“Guess how many jelly beans are in this jar!”—a popular contest based on the art of estimation. If you’re familiar with the age-old game, you’ll know that while there is an exact number of jelly beans, it’s often the person with the closest guess who wins the prize.
There are plenty of ways to guess the number of beans (seriously, a quick internet search will lead you down quite the rabbit hole). Of course, getting the exact number requires dumping out the jelly beans and counting them one by one, but who has time for that? The fastest method is to use approximation: counting, say, the number of jelly beans on the bottom layer of the jar and multiplying by the number of jelly bean layers stacked on top. While it may give only an approximate count, it will take much less time to achieve compared to an exact count.
A common use case in data analytics is to count the distinct number of values within a group. For example, I may want to know how many unique customers bought an item at each one of my stores so I can improve my marketing precision. For BI and batch-based analytics, the following SQL expression would work well:
SELECT store, COUNT(DISTINCT customer_id) FROM table_name … GROUP BY store;
You can use sketches in Polaris during query with a SQL statement such as:
SELECT store, APPROX_COUNT_DISTINCT_HLL(customer_id) FROM table_name … GROUP BY store;
While this is already quite fast when compared to the standard COUNT(DISTINCT customer_id), it does require significant storage and processing during query time. Using sketches at ingestion time summarizes input data, which improves rollup, reduces memory footprint, and increases query performance. Additionally, sketches allow for set operations, so you can go beyond the traditional COUNT(DISTINCT customer_id)and also conduct analyses involving intersections and unions of your data.
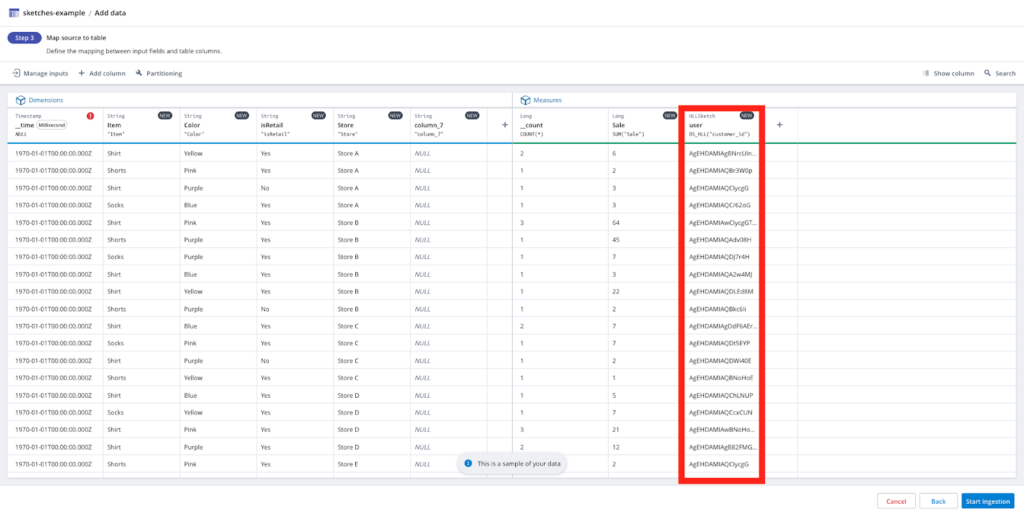
You can use sketches in Polaris during ingestion by defining a column in the table schema. For example, given a new column named user, you can assign it to an HLL Sketch or Theta Sketch data type and map the input data to the table column using the appropriate SQL expression, such as DS_HLL(“customer_id”) or DS_THETA(“customer_id”). With the pre-computed user column, you can now use the following query for faster results:
SELECT store, APPROX_COUNT_DISTINCT_HLL(user) FROM table_name … GROUP BY store
Enabling real time analytics with sketches in Polaris is one of the many ways in which we are powering the next generation of modern data analytics applications. To try it out yourself, sign up at signup.imply.io.
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...