Comparing Data Formats for Analytics: Parquet, Iceberg, and Druid Segments
Jan 16, 2024
Rick Jacobs
In a world where vast volumes of data fuel insights, the strategic selection of a data storage format is crucial. When it comes to storing and querying large amounts of data, there are many storage options available. Apache Parquet and Apache Iceberg are popular general purpose big data file formats, while Apache Druid segments are more specific for analytics.
As the data landscape continues to evolve, the choice between these technologies will largely depend on specific use case requirements. So which one is right for you? For scenarios prioritizing efficient storage and complex read operations, Parquet may be an ideal solution. When dealing with large, dynamic datasets requiring robust data management features, Iceberg stands out. While for applications where real-time analytics and immediate data availability are crucial, Druid’s segmentation model offers unparalleled advantages.
In this blog, I will give you a detailed overview of each choice. We will cover key features, benefits, defining characteristics, and provide a table comparing the file formats. So, let’s dive in and explore the characteristics of Apache Parquet, Apache Iceberg and Apache Druid segments!
Overview of Data Storage Technologies
Before we dive into the intricacies of Parquet, Iceberg, and Druid segments, let’s lay the groundwork by understanding some fundamental concepts of data storage technologies in the context of big data and analytics.
Columnar Storage: Unlike traditional row-based storage, where data is stored sequentially, columnar storage stores data in columns. This approach brings remarkable advantages, such as reduced storage footprint, improved compression, and the ability to read only the columns relevant to a particular query.
Data Indexing: Indexing is a data structure technique used to quickly locate and access data within a database. Indexes can drastically improve query speed by allowing the database engine to find and retrieve data without scanning every row in a table. For analytical workloads, especially in columnar storage systems, indexing strategies can be used to optimize the performance of complex queries.
Data Partitioning: Data partitioning involves breaking down large datasets into smaller, manageable parts based on specific criteria. For example, data can be partitioned by date, region, or category. This practice enhances data retrieval efficiency by allowing systems to target and process only the relevant partitions, thus minimizing resource wastage and speeding up query execution.
Apache Parquet
Parquet files are generated using data processing frameworks or libraries such as Apache Spark, Apache Hive, or tools like Pandas with PyArrow in Python. The process requires defining a schema for the data, since Parquet is a schema-aware format. Once the schema is defined, data is written to a Parquet file through specific functions provided by the chosen framework or library.
For example, in Apache Spark, one might read data from a JSON file, and with a simple function call, write that data into a Parquet file. Similarly, in Apache Hive, a SQL statement is used to create a table stored as Parquet. These actions, executed within the respective frameworks or libraries, serialize the data according to the Parquet format, apply any specified compression, and write the data to disk, producing Parquet files ready for efficient storage and querying.
Parquet groups data by columns, which facilitates efficient encoding schemes and compression. The data is divided into smaller sets known as row groups, each encompassing several rows that are processed as a batch. Row groups act as the core unit of data storage and retrieval in Parquet. Each row group’s data is written to storage once it’s complete, ensuring a manageable chunk of data that optimizes the read and write operations. The size of a row group is configurable but is typically set in a way to fit entirely in memory, allowing for efficient processing.
