Overview
There’s a need for instant happening in data analytics, and it’s happening at scale on large data sets from a surge in real-time data from event streaming platforms like Apache Kafka and Amazon Kinesis. The ability to collect real-time data, process analytical queries, and then act on insights – all in sub-second – is increasing in importance. There’s a key reason why Netflix, Confluent, and Target are among 1000s of companies leading their industries. It’s in part because of real-time analytics and the data architectures that are enabling a new generation of real-time operational workflows.
While some may think of real-time analytics as simply fast insights coming out of an in-memory data store, real-time analytics are really defined by two key attributes: fresh data and fast insights. When it’s essential to minimize new event-to-insight, that’s where real-time analytics are necessary.
In comparison, business intelligence (also thought of as traditional analytics) involves historical aggregations for reports and planning and is powered by cloud data warehouses like Snowflake and Google Big Query and visualized with PowerBI, Tableau, or a number of other BI tools.
Here’s a quick reference table that compare the use and core technical definitions of each.

Let’s take for example, a supply chain manager is looking for trends on monthly inventory – what’s the current inventory, what’s the turnover rate, etc. Cloud data warehouses are a perfect fit here. Why? Because there isn’t a strong business need for immediacy. It’s likely OK if the manager has to wait several minutes or longer for the report to finish processing and the report itself could just be cached in advance.
Now on the other hand, a security operations (SecOps) team is looking to understand anomalies in network traffic. That’s a fit for an analytics database supporting real-time analytics as the SecOps team needs to rapidly mine potentially millions of real-time log entries in sub-second to identify patterns and investigate abnormal behavior. And in contrast to the supply chain use case, these types of queries cannot be pre-defined and cached in advance.
Requirements
Most transactional databases will say they’re good for real-time analytics and they are…to a degree. Take for example weather monitoring. Let’s say the use case calls for sampling temperature every second across 10s of 1000s of weather stations with queries that include alerts and historical trend analysis. This would be easy for any number of databases like SingleStore, InfluxDB, or MongoDB. Write a push API that sends the metrics directly to the database and then a simple query gets executed and voila…real-time analytics.
So when do you need to consider a purpose-built database for real-time analytics? Scale. High throughput. Query complexity. In the example above, the data set is pretty small and the analytics are pretty simple. A single temperature event is only generated once every second and a SELECT with WHERE statement to capture the latest events doesn’t require much processing power.
Things start getting challenging and pushing the limits of databases when the volume of events ingested gets higher, the queries involve a lot of dimensions, and data sets are in the terabytes (if not petabytes). Apache Cassandra might come to mind for high throughput ingestion. But analytics performance wouldn’t be great. Maybe the analytics use case calls for joining multiple real-time data sources at scale. What to do then?
Here are some considerations to think about that’ll help define the requirements for the right architecture:
- Are you working with high events per second, from 1000s to millions?
- Is it important to minimize latency between events created to when they can be queried?
- Is your total dataset large, and not just a few GB?
- How important is query performance – sub-second or minutes per query?
- How complicated are the queries, exporting a few rows or large scale aggregations?
- Is avoiding downtime of the data stream and analytics engine important?
- Are you trying to join multiple event streams for analysis?
- Do you need to place real-time data in context with historical data?
- Do you anticipate many concurrent queries?
If any of these things matter, then Apache Druid would be a great fit for you.
Solution
Apache Druid is a high-performance, real-time analytics database built for streaming data. Its early roots were in ad-tech supporting rapid ad-hoc queries against billions of programmatic events in real-time. Now, it has become the database-of-choice for 1000s of companies – across industries – including Netflix, Confluent, and Target for building real-time analytics applications.
Fresh Data
Analytics are only as real-time as the data. And that’s why data architects are increasingly adopting Apache Kafka and Amazon Kinesis to make real-time data accessible for applications.
But scale, latency, and data quality are all important when selecting the analytics database for streaming data. Can it handle the full-scale of event streaming? Can it ingest and correlate multiple Kafka topics (or Kinesis shards)? Can it support event-based ingestion? Can it avoid data loss or duplicates in the event of a disruption? Apache Druid can do all of that and more.
Druid was designed from the outset for rapid ingestion and immediate querying of stream data upon delivery. Its native integration with Apache Kafka and Amazon Kinesis has made it the preferred choice whenever data architects and developers need to integrate with streaming platforms.
In contrast to other analytics databases, Apache Druid does not require a connector to Apache Kafka or Amazon Kinesis. It hooks directly into the streaming topics with inherent support for exactly-once ingestion to guarantee data delivery and prevent duplicate data. As data is ingested, the event is made available instantly for queries (hence fresh data). As that data set grows, it will eventually be automatically indexed and persisted into deep storage and made available for querying through historical nodes. Through the use of deep storage and exactly once semantics, Druid provides continuous backup to ensure a zero RPO for stream data.
