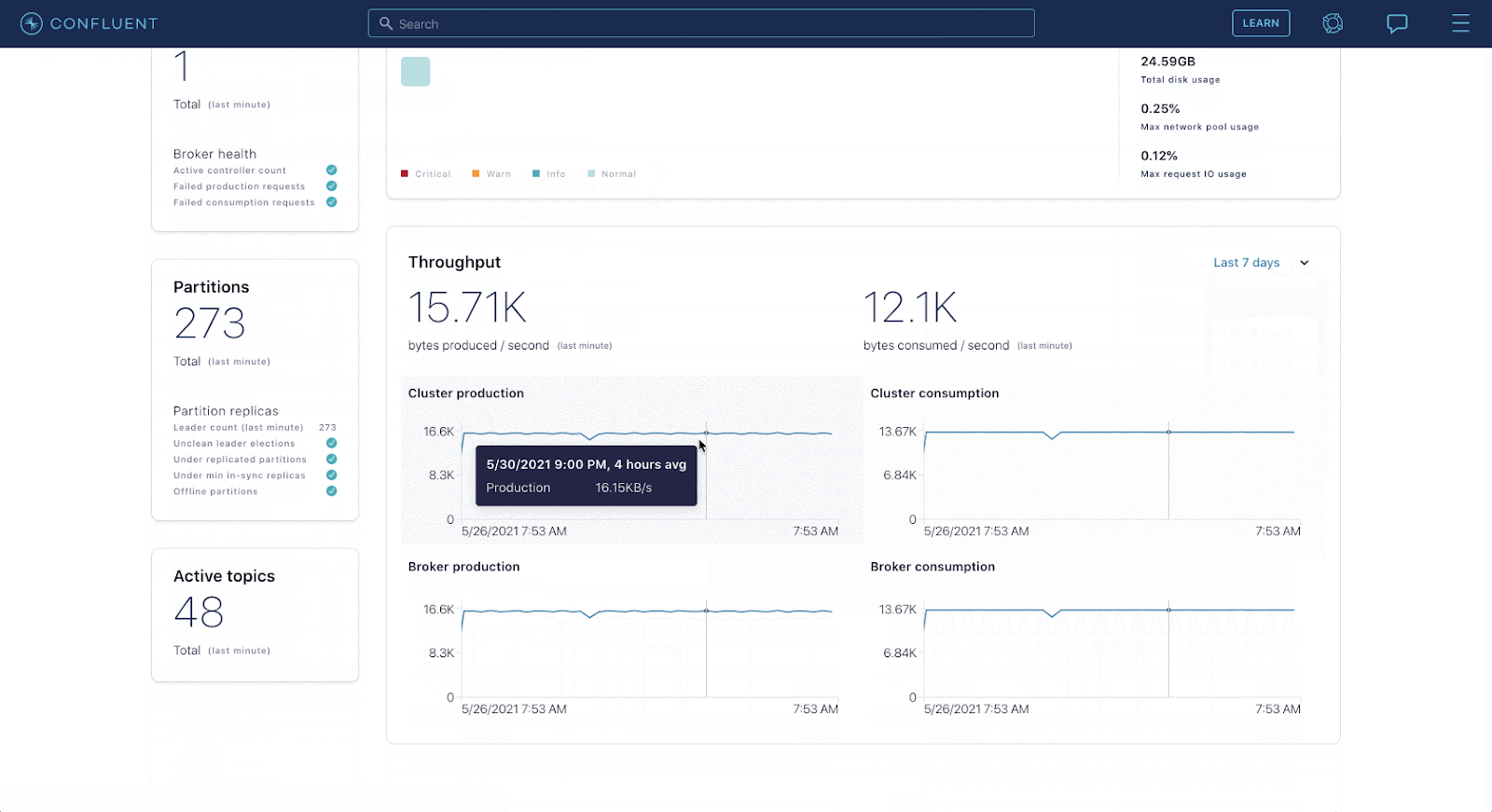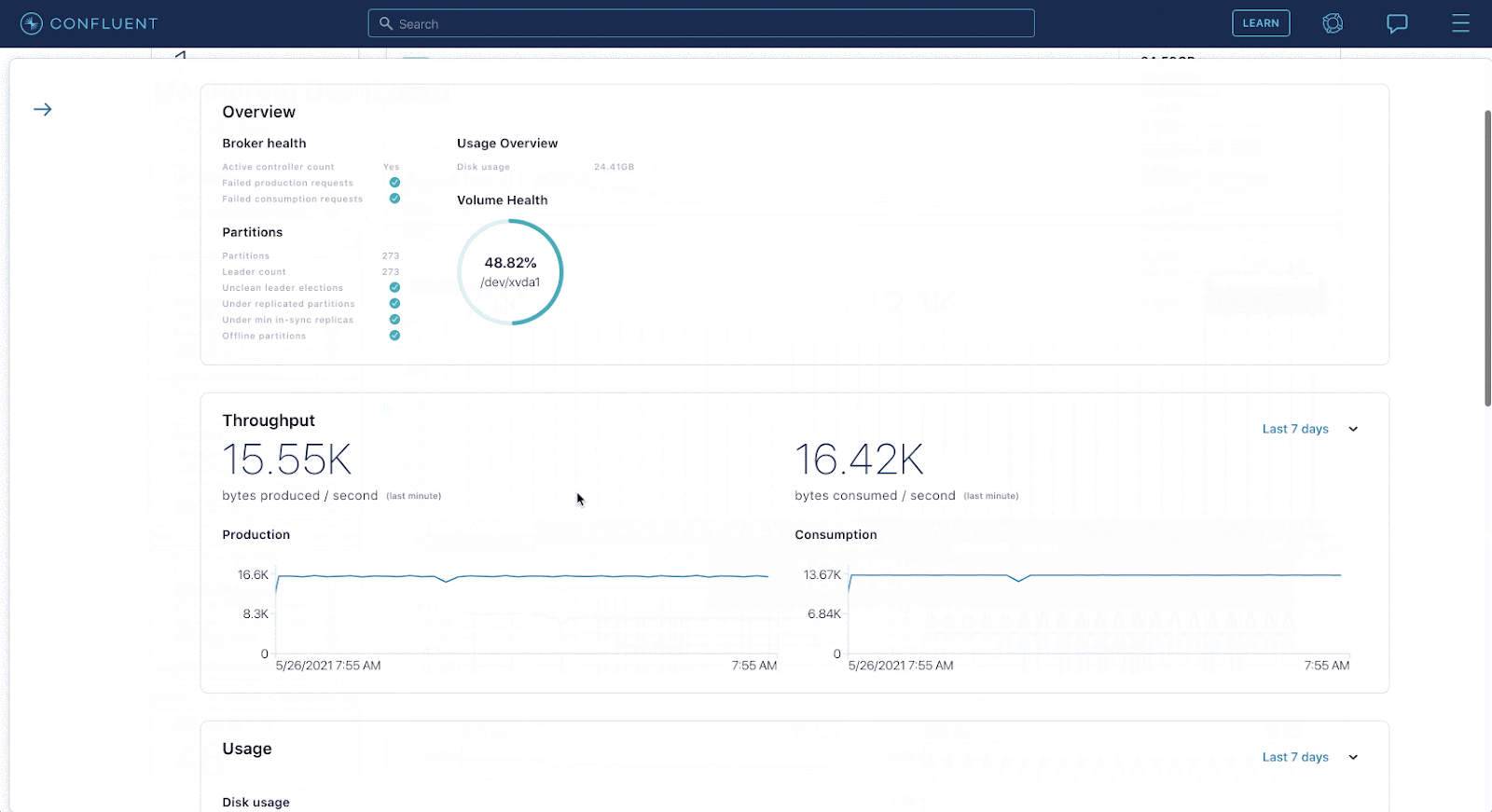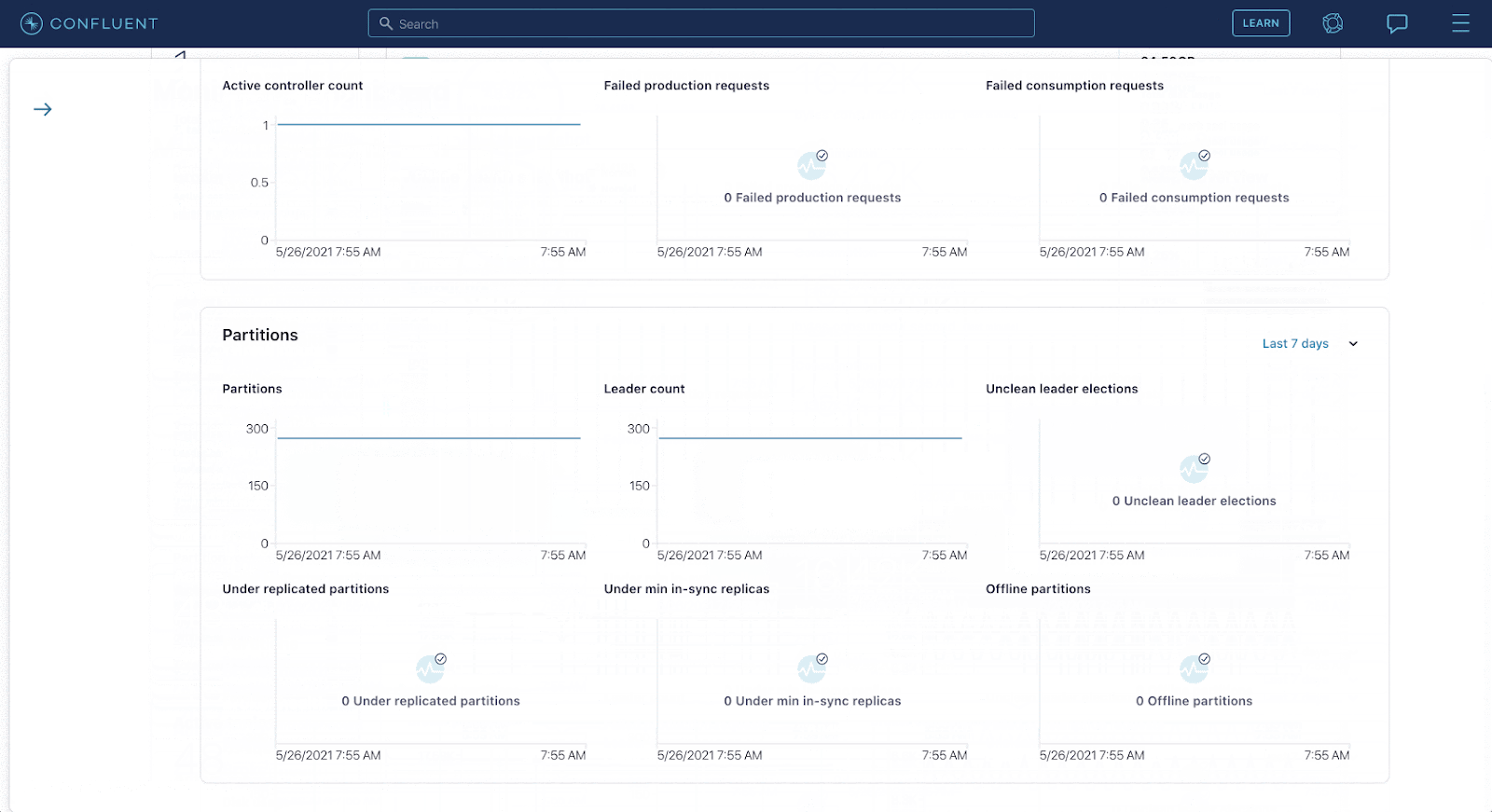
Fast forward to today, Kafka has become ubiquitous, with at least 80% of the Fortune 100 using it. And it’s because Kafka’s architecture extends well beyond simple messaging. The versatility of its architecture makes Kafka very well suited for streaming at massive ‘internet’ scale with fault tolerance and data consistency to support mission-critical applications – and its wide range of connectors via Kafka Connect integrate with any data sources.
