Real-Time Analytics: Building Blocks and Architecture
May 18, 2023
Matt Morrissey
In today’s fast-paced world, waiting is a luxury no one desires. Whether it’s Netflix loading too slowly or a distant Lyft, users expect instant responses. Real-time analytics is the key to meeting this need, involving the immediate analysis of big data across large data sets as it’s generated.
What is real-time analytics?
Real-time analytics entails the immediate analysis of big data as it is generated, involving the application of mathematical and logical computations in real-time or near-real-time—usually within seconds of data creation. This approach facilitates a prompt understanding and response to evolving situations, patterns, or trends, proving valuable in scenarios where timely and informed decision-making is crucial.
This blog explores what real-time analytics entails and delves into the preferred building blocks and data architecture for data engineers starting to venture into this field.
What is real-time analytics?
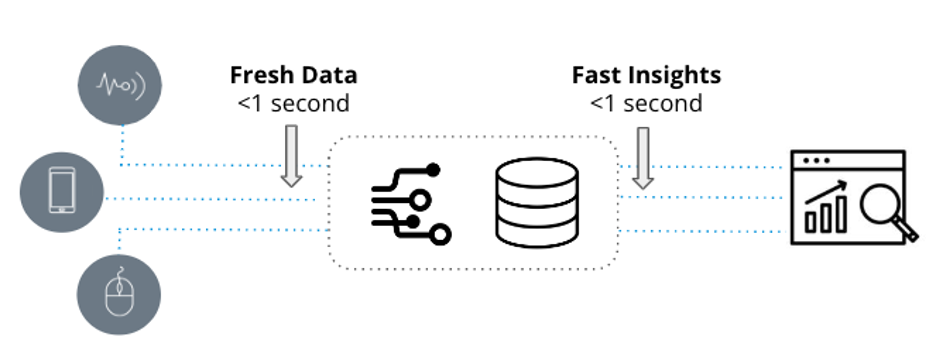
Real-time analytics is defined by two key attributes: fresh data and fast insights. It is used in latency-sensitive apps when it’s essential that new event-to-insight is measured in seconds.
Figure: Real-time analytics defined
In comparison, traditional analytics, which also goes by business intelligence, involves static snapshots of business data used for reporting purposes. These are powered by data warehouses, commonly utilizing platforms such as Snowflake and Amazon Redshift, and data lakes. The data analysis is often visualized through dashboards created with tools like Tableau or PowerBI.
While traditional analytics are built from historical data sources that can be hours, days, or weeks old, real-time analytics utilize recent data, including streaming data sources, and are used in operational workflows that demand very fast answers to potentially complex questions.
Traditional Data Analytics
Real-Time Data Analytics
Long-running reports and exports
Rapid filters and aggregations
Minutes to hours to process
Sub-second queries
Historical, batch processing data
Real-time, streaming data
Catching queries is OK, as the data changes slowly
Data changes too fast to pre-compute queries
Figure: Decision criteria for real-time analytics
For example, a supply chain executive is looking for historical trends on monthly inventory changes: traditional analytics is perfect here. Why? Because the exec can probably wait a few minutes longer for the report to process. Alternatively, a security operations team is looking to identify and diagnose anomalies in network traffic. That’s a fit for real-time analytics as the SecOps team needs to rapidly mine thousands to millions of real-time log entries in sub-second to spot trends and investigate abnormal behavior.
What are the benefits of real-time analytics?
The increasing demand for real-time analytics is driven by its substantial advantages for application users, providing a competitive advantage.
Interactive Applications
Real-time analytics enhances the interactivity of apps for external external users, promoting greater user adoption. Embedded real-time analytics in dashboards eliminates delays, enabling an interactive visualization of data for a seamless customer experience.
Faster Decision-Making
Real-time analytics empowers users to swiftly slice and dice data and understand the “why” behind events. Waiting minutes for data processing and query availability could lead to missed opportunities. Milliseconds query latencies empower users to pose multiple questions to the data, facilitating decision-making within minutes.
