Apache Druid
The real-time analytics database designed to power analytics applications at any scale, for any number of users, and across streaming and batch data.
- Capabilities
Druid can deliver sub-second queries on millions to trillions of rows through a unique storage and compute relationship.
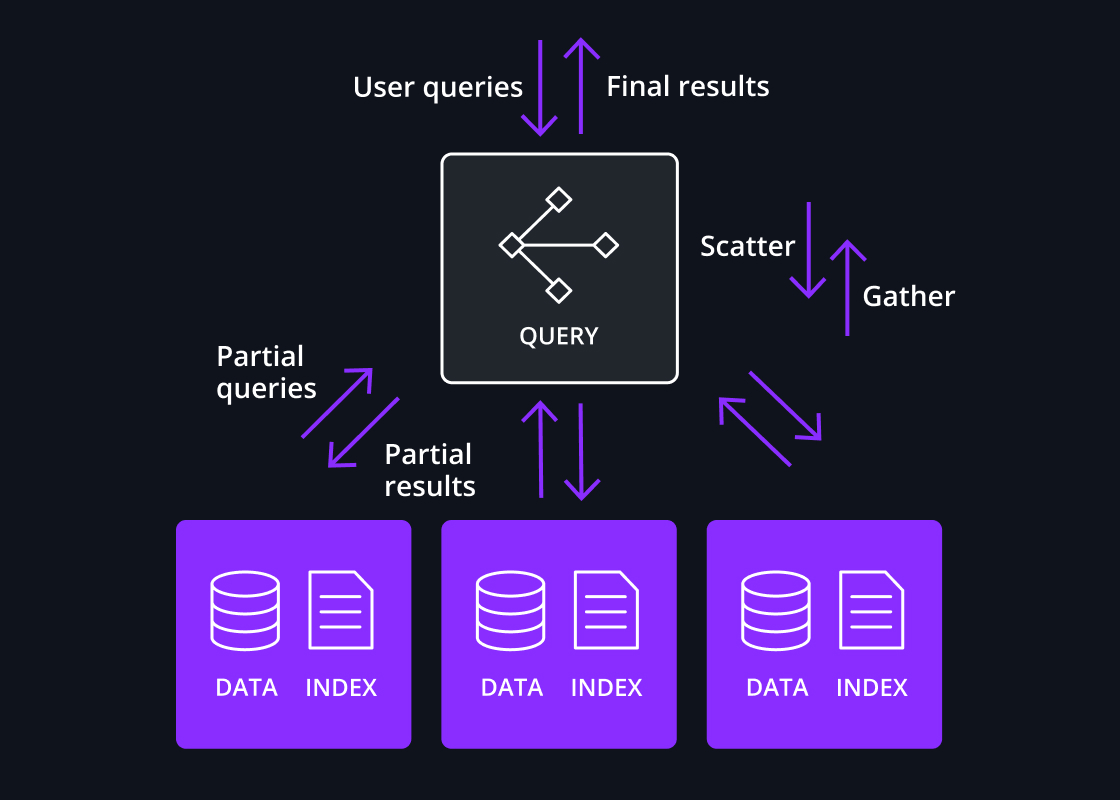
Scatter/gather processing
Druid’s core query engine features a highly efficient design to execute queries across large data sets. Queries are divided and fanned out – ie “scattered” – to relevant data nodes; partial results are merged by a broker node – ie “gathered”.
This design is highly efficient as only a portion of the data set is read and data is not sent across process boundaries or among the data nodes.
This single-stage process works for the smallest single node cluster to clusters with thousands of nodes with each data node processing billions of rows, enabling sub-second performance for most queries even with data sets of multiple petabytes.
