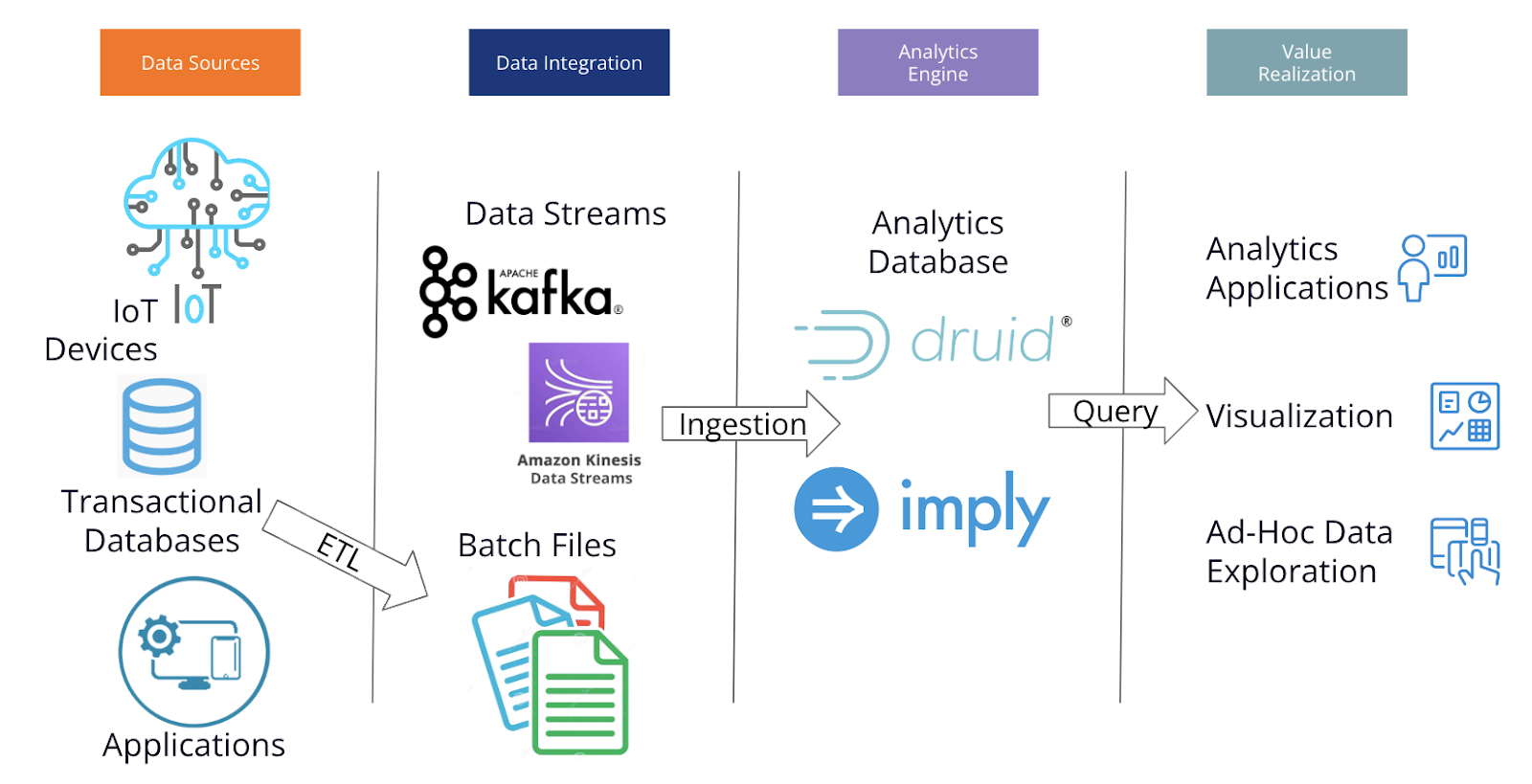
Do you want fast analytics, with subsecond queries, high concurrency, and combination of streams and batch data? If so, you want real-time analytics, and you probably want to consider the leading open source alternatives. Please see this blog article for a comparison between Apache Druid and Apache Pinot. Here, we’ll compare Apache Druid with ClickHouse.