Apache Kafka as the streaming platform for real-time data
Stream processing: Apache Flink
With Kafka delivering real-time data, the right consumers are needed to take advantage of its speed and scale in real-time. One of the popular choices is Apache Flink.
Why Flink? For starters, Flink’s a high throughput, unified batch and stream processing engine, with its unique strengths lying in its ability to process continuous data streams at scale. Flink is a natural fit as a stream processor for Kafka as it integrates seamlessly and supports exactly-once semantics, guaranteeing that each event is processed exactly once, even with system failures.
Simply put, connect to a Kafka topic, define the query logic, and then emit the result continuously – ie. ‘set it and forget it’. This makes Flink pretty versatile for use cases where immediate processing of streams and reliability are essential.
Here are some of Flink’s common use cases:
Enrichment and transformation
If a stream needs to undergo any data manipulation (e.g. modifying, enhancing, or restructuring data) before it can be used, Flink is an ideal engine to make changes or enhancements to those streams as it can keep the data fresh with continuous processing.
For example, let’s say we have an IoT/telemetry use case for processing temperature sensors in a smart building. And each event coming into Kafka has the following JSON structure: { “sensor_id”: “SensorA”, “temperature”: 22.5, “timestamp”: “2023-07-10T10:00:00” }.
If each sensor ID needs to be mapped with a location and the temperature needs to be in Fahrenheit, Flink can update the JSON structure to { “sensor_id”: “SensorA”, “location”: “Room 101”, “temperature_Fahreinheit”: 73.4, “timestamp”: “2023-07-10T10:00:00” }, emitting it directly to an application or sending it back to Kafka.
Illustrative example of Flink’s data processing as a structured table for clarity
An advantage for Flink here is its speed at scale to handle massive Kafka streams in real-time. Also, enrichment/transformation is often a stateless process where each data record can be modified without needing to maintain persistent state, making it minimal effort and highly performant too.
Continuous monitoring and alerting
The combination of Flink’s real-time continuous processing and fault tolerance also makes it an ideal solution for real-time detection and response across various critical applications.
When the sensitivity to detection is very high – think sub-second – and the sampling rate is also high, Flink’s continuous processing is well suited as a data serving layer for monitoring conditions and triggering alerts and action accordingly.
An advantage for Flink with alerts is that it can support both stateless and stateful alerting. Threshold or event triggers like “notify the fire department when temp reaches X” are straightforward, but not always intelligent enough. So, in use cases where the alert needs to be driven by complex patterns that require remembering state – or even aggregating metrics (e.g. sum, avg, min, max, count, etc) – within a continuous stream of data, Flink can monitor and update state to identify deviations and anomalies.
Something to consider is that using Flink for monitoring and alerting involves continuous CPU to evaluate conditions against thresholds and patterns, which is different from say a database that only utilizes CPU during query execution. So it’s a good idea to understand if continuous is required.
Real-time analytics: Apache Druid
Apache Druid rounds out the data architecture, joining Kafka and Flink as the consumer of streams for powering real-time analytics. While it is a database for analytics, its design center and use is much different than that of other databases and data warehouses.