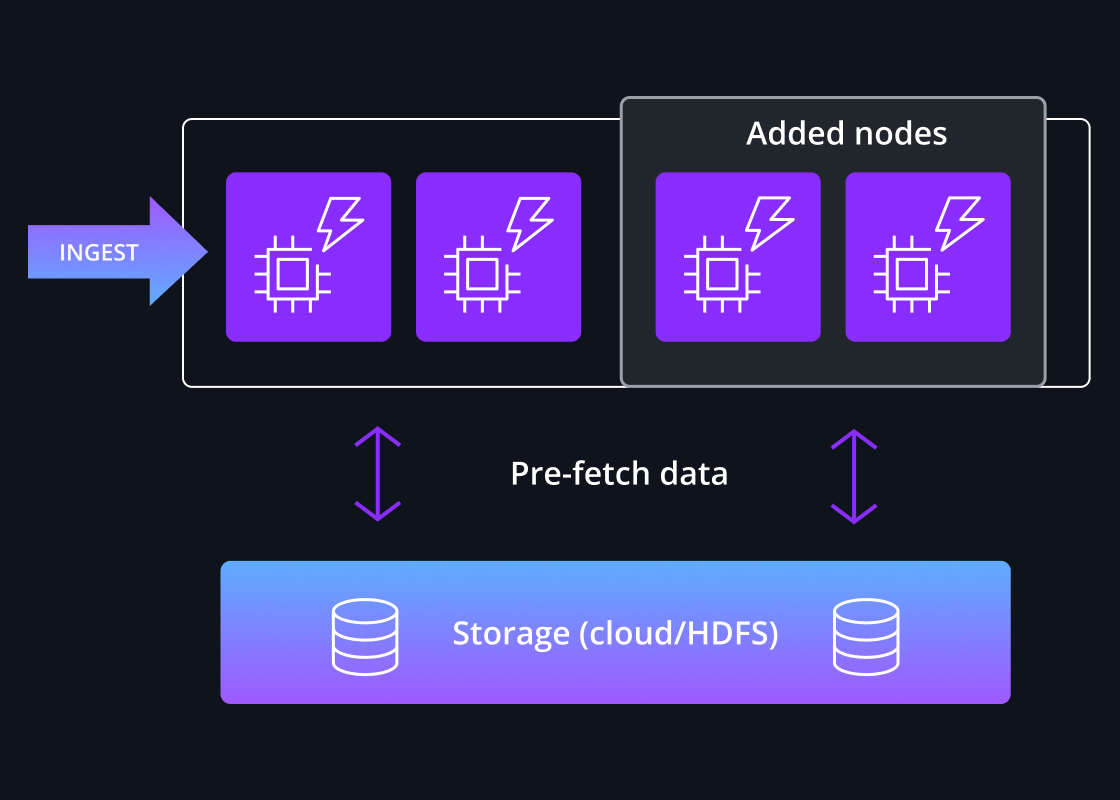
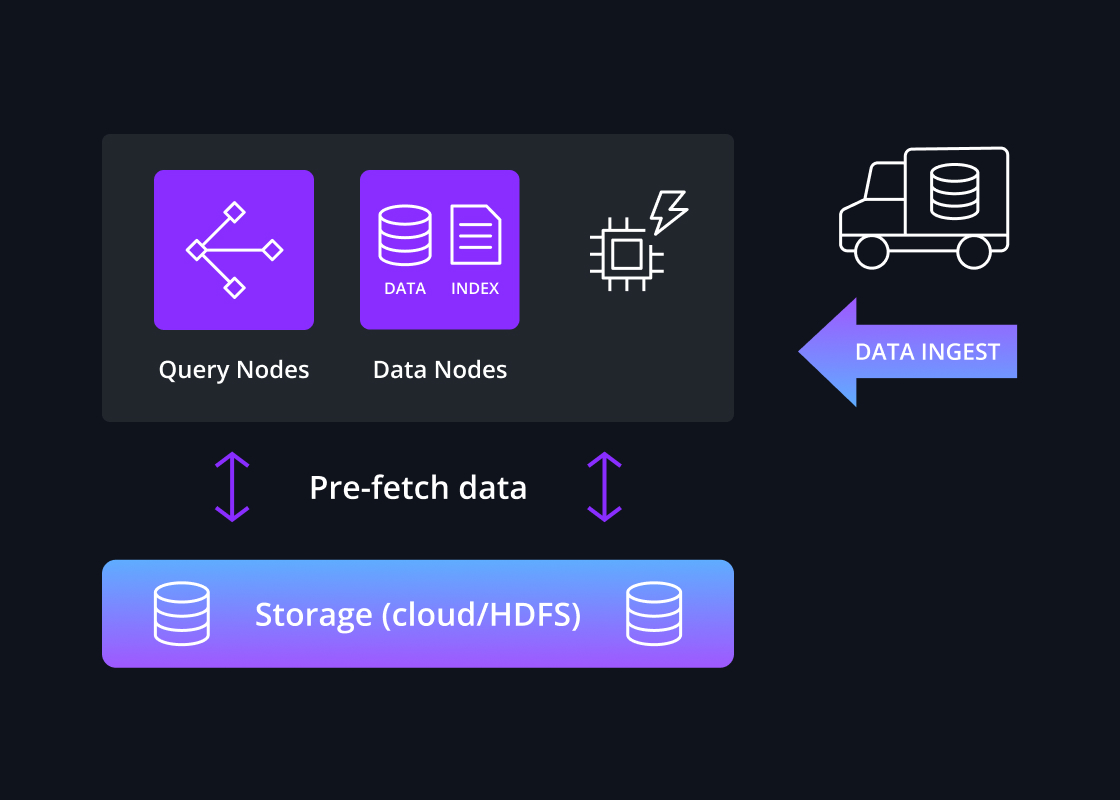
Intelligent pre-caching
For performance-sensitive workloads, data is pre-loaded into local caches before queries are issued, which guarantees high performance as data does not need to be read from deep storage over the network during a query.
Druid utilizes a high degree of intelligence to quickly identify which segments are relevant to the query and where they are located across a cluster of continuously rebalanced nodes. Queries are then fanned out across those relevant nodes and gathered so the final result can be sent to the application.
Optimized data format
Druid’s storage format was built in tandem with the query engine to maximize performance through processing efficiency. It stores ingested tables into optimized segments – with each segment comprising up to a few million rows of data.