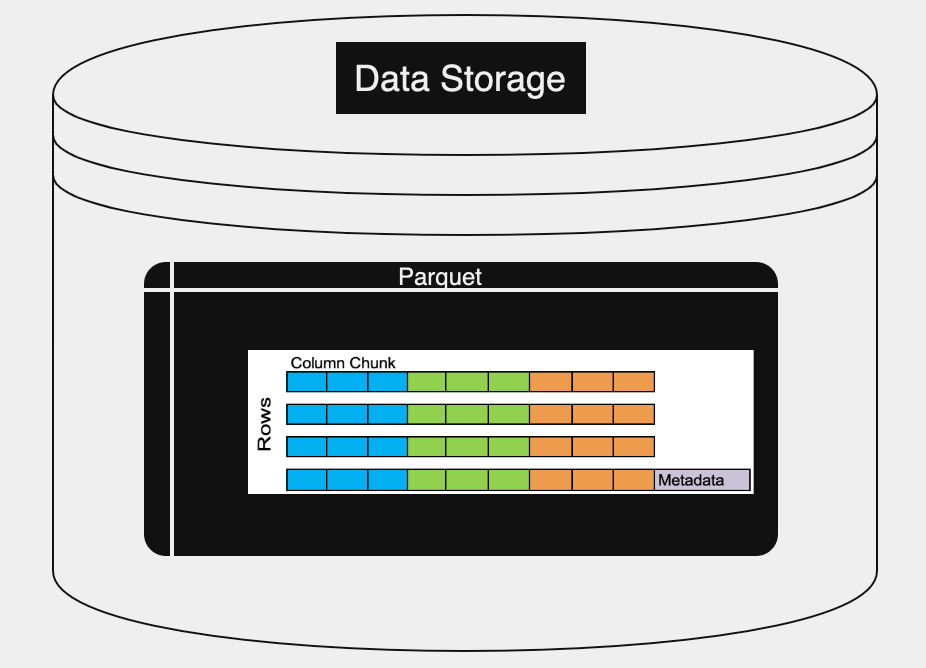
Within a row group, data is further organized into columns, with each column storing its respective data values in a contiguous manner. This columnar layout is particularly advantageous for queries, which often only access a subset of the columns in the dataset. The column-oriented storage enables efficient data compression and encoding schemes which significantly reduce the storage footprint and improve query performance. Furthermore, Parquet’s design allows for selective reading of specific columns during data queries, reducing I/O operations and enhancing query performance. The figure below shows a sample Parquet file.
As shown in figure, each Parquet file has the following:
Row: single record of data from each column
Column Chunk: a set of data from one column comprised of multiple rows
Metadata: information on the file’s schema, column details, and statistics, etc.
The Parquet format arranges data into column-oriented row groups, with each group containing several rows. Each row group contains “column chunks” because a row group stores only a fragment of a column. Here are some of the benefits of Parquet’s columnar model:
Efficient Compression and Schemes
Parquet is designed to support very efficient compression and encoding schemes. Since data is stored by column, similar data is often stored close together, which enables better compression. Different columns can be compressed differently, and more suitable encoding can be chosen per column.
Improved Read Performance
Parquet’s columnar storage format is optimized for workloads that primarily read from disk. It allows for much more efficient data reads because it’s possible to read only the columns needed for a particular query rather than reading the entire row of data.
Support for Nested Data Structures
Parquet supports complex nested data structures, meaning it can handle data that doesn’t fit well into flat relational tables without flattening it, which can simplify data management and querying.
Compatibility with Multiple Frameworks
Parquet can be used with a variety of data processing frameworks, including Apache Hadoop, Apache Spark, and Apache Flink. This flexibility allows users to integrate Parquet into their existing data systems without needing to implement a new storage format.
Space Savings
Because of its efficient data compression and encoding schemes, Parquet can offer significant cost savings in storage space, which can translate to savings in storage costs, especially when using cloud storage solutions.
Improved I/O Through Predicate Pushdown
With predicate pushdown, queries can skip reading unnecessary columns, which dramatically reduces I/O requirements. This is particularly effective for queries that only access a subset of the columns in a table.
Support for Evolution of Data Schema
Parquet supports schema evolution. Fields can be added or removed from the dataset, and old datasets can still be read with the new schema.
Given these advantages, Parquet’s columnar model emerges as an alternative for efficient data storage and querying. Its ability to provide immediate insights, scale with growing data demands, aggregate data swiftly, and process queries with low latency makes it a robust solution for modern data storage needs.
