Apache Druid 25.0 contains over 293 updates from over 56 contributors.
This release marks the graduation of Multi-stage-query (MSQ) from experimental to production-ready status. You can now confidently use the new ingestion engine in production.
At the same time, the new nested column feature introduced in Druid 24.0 is also graduated to production-ready status, as we’ve seen multiple users using it in production environments with minimum issues. In this release, we’ve introduced support for nested data from Avro, ORC, Parquet, and Protobuf files.
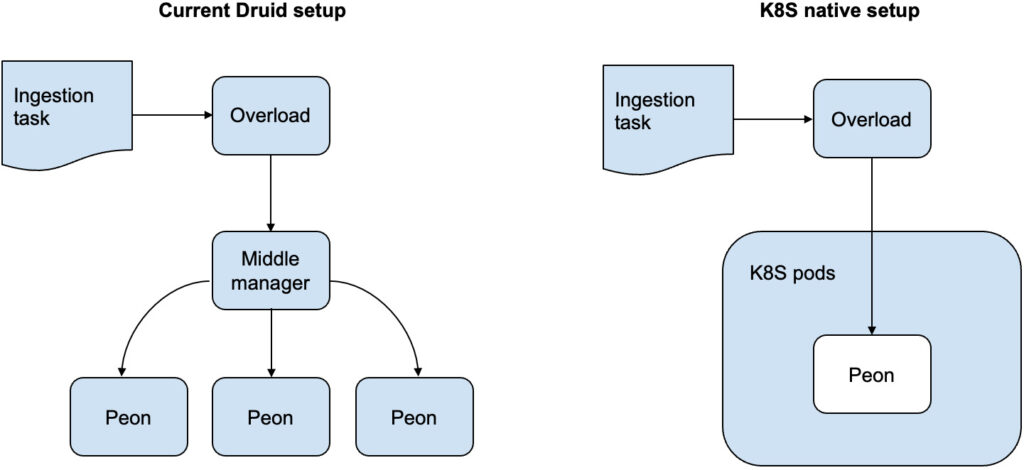
In this release, we are also introducing an experimental feature that allows you to run ingestion tasks (peons) directly on K8S without middle managers. This will help simplify the infrastructure of Druid clusters.
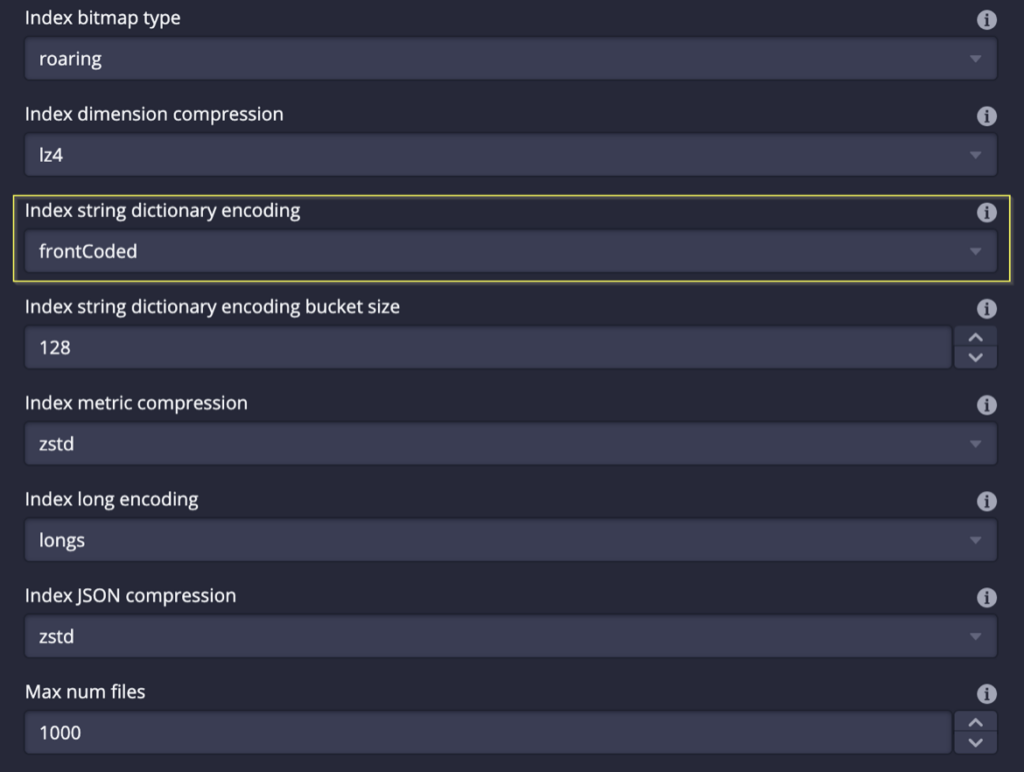
Lastly, we are releasing an experimental feature named front-coded string dictionary compression that can help you substantially reduce data footprint where stings are involved.