The data in Druid segments are columnarized, time indexed, dictionary encoded, bitmap indexed, and type-aware compressed – all automatically. Queries only load the specific columns needed for each query and reads the optimized index, which further improves the performance of scans and aggregations.

“If you want super fast, low latency, less than a second, this is when we recommend Druid.”
Druid ensures applications with high concurrency have consistent performance under load - and at the lowest cost.
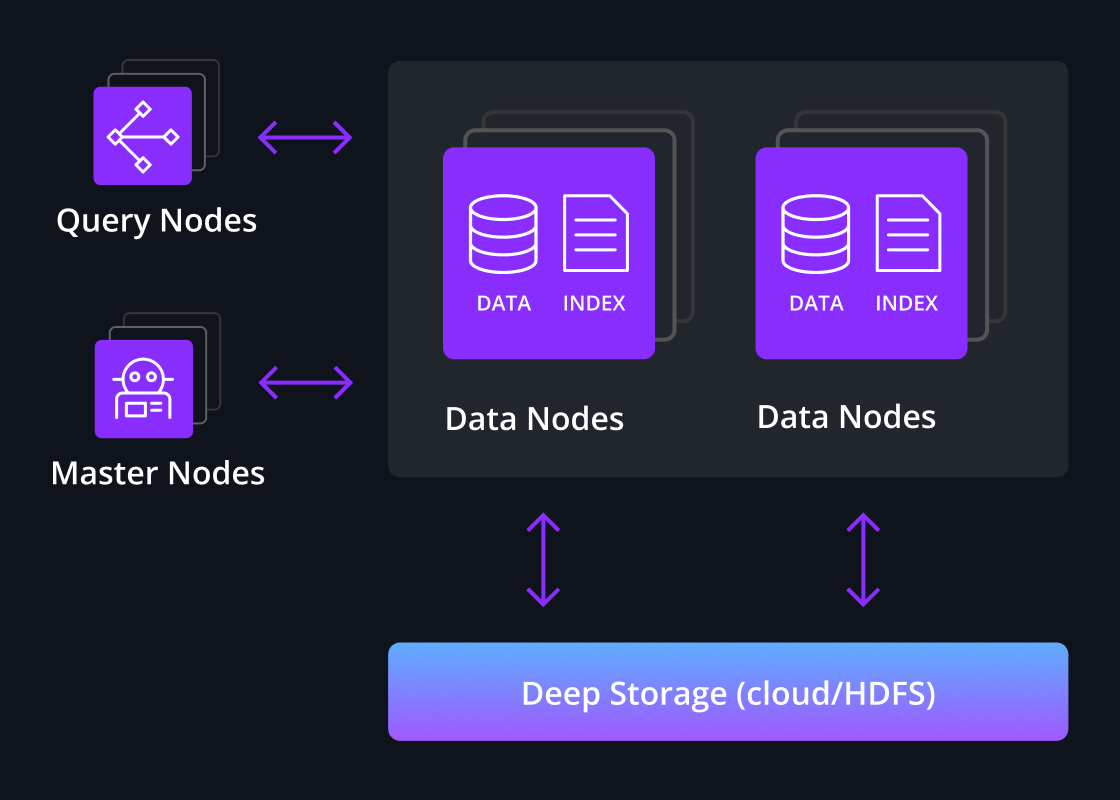
Services-oriented architecture
Druid’s service-oriented architecture coordinates efficient parallelization across multiple processing levels to support mixed workloads under load.
