Oracle
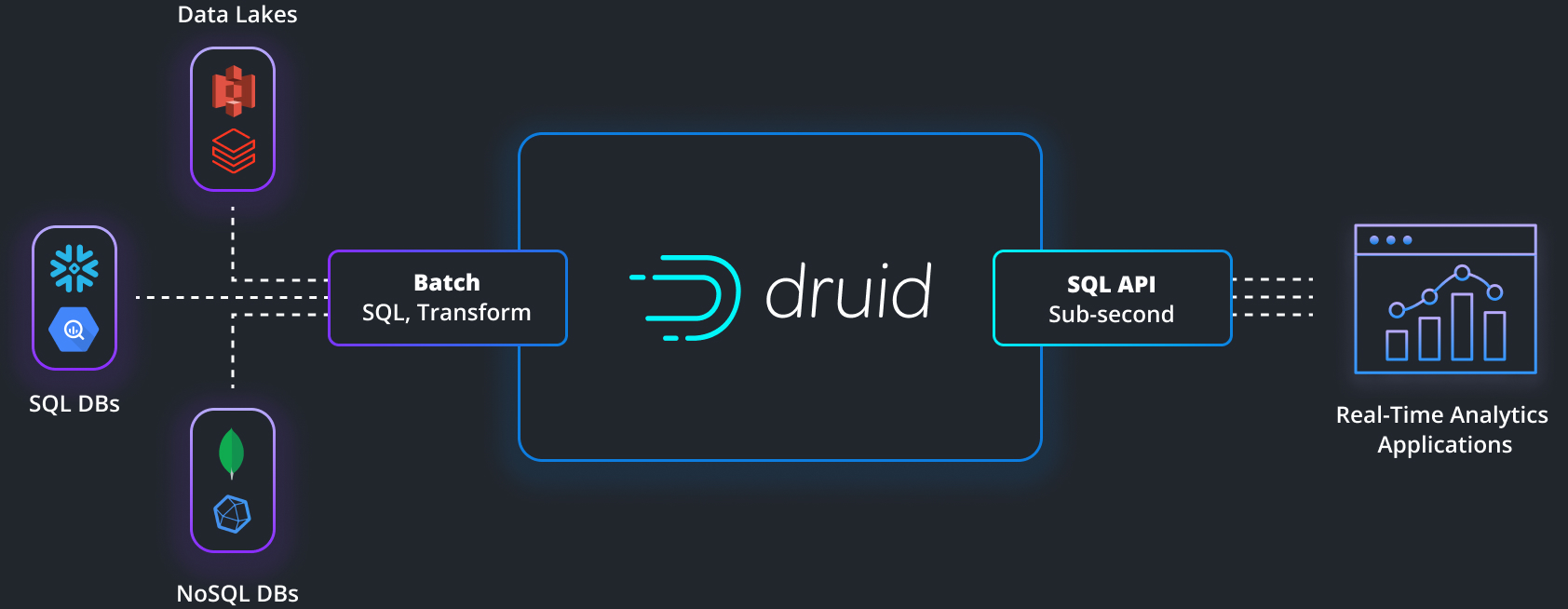
The initial copy of the data from Oracle can be completed using Oracle SQL developer which provides a wizard for exporting data and metadata from the database. That data is then ingesting into Druid via SQL. Subsequent changes to the Oracle analytical data can then be replicated in Druid using LAST_UPDATED date time field to determine the updated or new records along with code to facilitate the migration, using various ELT tools or the Debezium Oracle connector to automate the CDC (Change Data Capture process).