At Imply, we’re excited to share the latest enhancements in Imply Polaris, our real-time analytics Database-as-a-Service (DBaaS) powered by Apache Druid®. Our commitment to refining your experience with Polaris is evident in these recent developments, focusing on improving data management efficiency, collaboration, and data transformation.
Quick Overview of Imply Polaris
For newcomers to Polaris, here’s a brief overview: Polaris kicks off with a Database-as-a-Service, powered by Apache Druid®. This service brings you all the performance advantages of Druid in a hassle-free, fully managed cloud environment. Think of it as the “easy button” for Druid, featuring built-in capabilities for seamless data ingestion and visualization. Within minutes, you can derive valuable insights from your data without the complexities of infrastructure setup. Polaris offers end-to-end data management, ensuring automatic tuning and continuous upgrades for optimal performance at every stage.
So, what’s new in store for you?
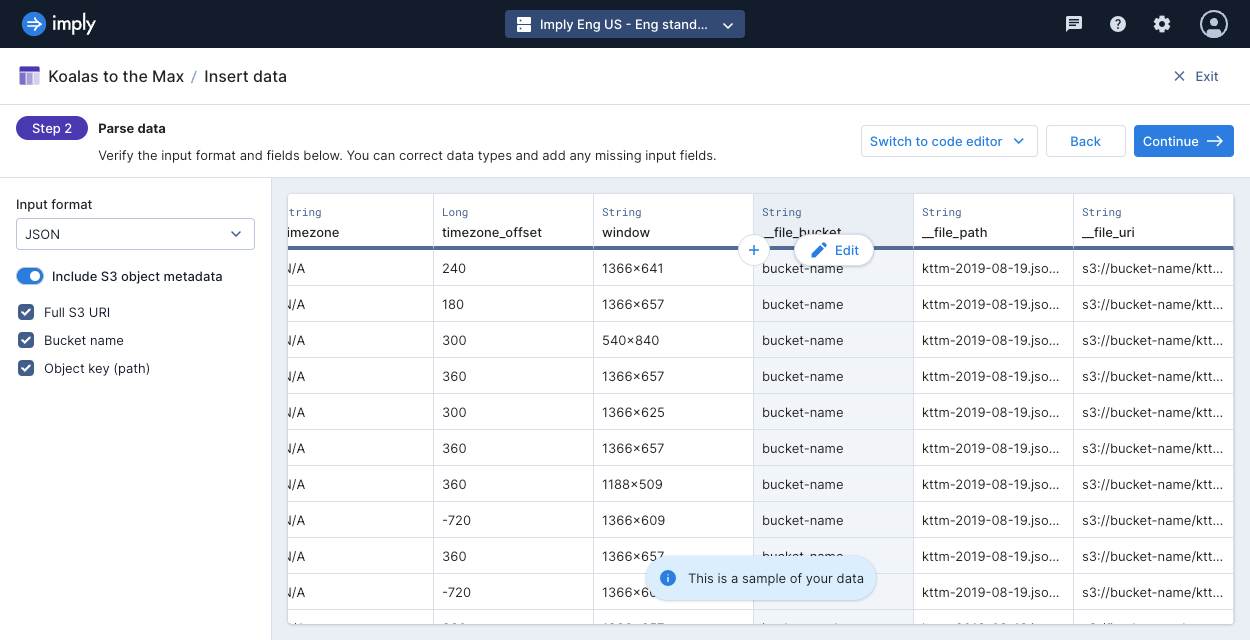
Added system fields to input sources for enhanced metadata management
For those who have ventured into data lakes, it’s often that table partitions form part of the file structure, with prefixes or folder names. In this release, you gain the capability to ingest this system information, including file names and object bucket store prefixes.
For those familiar with data lakes, table partitions often play a crucial role in the file structure, featuring prefixes or folder names. In this release, we’ve introduced the capability to incorporate system information, such as file names and object bucket store prefixes.