Druid optimizes parallelization and resource management to prevent bottlenecks and resource contention, from even large result sets or high queries per second. The parallelization of both query execution and query management is built to ensure consistent high performance under load.
Segment-level replication
Whenever data is ingested into Druid, a segment is created and a replica of that segment is created on a different data node. These replicas are used to improve query performance for high concurrency (and to provide an extra copy for high availability).
By loading segments on different data nodes, multiple nodes can answer the same query and maximize the parallelization to utilize the full CPU resources. Additional replicas can be created for segments for higher throughput requirements.
Quality of service and tiering
Druid makes it simple to ensure consistent, fast performance for critical workloads through a configurable QoS. With potentially thousands of queries vying for computing resources, Druid can guarantee critical queries will have prioritized access to cluster resources.
When an automated prioritization strategy is used, Druid prioritizes queries based on thresholds, adjusts query priorities and dynamically assigns the right lane in the processing thread pool. Combined with resource tiering, Druid ensures time-sensitive queries aren’t blocked by longer-running reporting queries.
Druid supports true stream ingestion with a connector-free integration to Apache Kafka and Amazon Kinesis.
Query on arrival
Druid includes built-in indexing services for Apache Kafka and Amazon Kinesis that enable event-based ingestion for real-time analytics. With other analytics databases, streaming events are persisted to files and then ingested in batches, incurring latency between event and insight.
With Druid, streaming data is ingested into memory and is immediately included in queries as each event arrives before being processed – columarized, compacted, and segmented – and persisted to deep storage.
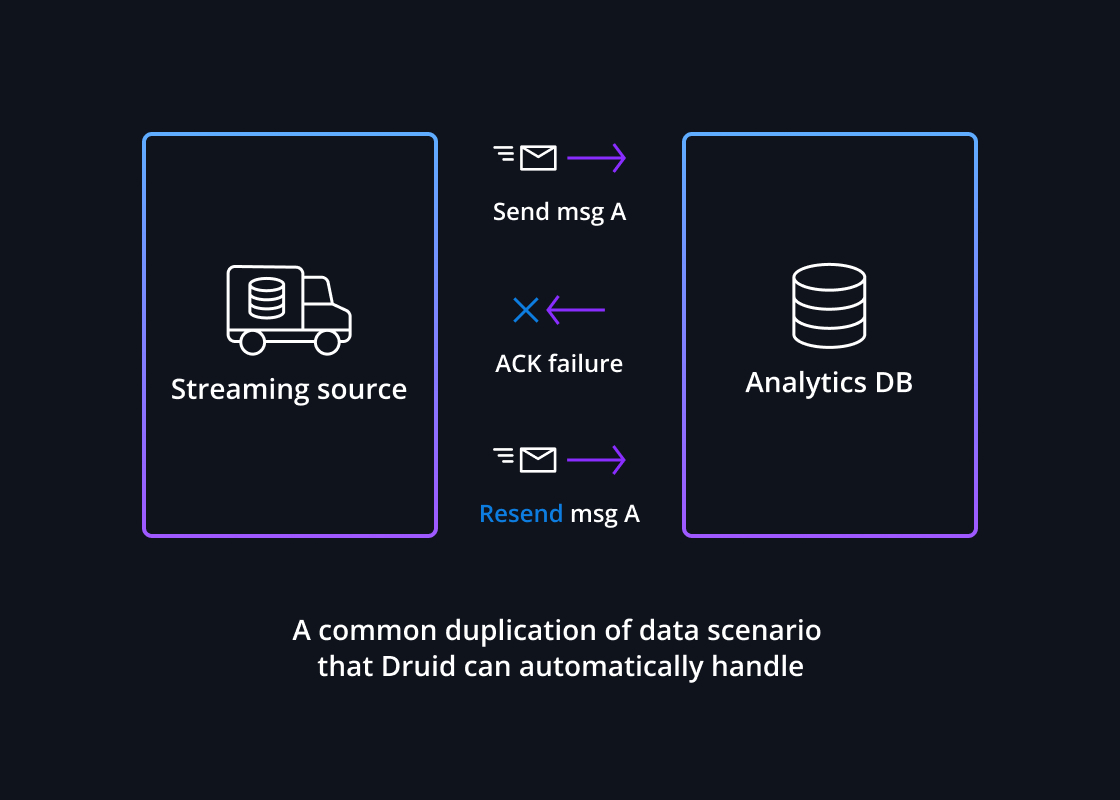
Exactly-once semantics
Druid guarantees data consistency with streaming data – preventing duplicates or data loss – with exactly-once semantics. Its native indexing service assigns a partition and offset to each event so that it can determine if the event was delivered as expected.