Choosing a Database
Here’s a quick guide to choosing between these two database options:
Druid may be a better choice if you:
Want automatically managed indexes
Have many data sources or schemas that change, and want automated management
Want to JOIN different data sources or use SQL transformation as part of data ingestion
Need to ensure that high-priority queries aren’t slowed by lower-priority queries
Require a mix of high performance for recent and frequently-accessed data with lower costs for older and less accessed data
ClickHouse may be a better choice if you:
Don’t need low-latency stream ingestion, and can afford to wait for microbatching
Have few data sources that never (or rarely) change
Never (or rarely) need to scale your cluster up or down to adjust to changing needs
Can mix all queries into a single pool without differentiating priorities
Have limited technical skills, so you need a more simple environment
If you’d like to learn more about why each database works the way it does, read on!
What is real-time analytics?
When you need insights and decisions on events happening now, you need real-time analytics.
Analytics is a set of tools to drive insights to make better decisions. Sometimes this is providing useful information to humans, using dashboards, charts, and other reports to enable better decisions. Sometimes this is providing actionable information to machines, making automated decisions.
Some analytics are not very time-sensitive, such as daily or weekly reports. Data warehouses and data lakes are designed to deliver these reports.
Real-time analytics features fast queries, usually under 1000ms, with aggregates and rollups while maintaining access to the granular data. It includes fast ingestion of both stream and batch data, and works at any scale, from GBs to PBs. It combines queries on current streams with historical batch data, providing insights in context. It supports high concurrency, with hundreds or thousands of concurrent queries, It is always on, with near-zero downtime (zero planned downtime) and continuous backup.
Both Apache Druid and ClickHouse are databases designed for real-time analytics.
How does Druid work?
Built for Scale and Performance
Druid is a database designed to support any application at any scale, using its elastic and distributed architecture. A unique storage-compute design with independent services enables both performance and scalability.
Smart Data Handling
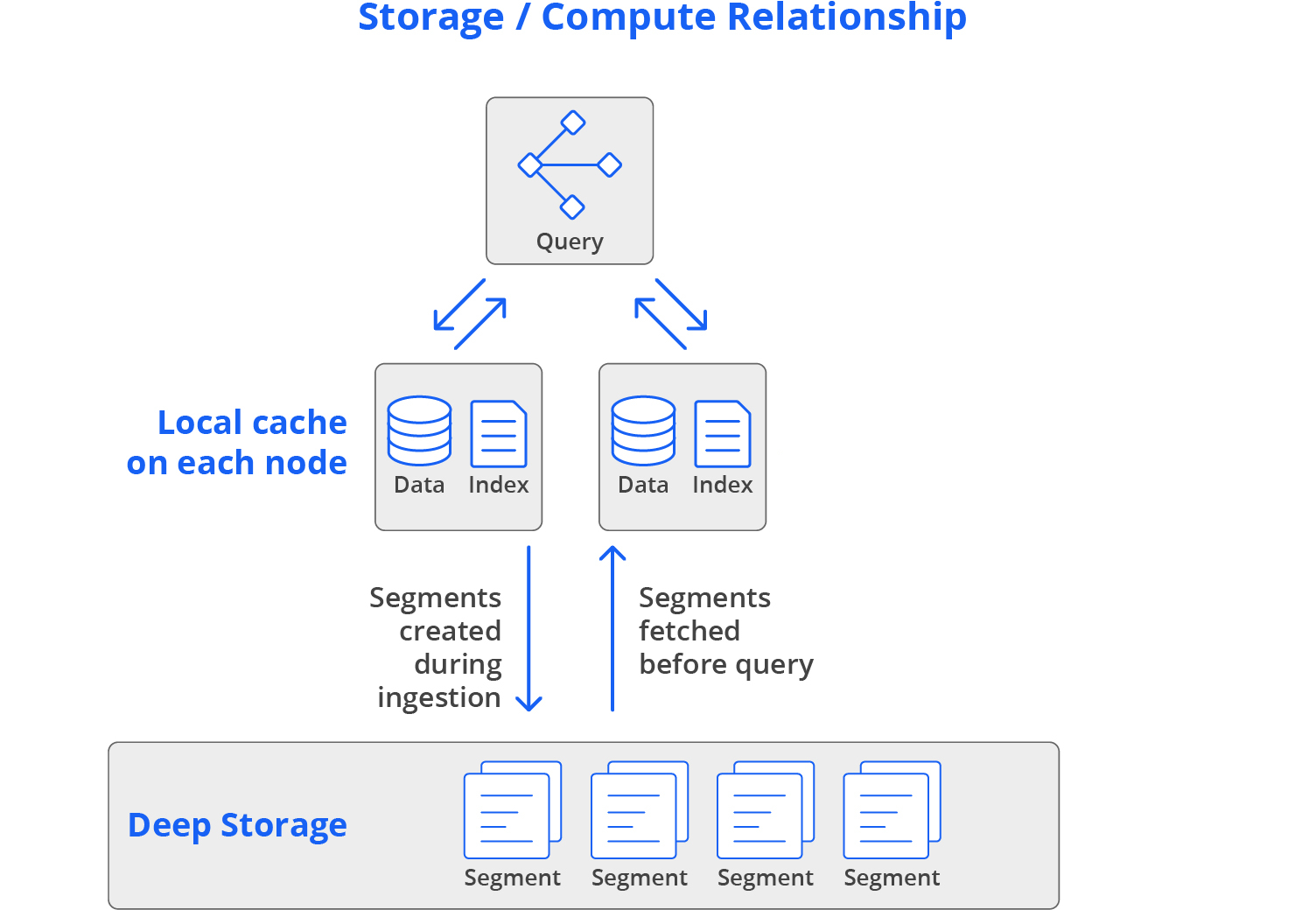
Ingested data gets sliced into segments, stored by column, fully indexed, and optionally pre-aggregated. Unlike other analytics databases, Druid avoids trade-offs: it delivers both performance and affordability. Segments reside in cloud storage and are pre-fetched for subsecond queries. Older data can be stored in low-cost deep storage with lower performance.
Druid’s unique storage-compute approach combines the “separate” and “local” methods used by other databases, providing high performance, concurrency, cost-efficiency, and resilience.
For less-accessed data, Druid can query directly from deep storage, optimizing costs. It automatically manages data placement based on rules like storing older data in deep storage.
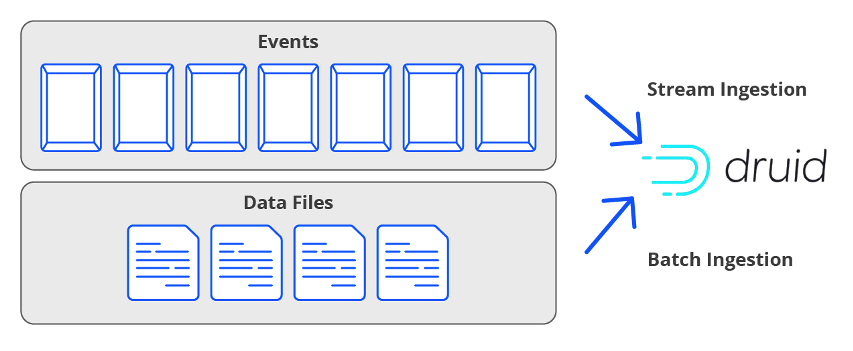
Data Ingestion
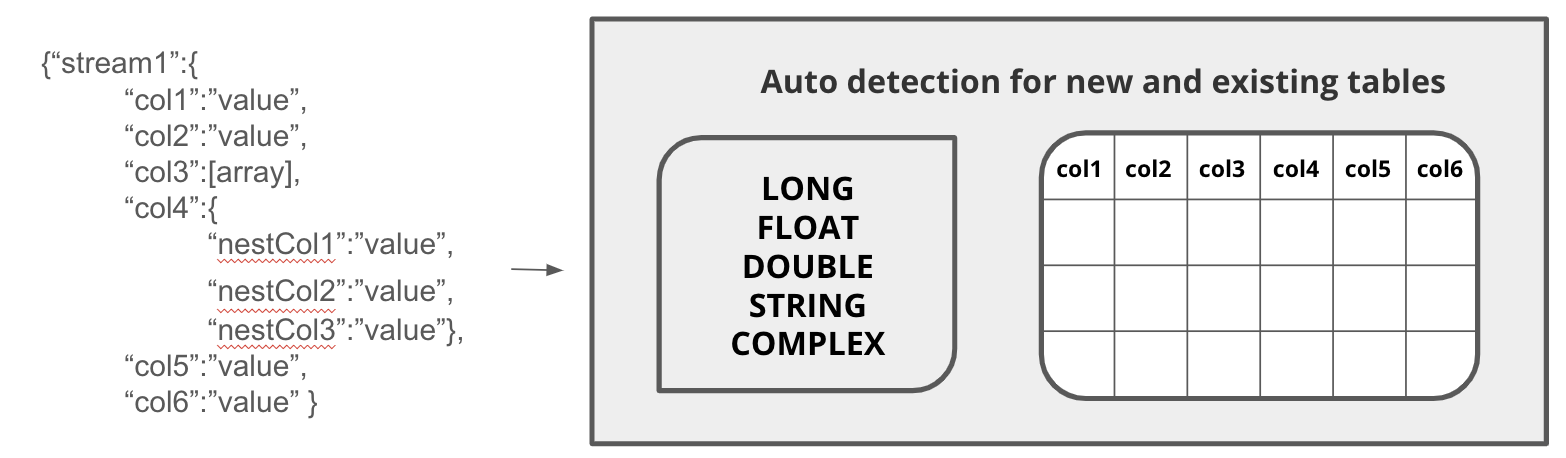