Visit the Apache Druid download page to download the software and read the full release notes detailing every change. The features in this Druid release are also available with Imply’s commercial distributions of Apache Druid.
Multi-Stage Query production ready
Multi-Stage Query (MSQ) is a new query engine introduced in Druid 24.0 currently focused on simplifying data ingestion. Since the last release, multiple teams have deployed MSQ into production with good results. With the various stability improvements, at this point, we would like to recommend you use MSQ as the default way of loading batch data.
At the same time, we are going to start deprecating Hadoop 2.x based ingestion in favor of Hadoop 3.x based ingestion starting the next release. If you are considering a move of your existing ingestion system, this is a good time to evaluate a move to MSQ instead of upgrading to the next version of Hadoop-based ingestion.
Middle manager-less K8S ingestion
In the new K8s native setup, you can now run ingestion tasks without MiddleManagers. This eliminates one of the complexity in Druid clusters and simplifies the deployment. It also allows the tasks to be scheduled much more quickly while reducing the overall resource needs for a Druid cluster.
Front-coded string dictionary compression
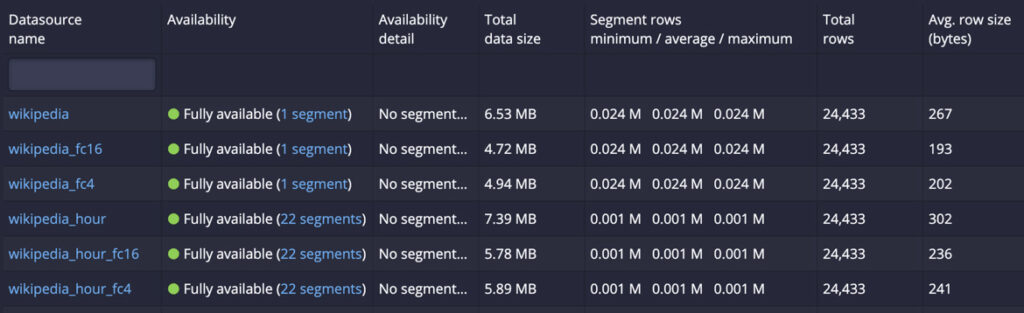
In this release, there is a new experimental feature that allows you to use a new encoding scheme for string dictionaries used in Druid such that the compression will be more effective. From the test dataset, you can see around a 30% reduction in size. (_fc4 and _fc16 are with new compression encoding)
Unlike most database compression options, using the new encoding compression has little to no impact on your queries’ performance. In effect, it provides free storage space.
Note: Newly created segment files using the new encoding scheme cannot be read by Druid versions earlier than 25.0. If you start writing new data with the new encoding scheme, you cannot downgrade Druid without data loss.
Over time, we’ll make this the default encoding scheme for Druid segments once we prove its stability.
Improved Druid’s start experience
In the past, when you started a Druid cluster with the bundled start script, you’ll have to pick the right size based on your computer’s hardware. We found this to be confusing at times for people who are trying to get started with Druid.
In this release, we have introduced a smarter option: start-druid.
By default, start-druid uses 80% of the system memory of the machine it’s running on. You can override this by setting the “-m” option. Running “start-druid -m 16g”, for example, would start Druid with 16GB of memory allocated to its processes. The startup script automatically computes the right memory and thread allocation for all the processes it starts, greatly simplifying the startup process for Druid.
This also provides the basis for running a Druid cluster at scale, as we have documented the logic of how various settings should be set.
Druid 25.0 includes additional metrics and metric dimensions to help you better monitor and operate a Druid cluster:
segment/handoff/time
ingest/kafka/partitionLag
ingest/kinesis/partitionLag/time
ingest/pause/time
Want to contribute?
We’re very thankful to all of the contributors who have made Druid 25.0 possible – but we need more!
Are you a developer? A tech writer? Someone who is just interested in databases, analytics, streams, or anything else Druid? Join us! Take a look at the Druid Community to see what is needed and jump in.
Try this out today
For a full list of all new functionality in Druid 25.0, head over to the Apache Druid download page and check out the release notes!
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...