If there is a failure during stream ingestion, Druid will automatically continue to ingest every event exactly once, even events that arrive during the outage without any data loss.
Near-infinite, dynamic scalability
Druid features an elastic architecture with independently scalable components for ingestion, queries, and orchestration. For even the largest, multi-topic ingestion jobs, Druid can easily scale into the 10s of millions of events per second.
With variable ingestion patterns, Druid can avoid resource lag (as well as overprovisioning) by dynamically scaling parallel capacity. Druid automatically increases or decreases the active subtasks that are processing streaming ingestion by observing the number of partitions or shards in the stream.
Druid ensures non-stop reliability for applications with the highest availability and data durability requirements.
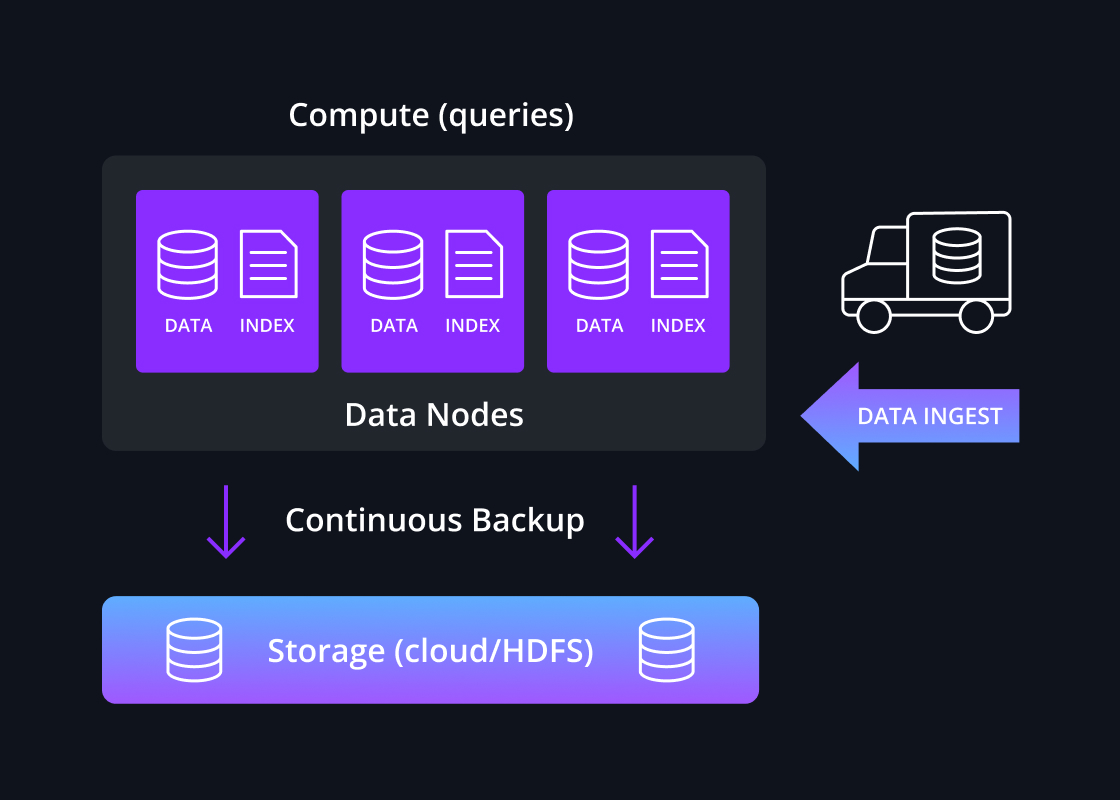
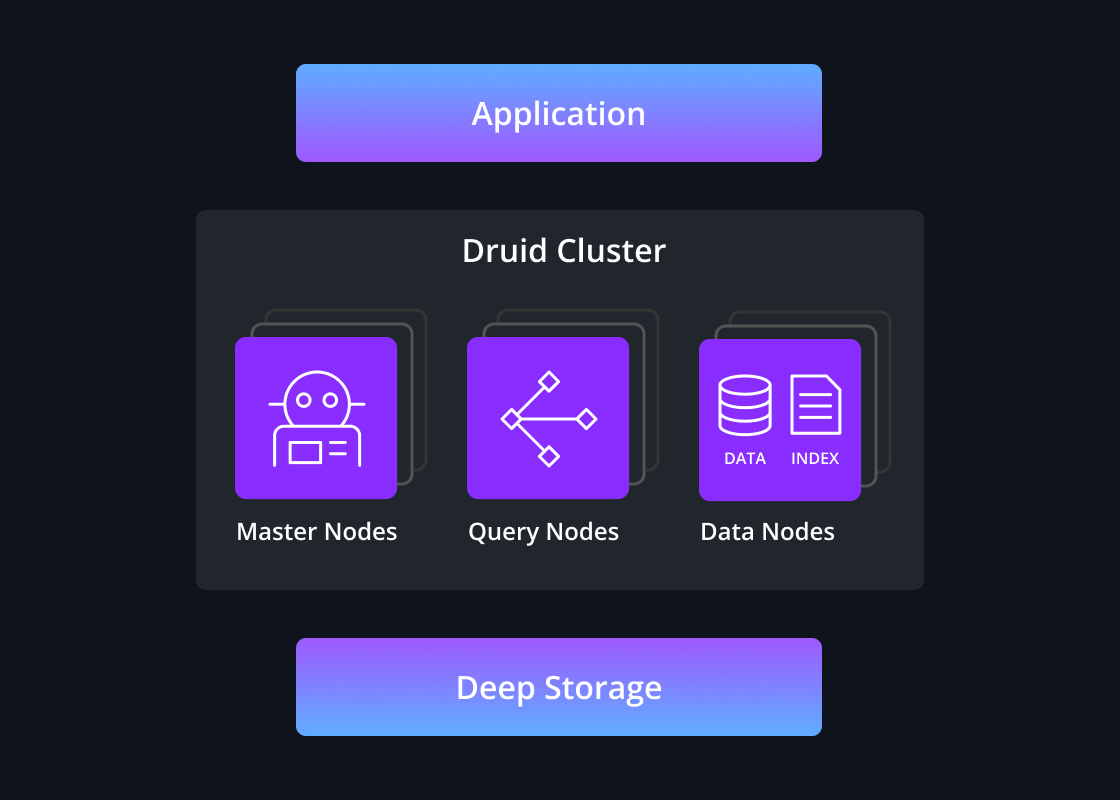
Continuous backup
As each data segment is built, the data is committed to deep storage, a durable object store. Common options for deep storage are cloud object storage or HDFS. This prevents data loss even if all replicas of a data segment are lost, such as the loss of an entire data center.