Apache Iceberg
Apache Iceberg was developed in response to the limitations of the Hive table format. The core issues centered around the unreliable writing to Hive tables, and the lack of atomicity in operations which affected the trust in the results from massively parallel processing databases. Hive’s directory-based tracking system didn’t scale well, leading to difficulties in managing the state of tables that were stored both in the filesystem and in a separate database for directories, complicating the process of making fine-grained updates to data files. Iceberg offers solutions to these problems with an open table format designed for large analytic datasets, ensuring that operations are atomic, meaning they either fully succeed or fail without partial writes.
The Iceberg table format organizes dataset files to represent them as a single “table” to provide an abstraction layer for users to interact efficiently with the data. Iceberg redefines table format at the file level instead of the directory level, enhancing efficiency and allowing for complex operations like CRUD at scale. Iceberg simplifies partitioning and querying by automatically managing the relationship between column values and their partitions, which allows users to get accurate query results without needing to understand the physical table layout or maintain additional partition columns. It also supports in-place table evolution to adapt to changing business needs.
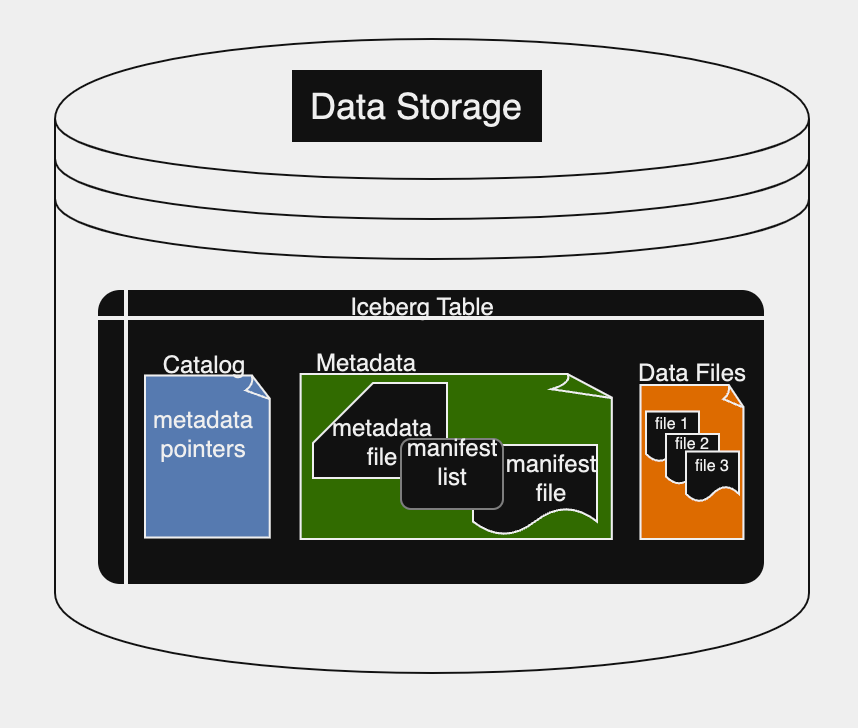
Iceberg is designed for managing structured data with an emphasis on scalability and flexibility. It uses a sophisticated schema evolution mechanism that allows for alterations in the table’s schema without compromising the integrity of the data. This is a significant departure from traditional rigid schema definitions. Iceberg’s architecture is built around ACID-compliant transactions, ensuring that all data operations are processed reliably and consistently. This transactional support is key to maintaining the accuracy and trustworthiness of the data, which is critical in environments where data is continuously updated. It optimizes query performance through intelligent partition pruning that minimizes the data scanned during queries, which is particularly beneficial for large datasets where scanning vast amounts of data can be resource-intensive and time-consuming. The figure below shows a sample Iceberg table with the architectural layers.