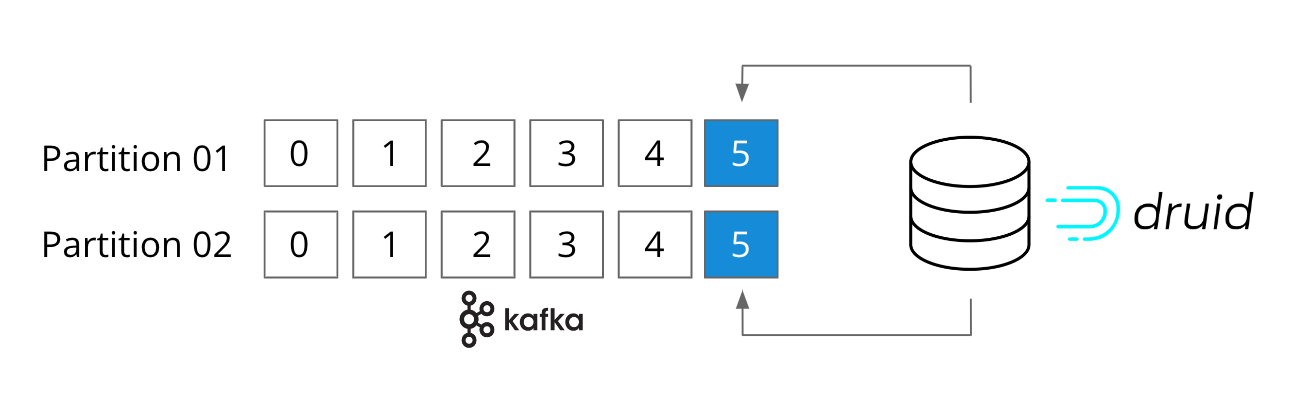
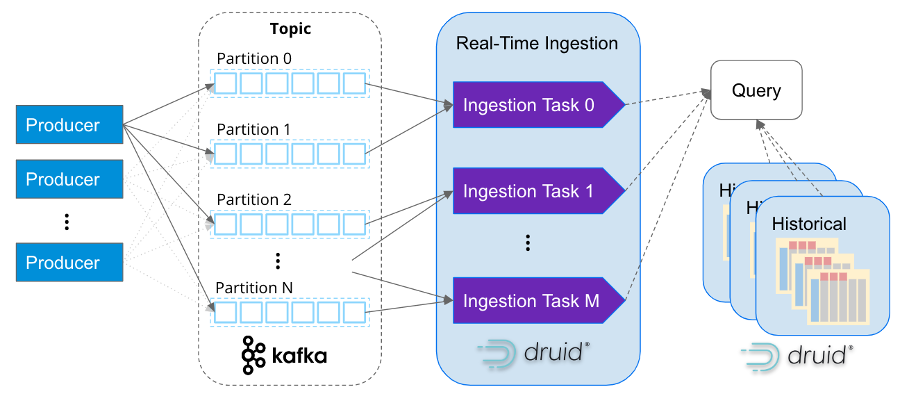
For starters, Druid is like a brother to Kafka and Flink. It too is stream-native. In fact, there is no connector between Kafka and Druid as it connects directly into Kafka topics and it supports exactly-once semantics. Druid is also designed for rapid ingestion of streaming data at scale and immediate querying of events, in-memory, on arrival.
How Apache Druid natively integrates with Apache Kafka for stream ingestion
On the query side of things, Druid is a high performance, real-time analytics database that delivers sub-second queries at scale and under load. If the use case is performance-sensitive and requires handling TBs to PBs of data (eg. aggregations, filters, GroupBys, complex joins, etc) with high query volume, Druid is an ideal database as it consistently delivers lightning fast queries and can easily scale from a single laptop to a cluster of 1000s of nodes.
This is why Druid is known as a real-time analytics database: it’s for when real-time data meets real-time queries. Here’s how Druid complements Flink:
Highly interactive queries
At its core, engineering teams use Druid to power analytics applications. These are data-intensive applications that include both internal (ie. operational) and external (ie. customer-facing) use cases across observability, security, product analytics, IoT/telemetry, manufacturing operations, etc. The applications powered with Druid generally have these characteristics:
Performant at scale: Applications that need sub-second read performance on analytics-rich queries against large data sets without pre-computation. Druid is highly performant even if the application’s users are arbitrarily grouping, filtering, and slicing/dicing through lots of random queries at TB-PB scale.
High query volume: Applications that demand high QPS for analytical queries. An example here would be for any external-facing application – ie. data product – where sub-second SLAs are needed for workloads producing 100s to 1000s of (different) concurrent queries.