It is not necessary to perform manual backups of a Druid cluster as it provides automatic, continuous backup of all committed data. For streaming data ingestion, Druid can enable a zero recovery point objective.
Automated recovery
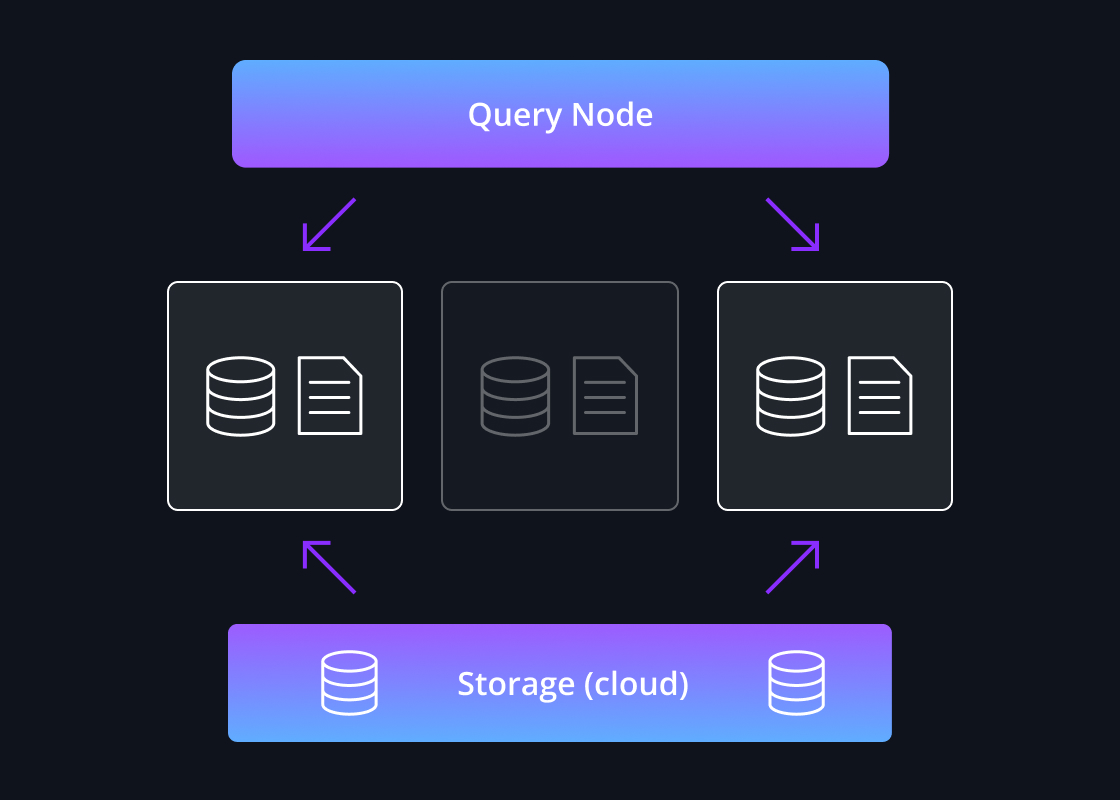
In addition to segment-level data replication, Druid facilitates high availability by self-healing the cluster via automatic cluster rebalancing and segment recovery from deep storage, as needed, in the event of node failure(s).
If a node fails, queries are automatically re-distributed across remaining nodes to maintain parallel performance, and when the node is back online, Druid will once again rebalance the cluster, preventing impact to service availability.
Rolling upgrades
Upgrading Druid or taking down a node for maintenance does not require downtime. Druid’s automatic cluster rebalancing makes Druid both operationally simple and maintains availability.
Moving to a new version uses a non-disruptive, “rolling” upgrade where one node at a time is taken offline, upgraded, and returned to the cluster. Druid is able to function normally during the rolling upgrade, even though some nodes will be using a different Druid version than other nodes during the upgrade.