Druid offers dedicated processes for batch (CSV, TSV, Parquet, and others) and stream ingestion (Kafka, Kafka-compatible, and Kinesis). Both process types automatically detect schema and create tables. Batch data gets stored in indexed columns based on data type, forming “segments” across high-speed cache and deep storage. Every event in every stream is immediately available for query, with background indexing eventually converting the stream data into segments.
Segments are stored in durable deep storage, with replicas in high-speed cache on data nodes for high performance.
Scale on Demand
Each Druid service scales independently. Any type of node can be added or removed dynamically as needs change.. A small cluster runs on one machine, while giants span thousands of servers, ingesting millions of events per second and querying billions of rows in milliseconds.
Performance Through Efficiency:
Druid’s “do it only if needed” philosophy fuels its speed. It minimizes cluster workload by:
Avoiding unnecessary disk, memory, and CPU data transfers.
Operating directly on encoded data.
Using smaller indexes instead of full datasets.
Reusing long-running processes instead of new ones per query.
Minimizing data movement across processes and servers.
Zero Downtime:
Self-healing, self-balancing, and fault-tolerant, It’s durable, safeguarding data against major system failures using deep storage (object storage like Amazon S3, Azure Blob, Google GCS, or on-premise HDFS) with 99.999999999% durability. Druid never needs planned downtime, as all updates can be applied while the cluster continues to operate. When infrastructure fails, Druid continues to operate, and replacement infrastructure can be added dynamically.
With every segment stored in durable deep storage, Druid creates a continuous backup. Even if all nodes fail at once, there is zero data loss.