As shown in figure, each table has 3 layers:
Catalog: contains pointers to table metadata
Metadata layer: contains metadata files, manifest lists, and manifest files
Data layer: raw data files
The Iceberg table format employs a catalog as a central repository to locate the current metadata pointer for tables, thus facilitating transactions by supporting atomic operations. The metadata file contains detailed table schema and snapshot information, including the current snapshot. When a SELECT query is executed, the engine retrieves the metadata file’s location from the catalog to find the current snapshot ID, which in turn links to the manifest list. This list details the manifest files that constitute the snapshot, including data file locations and statistical information. Manifest files track these data files, containing details to enhance read efficiency. Here are some of the benefits of the Iceberg file system:
Schema Evolution
Iceberg’s schema evolution capability allows for backward and forward compatibility, meaning newer versions of schemas can read data written with older versions and vice versa. This seamless evolution is critical for long-term data storage and access where the schema may need to change to reflect new business requirements or data sources.
Hidden Partitioning
With hidden partitioning, Iceberg abstracts the complexity of partitioning away from the user. Users don’t need to know partition keys or layout; they simply query the table as if it were unpartitioned. This feature simplifies data engineering efforts and reduces the potential for user error.
Snapshot Isolation
Snapshot isolation in Iceberg prevents dirty reads and write skew, which are common issues in database transactions. Users can confidently read from a table without worrying about partial updates from concurrent transactions, which is crucial for data consistency and reliability.
Incremental Processing
Incremental processing in Iceberg means that systems can identify and process only what’s changed, rather than reprocessing the entire dataset. This efficiency reduces compute costs and speeds up processing times, particularly beneficial for large datasets where reprocessing can be costly and time-consuming.
Row-level Operations
Iceberg provides row-level operations for detailed data management. It tracks each file and row, enabling precise updates, deletes, and inserts. This granular control is particularly useful for applications like customer 360 views, where a single record may need to be updated frequently.
Time Travel
Iceberg’s time travel (query data as it existed at a specific point in time.) feature allows querying of data at specific points in time. This is useful for reproducing experiments, auditing changes, and rollback in case of errors. It also enables comparing historical and current data for trend analysis.
Compatibility and Integration
Iceberg’s compatibility with processing engines like Spark, Flink, and Trino means it can be easily integrated into existing data platforms, minimizing the need for changes in user applications and allowing organizations to leverage their existing data infrastructure.
These features collectively make Apache Iceberg an interesting option for large-scale data storage, retrieval, and analytics. The integration of schema evolution, partitioning, and processing features can be helpful to businesses that prioritize agility and insight in data-intensive environments.
Apache Druid Segments
Data is ingested into Druid either through batch loading or streaming. If ingested from files, the data goes directly into segments. If it is from streams, it first enters memory and becomes immediately queryable. Segments are files where data is stored and are usually between 300-700MB with a couple of million rows. Druid indexes the data and partitions the segment files based on time and then optionally by hashes of values in the input rows.