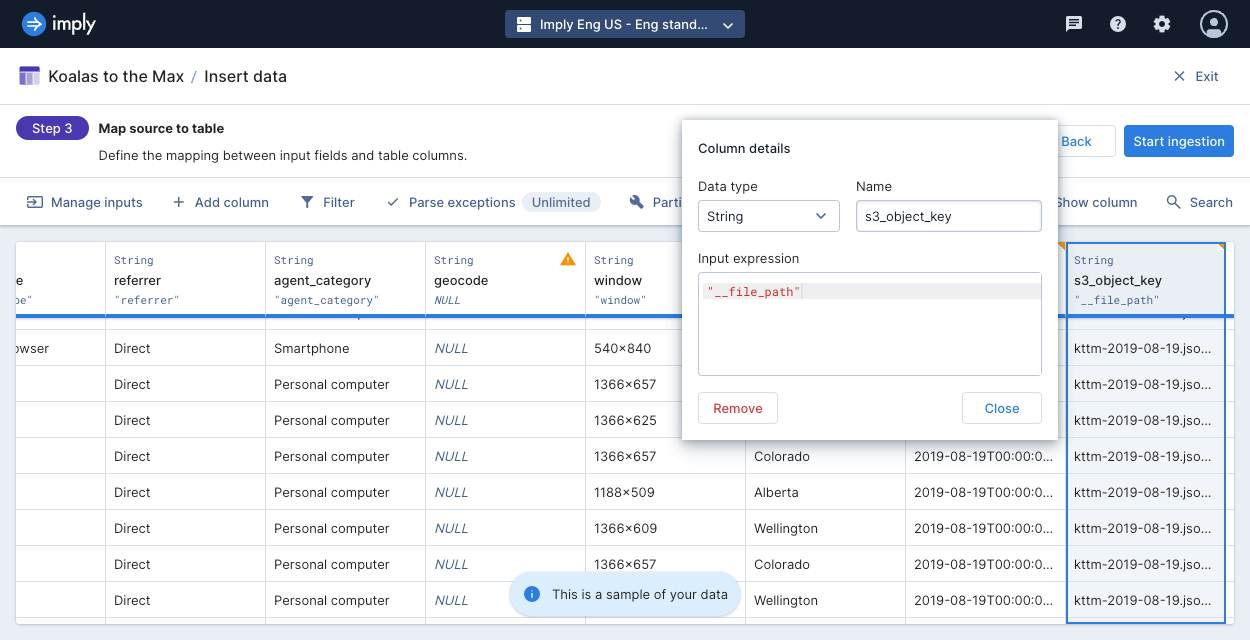
Polaris now supports the ingestion of data from system fields, including S3 metadata like the Uniform Resource Identifier (URI), bucket name (i.e., storage location), and the key identifying the object within that bucket. This improvement streamlines the integration, management, and analysis of data from Amazon S3, offering a more efficient and user-friendly experience.
An illustrative example is the simplified process of changing the column (i.e., bucket) name by updating the ‘Name’ field in the column editor.
In summary, this Polaris update simplifies the management and comprehension of data stored in Amazon S3. It introduces convenient methods to include essential details about each piece of data during the ingestion process, resulting in a more streamlined and user-friendly experience.
EARLIEST and LATEST functions for enhanced data analysis
Imply Polaris’s support for EARLIEST_BY and LATEST_BY in input expressions brings significant benefits to data processing and aggregation. This feature facilitates timestamp-based aggregation, enabling users to efficiently combine rows with the same timestamp and dimension values while selecting the earliest or latest value for a specific input field. The flexibility extends to dimension-specific processing, allowing users to store the earliest value uniquely for each bucket, providing fine-grained control over data storage based on different dimensions. This capability is particularly valuable for time-series data, where maintaining data integrity and capturing historical or initial values are crucial for accurate analysis and reporting.
In essence, Imply Polaris’s enhancement streamlines data ingestion by offering a powerful mechanism for customizing how data is aggregated and stored based on timestamp and dimension values. This not only improves the precision of data processing but also provides a more adaptable and efficient solution for users dealing with diverse use cases, enhancing the platform’s overall capabilities in handling complex data aggregation requirements.
Import and export data cube and dashboard definitions for enhanced collaboration
Imply Polaris’ built-in visualization capabilities now allow you to manually import and export JSON definitions for data cubes and dashboards. This is particularly useful for two main reasons:
Portability Between Projects: Easily transfer data cubes and dashboards between projects, promoting seamless collaboration and the sharing of analytical configurations across different initiatives or teams within the organization. This feature enhances overall flexibility in project management, allowing for a smooth transition of analytical assets.
Creation of Manual Backups: Help ensure data integrity and data continuity with the ability to manually export JSON definitions allows users to create backups of data cubes and dashboards. Storing configurations in a JSON format provides an additional layer of data protection, enabling users to revert to specific configurations in case of accidental changes or data loss.
We’re excited to introduce a practical new feature in Imply Polaris – Audit Logs. Going beyond routine tracking, this feature plays an important role in enhancing security and oversight within your organization. By capturing essential user management and authentication events, Audit Logs can help detect anomalous activities, investigate privilege misuse, and efficiently address security incidents. Utilizing this new capability ensures compliance and provides organizations with effective tools to maintain a secure environment, strengthening data governance in Imply Polaris.
SQL PIVOT and UNPIVOT for enhanced data transformation
The introduction of SQL PIVOT and UNPIVOT operators in Polaris enhances data transformation capabilities, facilitates aggregation and restructuring, and aligns with SQL standards, ultimately contributing to more powerful and flexible data analysis and reporting.
With these operators, you can easily reshape and aggregate your data. PIVOT helps you turn rows into columns, useful for customizing data presentation. It’s great for organizing data to match your analysis or reporting needs.
PIVOT also enhances aggregation, letting you summarize specific columns. This is handy when you need a structured view of your data for in-depth analysis.
On the other hand, UNPIVOT simplifies restructuring by transforming column values into rows. It’s perfect for converting data from a columnar format to a more tabular one, making analysis more straightforward.
Learn More and Get Started for Free!
Ready to explore these new features? Start your journey with a free 30-day trial of Imply Polaris – no credit card required! Or, take Polaris for a test drive and experience firsthand how easy it is to build your next analytics application.
If you have questions or want to learn more, set up a demo with an Imply expert. We’re here to help you make the most of Imply Polaris for your real-time analytics needs.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...