Automated Intelligence
Powering algorithms to automate real-time decisioning or machine learning inference, real-time analytics acts as a central brain, sifting through actions for optimal results.
Predictive Analytics
Anticipating trends and optimizing operations, predictive analytics enhances marketing, mitigates risks, and improves sectors like healthcare and finance. Leveraging predictive analytics enables businesses to make better decisions, achieve efficient resource allocation, and improve customer satisfaction.
What are the use cases for real-time analytics?
Application Observability
Application observability delivers analytics tools to monitor and understand the performance, health, and behavior of software applications. By continuously collecting and analyzing data on metrics such as response times, error rates, and system dependencies, organizations gain insights into the overall functioning of their applications. Real-time analytics in this use case enables prompt detection and resolution of issues, ensuring optimal performance and customer experience.
Security and Fraud
Real-time analytics is crucial for security and fraud detection, especially in financial services, as it allows organizations to monitor and analyze large amounts of data in real-time to identify anomalous patterns or suspicious activities. By employing advanced algorithms and machine learning models, security systems gain real-time information and quickly detect and respond to potential threats, mitigating risks and safeguarding sensitive information.
Product Analytics
In the realm of product analytics, real-time analytics provides continuous monitoring and assessment of user interactions with digital products. Organizations, especially in e-commerce, can track customer behavior, engagement metrics, product performance, and the impact of marketing campaigns in real-time. This immediate feedback drives better business decisions through quick adjustments, enhancements, and personalized user experiences, contributing to the overall success and optimization of digital products.
IoT / Telemetry
Real-time analytics is instrumental in the Internet of Things (IoT) and telemetry applications by processing and analyzing large amounts of data generated by connected devices and sensors in real-time. IoT analytics use case involves monitoring, managing, and extracting meaningful insights from the massive volume of data produced by IoT devices. Real-time analytics enables timely decision-making, predictive maintenance, and efficient utilization of IoT-generated data for various applications, ranging from smart cities to industrial processes.
Does the right architecture matter for real-time analytics?
While many database vendors claim proficiency in real-time analytics, the ease of handling such tasks often depends on the scale and complexity of the use case. For instance, consider weather monitoring, where sampling temperature every second across numerous weather stations and executing queries with threshold-based alerts and trend analysis can be accomplished effortlessly with databases like SingleStore, InfluxDB, MongoDB, or even PostgreSQL. Write a push API that sends the metrics directly to the database and then a simple query gets executed and voila…real-time analytics.
The challenge arises when dealing with larger volumes of events, complex queries involving multiple dimensions, and data sets reaching terabytes or petabytes.
High-throughput ingestion solutions like Apache Cassandra may come to mind, but they may not excel in analytics performance. The complexity further intensifies when the analytics use case requires joining multiple real-time data sources at scale.
How should one navigate these challenges?
Considerations when choosing an architecture
Are you working with high events per second, from 1000s to millions?
Is it important to minimize latency between events created to when they can be queried?
Is your total data set large, and not just a few GB?
How important is query performance – sub-second or minutes per query?
How complicated are the queries, exporting a few rows or large scale aggregations?
Is avoiding downtime of the data stream and analytics engine important?
Are you trying to join multiple event streams for analysis?
Do you need to place real-time data in context with historical data?
Do you anticipate many concurrent queries?
If any of these things matter, let’s talk about what that right architecture looks like.
What are the right building blocks for real-time analytics?
A real-time analytics solution needs more than a capable database. It starts with needing to connect, deliver, and manage real-time data. That brings us to the first building block: event streaming.