Time-series data: Applications that present insights on data with a time dimension (a strength of Druid’s but not a limitation). Druid can process time-series data at scale very quickly because of its time partitioning and data format. This makes time-based WHERE filters incredibly fast.
These applications either have a very interactive data visualization / synthesized result-set UI with lots of flexibility in changing the queries on the fly (because Druid is that fast) or in many cases they are leveraging Druid’s API for query speed at scale to power a decisioning workflow.
Here’s an example of an analytics application powered by Apache Druid.
Credit: Confluent – Confluent Health+ dashboard
Confluent, the original creators of Apache Kafka, provide analytics to their customers via Confluent Health+. This application above is highly interactive and packed with insights on their customers’ Confluent environment. Under the cover, events are streaming into Kafka and Druid at 5 million events per second with the application serving 350 QPS.
Real-time with historical data
While the example above shows Druid powering a pretty interactive analytics application, you might be wondering “what’s love streaming got to do with it?” It’s a good question as Druid is not limited to streaming data. It’s very capable of ingesting large batch files as well.
But what makes Druid relevant in the real-time data architecture is that it can provide the interactive data experience on real-time data combined with historical data for even richer context.
While Flink is great at answering “what is happening now” (ie. emit the current status of a Flink job), Druid is in a technical position to answer “what is happening now, how does that compare to before, and what factors/conditions impacted that outcome”. These questions together are quite powerful as they, for example, can eliminate false positives, help detect new trends, and lead to more insightful real-time decisions.
Answering “how does this compare to before” requires historical context – a day, a week, a year or other time horizons – for correlation. And “what factors/conditions impacted the outcome” require mining through a full data set. As Druid is a real-time analytics database, it ingests streams to give the real-time insights but it also persists data so it can query historical data and all the other dimensions for ad-hoc exploration too.
How Druid’s query engine handles both real-time and historical data
For example, let’s say we are building an application that monitors security logins for suspicious behavior. We might want to set a threshold in a 5 minute window: ie. update and emit the state of login attempts. That’s easy for Flink. But with Druid, current login attempts can also be correlated with historical data to identify similar login spikes in the past that didn’t have security breaches. So the historical context here helps determine whether a present spike is indicative of a problem or just normal behavior.
So when you have an application that needs to present a lot of analytics – e.g. current status, variety of aggregations, grouping, time windows, complex joins, etc – on rapidly changing events but also provides historical context and explore that data set via a highly flexible API, that’s Druid’s sweet spot.
Flink and Druid Checklist
Flink and Druid are both built for streaming data. While they share some high-level similarities – both in-memory, both can scale, both can parallelize – their architectures are really built for entirely different use cases as we saw above.
Here’s a simple workload-based decision checklist:
Do you need to transform or join data in real-time on streaming data? Look at Flink as this is its “bread and butter” as it’s designed for real-time data processing.
Do you need to support many different queries concurrently? Look at Druid as it supports high QPS analytics without needing to manage queries/jobs.
Do the metrics need to be updated or aggregated continuously? Look at Flink for this because it supports stateful complex event processing.
Are the analytics more complex and is historical data needed for comparison? Look at Druid as it can easily and quickly query real-time data with historical data.
Are you powering a user-facing application or data visualization? Look at Flink for enrichment then send that data to Druid as the data serving layer.
In most cases, the answer isn’t Druid or Flink, but rather Druid and Flink. Each provides technical characteristics that make them together well suited to support a wide range of real-time applications.
Conclusion
Businesses are increasingly demanding real-time from data teams. And that means the data workflow needs to be reconsidered end-to-end. That’s why many companies are turning to Kafka-Flink-Druid as the de facto open-source data architecture for building real-time applications.
To try out the Kafka-Flink-Druid architecture you can download the open source projects here – Kafka, Flink, Druid – or simply get a free trial of the Confluent Cloud and Imply Polaris , cloud services for Kafka-Flink (Confluent) and Druid (Imply).
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....