Deployment Options:
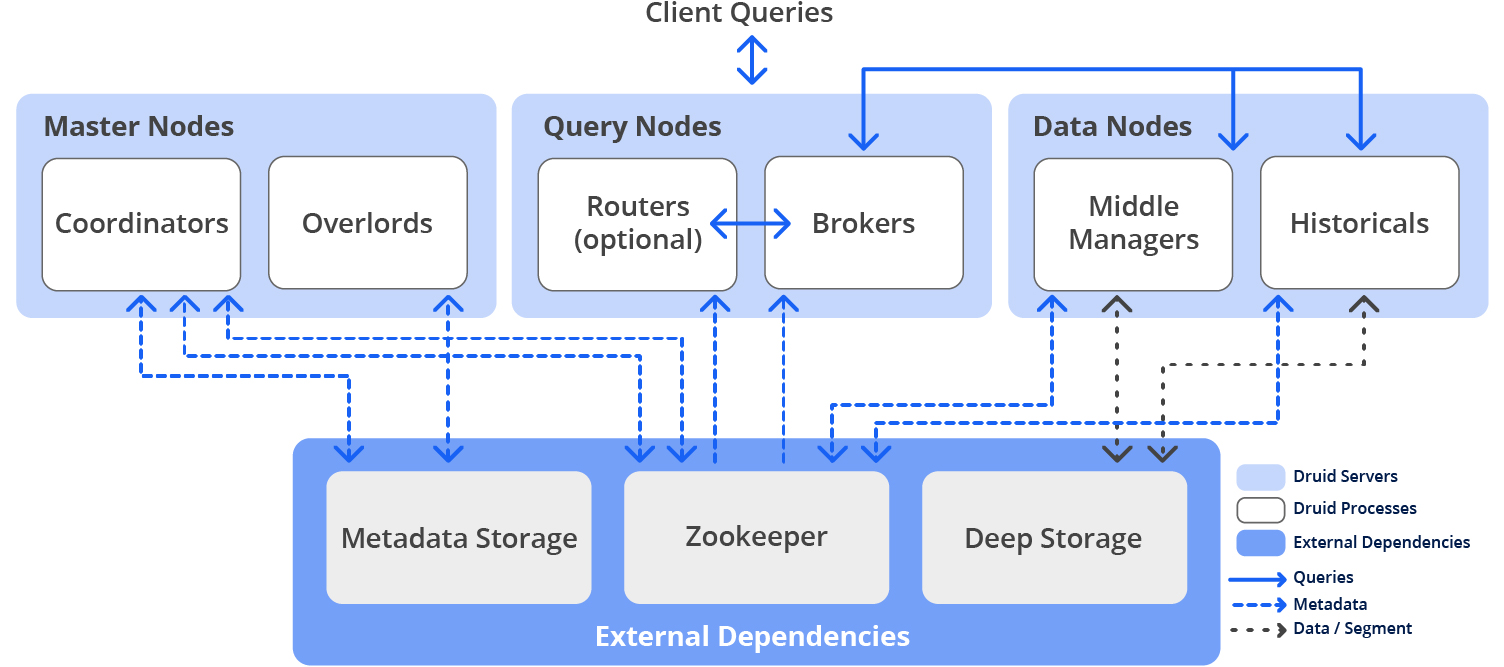
Druid runs on clusters with multiple processes, typically deployed on three server node types:
Master Nodes: Manage data availability and ingestion.
Query Nodes: Accept, execute, and return query results.
Data Nodes: Handle ingestion tasks and store queryable data.
Small setups can run all nodes on one server. Larger deployments dedicate servers to each node type.
Druid deploys as part of a data pipeline, ingesting data from one or more sources and powring visualization, data exploration, and analytics applications.
How to Get Stated:
Download open source Druid from druid.apache.org or read “Wow, That was easy”. If you want support, management tools, and even a fully-managed services, you can purchase it from Imply and other providers..
How does ClickHouse work?
ClickHouse was developed by a team at Yandex, Russia’s largest provider of internet services, originally as a tool for reporting advertising metrics.