Event streaming
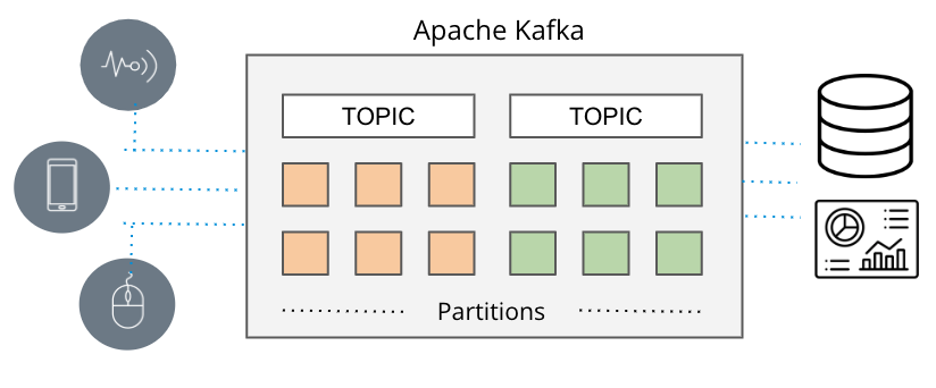
When real-time matters, batch-based data pipelines take too long and that’s why messaging queues emerged. Traditionally, delivering messages involved tools like ActiveMQ, RabbitMQ, and TIBCO. But the new way is event streaming with Apache Kafka and Amazon Kinesis.
Apache Kafka and Amazon Kinesis overcome the scale limitations of traditional messaging queues, enabling high throughput pub/sub to collect and deliver large streams of event data from a variety of sources (Amazon lingo: producers) to a variety of sinks (Amazon lingo: consumers) in real-time.
Figure: Apache Kafka event streaming pipeline
Those systems capture data in real-time from sources like databases, sensors, and cloud services in the form of event streams and deliver them to other applications, databases, and services.
Because the systems can scale (Apache Kafka at LinkedIn supports over 7 trillion messages a day) and handle multiple, concurrent data sources, event streaming has become the de facto delivery vehicle when applications need streaming analytics.
So now that we can capture real-time data, how do we go about analyzing it in real-time?
Real-time analytics database
Real-time analytics need a purpose-built database, a database that can take full advantage of streaming data in Apache Kafka and Amazon Kinesis and deliver insights in real-time. That’s Apache Druid.
As a high-performance, real-time analytics database built for streaming data, Apache Druid has become the database-of-choice for building real-time analytics applications. It supports true stream ingestion and handles large aggregations on TBs to PBs of data at sub-second performance under load. And since it has a native integration with Apache Kafka and Amazon Kinesis it makes it the go-to choice whenever fast insights on fresh data is needed.
Scale, latency, and data quality are all important when selecting the analytics database for streaming data. Can it handle the full-scale of event streaming? Can it ingest and correlate multiple Kafka topics (or Kinesis shards)? Can it support event-based ingestion? Can it avoid data loss or duplicates in the event of a disruption? Apache Druid can do all of that and more.
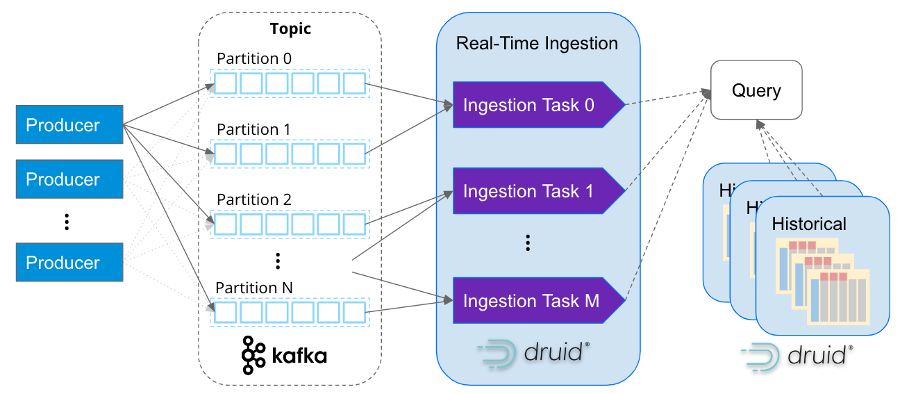
Druid was designed from the outset for rapid ingestion and immediate querying of events on arrival. For streaming data, it ingests event-by-event, not a series of batch data files sent sequentially to mimic a stream. There’s no connectors to Kafka or Kinesis needed and Druid supports exactly-once semantics to ensure data quality.