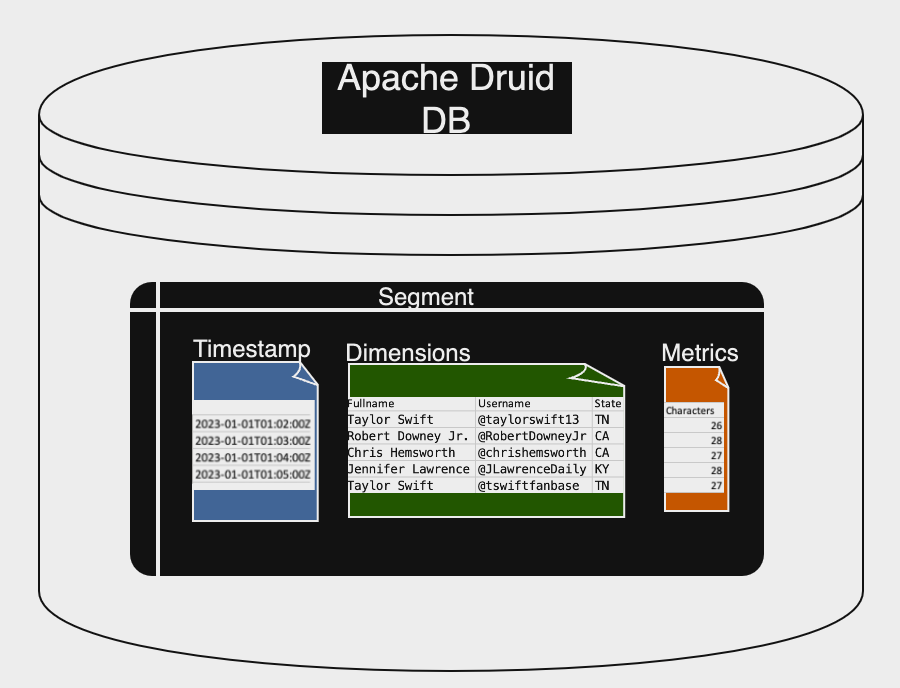
The columnar segments are distributed across the data nodes and memory mapped ahead of time which decreases query latency by scanning only the columns that are needed for a query. The segment is then compacted and committed to at least two different nodes and a copy is also stored in deep storage for durability. The three basic column types in a segment are timestamp, dimensions, and metrics. The figure below shows a sample segment with the basic column types.
The timestamp and metrics columns are compressed arrays of integers or floating-point numbers. The dimension columns hold the actual data and support filter and group-by operations. Each dimension contains three data structures:
Dictionary: Maps values to the IDs.
List: The column’s values, encoded using the dictionary.
Bitmap: One bitmap for each distinct value in the column, to indicate which rows contain that value
Druid’s segmentation-based framework is a unique approach to data storage. This distinctive model not only caters to real-time data ingestion but also ensures extremely fast querying. Here are some of the benefits of Druid’s segmentation model:
Real-Time Ingestion
Druid is engineered with a strong emphasis on real-time data ingestion and analysis. This allows for the immediate querying of data as it gets ingested into the system. Unlike traditional databases that may have a lag between data ingestion and data availability for querying, Druid’s architecture minimizes this delay, making the data available for real-time insights. This feature is particularly advantageous in scenarios where timely data analysis is crucial for decision-making.
Scalability
Due to the tremendous amounts of data being generated the ability to scale is of utmost importance. As data loads increase, Druid easily scales to accommodate the growing data volumes without sacrificing performance. This scalability ensures that your data infrastructure remains robust and capable, even as data demands escalate.
Quick Data Aggregation
Data aggregation is a fundamental aspect of data analysis, especially in cases where summarizing data is essential for deriving meaningful insights. Druid excels in quick data aggregation, enabling faster synthesis of data and thereby aiding in timely decision-making. This feature is crucial for use cases where aggregating data swiftly is crucial for maintaining a competitive edge.
Low-Latency Queries
In interactive analytics scenarios, the speed at which queries are processed is paramount. Druid’s segmentation architecture is tailored to facilitate low-latency queries, ensuring rapid responses to query requests. This low-latency querying capability makes Druid an ideal choice for interactive analytics applications where users expect quick responses to their queries, enhancing the overall user experience and enabling real-time decision-making.
Support for Flexible Data Schemas
Segments supports auto-schema detection. Data can be ingested without a defined schema and fields and be added and removed automatically.
Through these advantages, Apache Druid’s segmentation model emerges as a compelling choice for real-time data ingestion and querying. Its ability to provide immediate insights, scale with growing data demands, aggregate data swiftly, and process queries with low latency makes it a robust solution for modern data analytics needs.