Apache Kafka and Amazon can be considered as evolutionary to the earlier message bus era (e.g. TIBO, ActiveMQ, Rabbit MQ). One of their advantages lies in that they can support massive scalability. So it would only make sense that an analytics database can scale right alongside it.
Druid features a services-based architecture that independently scales ingestion and query processing practically infinitely. Druid maps ingestion tasks with Kafka partitions, so as Kafka clusters scale Druid can scale with it.
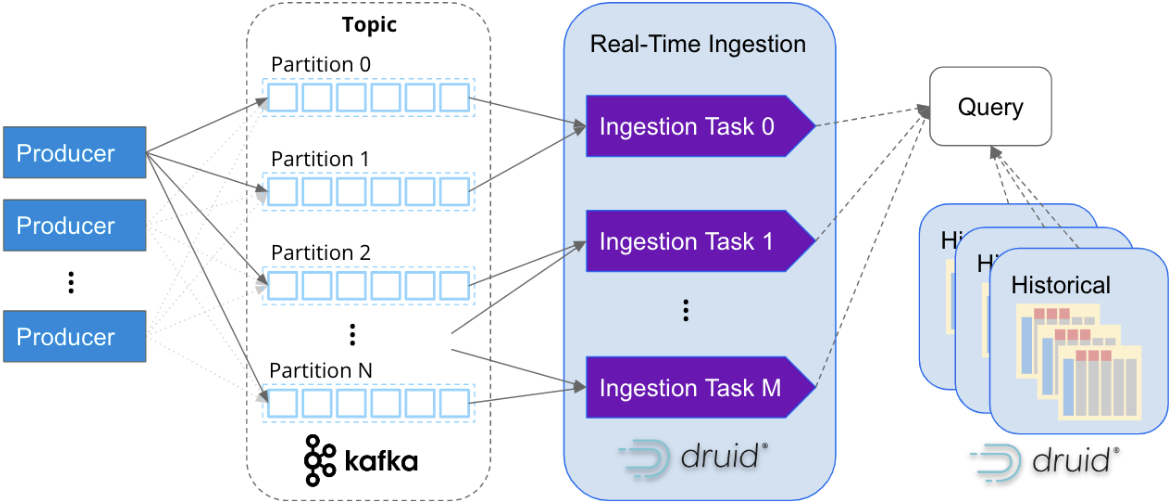
It’s not that uncommon to see companies ingesting millions of events per second into Druid. For example, Confluent – the originators behind Kafka – built their observability platform with Druid and ingests over 5 million events per second from Kafka.
Fast Insights
While real-time ingest is a key characteristic of Druid, it’s not the whole story. Apache Druid is a high performance database that can deliver sub-second queries on trillions of rows of high dimensional and high cardinality data, while supporting 100s to 1000s of concurrent queries.
It’s very common for Druid to support rapid, iterative-type queries for rapid data exploration or user-defined filters on 100s of dimensions with queries that come back in sub-second even if the data set is in terabytes to petabytes.
Apache Druid’s unique relationship between compute and storage resources is critical to this sub-second performance at scale. Druid’s unique storage format works in conjunction with the query engine to provide for that fast query performance. Rows are organized by a global time (and optionally additional dimensions) index which Druid uses at query time to quickly identify the necessary segments. Then for all dimension columns (such as name, product, location), Druid automatically creates a data dictionary and bitmap index, which creates significant space and performance advantages. With this data organization,
With this data format, Druid has everything ready for any common query, including filtering, grouping, top n, or aggregation, and has major advantages over other analytical databases. The segments are distributed across a cluster and then queried using a scatter/gather technique. Queries are automatically broken-down into subqueries and then fanned out for parallel processing across the cluster. Once all the sub-queries have been processed, Druid merges and returns the results.
So when you pull this all together you end up with a very scalable database for real-time analytics. It’s the architecture 1000s of data architects choose when high scalability, low latency, and complex aggregations are needed from real-time data.
User Story
How Netflix Ensures a High-Quality Experience
Real-time analytics plays a key role in Netflix’s ability to deliver a consistently great experience for more than 200 million users enjoying 250 million hours of content every day. Netflix built an observability application for real-time monitoring of over 300 million devices.

Using real-time logs from playback devices streamed through Apache Kafka and then ingested event-by-event into Apache Druid, Netflix is able to derive measurements that understand and quantify how user devices are handling browsing and playback.
With over 2 million events per second and subsecond queries across 1.5 trillion rows, Netflix engineers are able to pinpoint anomalies within their infrastructure, endpoint activity, and content flow.
Parth Brahmbhatt, Senior Software Engineer, Netflix summarizes it best:
“Druid is our choice for anything where you need subsecond latency, any user interactive dashboarding, any reporting where you expect somebody on the other end to actually be waiting for a response. If you want super fast, low latency, less than a second, that’s when we recommend Druid.”