Just like how Apache Kafka was built for internet-scale event data, Apache Druid was too. Its services-based architecture independently scales ingestion and query processing practically infinitely. Druid maps ingestion tasks with Kafka partitions, so as Kafka clusters scale Druid can scale right alongside it.
Figure: How Druid’s real-time ingestion is as scalable as Kafka
It’s not that uncommon to see companies ingesting millions of events per second into Druid. For example, Confluent – the originators behind Kafka – built their observability platform with Druid and ingests over 5 million events per second from Kafka.
But real-time analytics needs more than just real-time data. Making sense of real-time patterns and behavior requires correlating historical data. One of Druid’s strengths, as shown in the diagram above, is its ability to both support real-time and historical insights via a single SQL query with Druid managing up to PBs of data efficiently in the background.
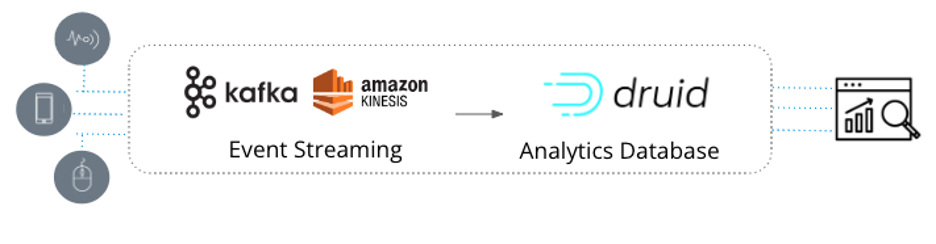
So when you pull this all together you end up with a very scalable data architecture for real-time analytics. It’s the architecture 1000s of data architects choose when high scalability, low latency, and complex aggregations are needed from real-time data.
Figure: Data architecture for real-time analytics
How Netflix Ensures a High-Quality Experience
Real-time analytics plays a key role in Netflix’s ability to deliver a consistently great customer experience for more than 200 million users enjoying 250 million hours of content every day. Netflix built an observability application for real-time monitoring of over 300 million devices.
Using real-time logs from playback devices streamed through Apache Kafka and then ingested event-by-event into Apache Druid, Netflix is able to derive measurements that understand and quantify how user devices are handling browsing and playback.
With over 2 million events per second and subsecond queries across 1.5 trillion rows, Netflix engineers are able to pinpoint anomalies within their infrastructure, endpoint activity, and content flow.
Parth Brahmbhatt, Senior Software Engineer, Netflix summarizes it best:
“Druid is our choice for anything where you need subsecond latency, any user interactive dashboarding, any reporting where you expect somebody on the other end to actually be waiting for a response. If you want super fast, low latency, less than a second, that’s when we recommend Druid.”
Ready to get started building your next real-time analytics application?
If you’re looking to build real-time analytics, I’d highly recommend checking out Apache Druid along with Apache Kafka and Amazon Kinesis for a complete end to end real-time analytics platform. You can download Apache Druid from druid.apache.org or request a demo to see Druid in action.
Other blogs you might find interesting
No records found...
May 21, 2026
A First Look at Lumi Loglake: Query Logs Where They Live
TL;DR: Imply Lumi Loglake is a lakehouse (separated compute/storage) architecture for unstructured logs that reduces costs from 40% up to orders of magnitude on your hardware/AWS/Azure bill used to run your...
Imply Lumi Major Release Preview: Continuing the Journey Towards Decoupled Observability/SIEM
We are getting ready to introduce the next major expansion of Imply Lumi and the observability warehouse. When we introduced the industry’s first observability warehouse, the goal was clear: decouple the...
Imply Lumi's Grafana Loki integration is now in Private Preview. The same logs you've loaded into Lumi for Splunk are now queryable natively in Grafana using LogQL with no second pipeline, no duplicate storage,...