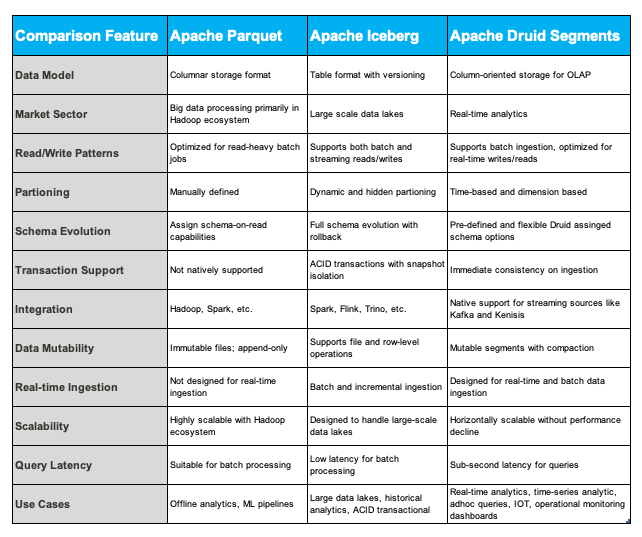
Comparative Table
The table below provides a summary comparison of Parquet, Iceberg and Druid Segments.
Considerations for Choosing the Right Technology
When selecting a data storage and query execution framework, the nature of the data workload and the specific needs of the use case are paramount. Parquet is often chosen for its efficient storage and excellent compatibility with batch processing workloads. It shines in ecosystems that leverage Apache Hadoop or Spark for complex, read-intensive query operations. Parquet’s columnar storage format means that it can provide significant storage savings and speed up data retrieval operations. However, Parquet’s batch-oriented nature may not suit scenarios requiring immediate data availability and real-time analytics.
Iceberg extends the capabilities of batch processing frameworks by adding features like schema evolution and transactional support, which are crucial for maintaining large and evolving datasets. Iceberg’s ability to handle concurrent writes and reads without data corruption makes it a strong candidate for environments with heavy data engineering needs. It provides a more analytical, snapshot-based approach to data querying. However, the Iceberg framework might not offer the low-latency responses required for real-time monitoring or interactive analytics applications.
Conversely, Druid segments, support batch ingesting but are engineered to excel in environments that demand real-time data ingestion and rapid query performance. Druid’s design enables immediate data visibility post-ingestion, catering to use cases such as user behavior analytics, financial fraud detection, and operational monitoring, where insights are needed instantly. Its architecture supports high concurrency and low-latency queries, even on high-dimensional data, which is essential for interactive applications.
Druid’s real-time streaming ingestion, combined with its ability to scale horizontally and perform fast data scans and aggregations, makes it the standout option for organizations that cannot afford to wait for batch processing cycles and need to make decisions based on the most current data available. Therefore, for use cases that require real-time insight with fast data ingestion and ad-hoc query capabilities, Druid segments offer the best solution.
Summary
In this assessment of Apache Parquet, Apache Iceberg, and Druid segments, we’ve delved into the intricacies of each technology, uncovering their unique strengths and applications. Parquet emerges as a highly efficient storage format, ideal for batch processing workloads and read-intensive query operations, offering significant storage savings and decent data retrieval.
Iceberg, on the other hand, extends these capabilities, introducing critical features like schema evolution and transactional support, making it well-suited for managing large, evolving datasets and heavy data engineering needs. However, its analytical, snapshot-based approach might fall short in scenarios demanding real-time responses.
This is where Druid segments shine, with their unparalleled ability to support real-time data ingestion and rapid query performance. Designed for immediate data visibility post-ingestion, Druid is the optimal choice for environments requiring quick insights, such as in user behavior analytics or financial fraud detection, thanks to its architecture that supports high concurrency and low-latency queries, even with high-dimensional data.
Understanding the unique capabilities and limitations of each technology is key to making informed decisions, ensuring that your data storage strategy aligns perfectly with your organizational needs and the specific demands of your data workloads. With the insights provided in this blog, you are now equipped to choose the most suitable data storage and querying solution, paving the way for more efficient, insightful, and responsive data-driven strategies.
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....