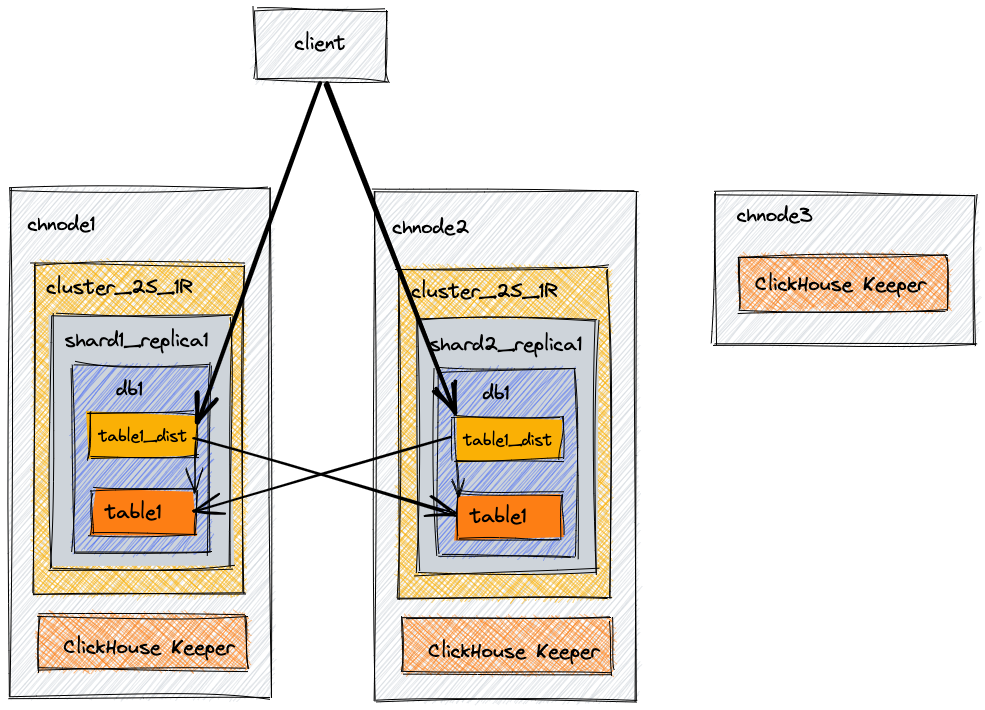
The architecture is monolithic, with nearly all functions consolidated into a single ClickHouse server, which manages queries, data, ingestion, and management. Multiple servers can be part of a single cluster, usually with one server installed per physical (or virtual) server.
Mapping of processes to physical architecture uses a “keeper” process, either Apache Zookeeper or the more recent ClickHouse Keeper. The keeper is usually implemented alongside a ClickHouse server on the same infrastructure.
Like Druid, the cluster can be scaled up or down by adding or removing nodes. While Druid rebalances the cluster as a background process, ClickHouse cannot rebalance while the cluster is operating, so changing the cluster requires a planned outage, which could be anywhere from minutes to days depending on the size of the cluster.
Like Druid, ClickHouse uses columnar storage. Unlike Druid, in ClickHouse, the column is also the basic storage unit, with each column stored as one or more files. Also unlike Druid, Tables must be explicitly defined using CREATE TABLE before data can be ingested, similar to older relational databases like Oracle.
Ingestion into ClickHouse is exclusively through a batch process via Integrations to various file types (such as CSV, Parquet, or Iceberg), databases, and stream providers. ClickHouse is designed to ingest batches of 1000+ rows at a time, so incoming stream data is cached until enough arrives to trigger a batch ingest. This approach simplifies ingestion, at the cost of delay for real-time incoming data from Kafka, Kinesis, or other streams.
ClickHouse tables must have a primary key. Unlike transactional databases, this key need not be unique, but it is used as a primary index to sort the data in the table. Secondary indexes can be manually created and managed.
Unlike Druid, ClickHouse doesn’t have a deep storage layer for continuous backup. Backups must be scheduled and managed, In an outage, all data since the last backup can be lost.
ClickHouse is distributed under the open source Apache 2.0 license, and can be downloaded and installed from GitHub. Unlike Druid, ClickHouse is not a project of the Apache Software Foundation, so there is no guarantee that future releases will continue to be open source. Several organizations offer commercial support and ClickHouse-as-a-Service, including Yandex, Altinity, Alibaba, Aiven, and clickhouse.com.
How are Druid and ClickHouse different?
Druid and ClickHouse have a lot of similarities. Still, there are a few key differences worth considering.
Both databases are developed and used for high performance queries across large data sets. The key differences are indexing, ingestion, concurrency, mixed workloads, and backups.
Indexing
Auto-index applies the best index to each column
User must choose and manage indexes for each column
Ingestion
Both batch and stream ingestion. Events in streams are immediately available for query. Schema for incoming data is auto-detected. If new data has a different schema, the table can be automatically adjusted to fit the data.
Only batch ingestion. Streams are ingested through micro-batching, with a short delay before availability. Schema for every table must be explicitly defined before data is ingested. If new data has a different schema, ingestion fails.
Concurrency
Supports hundreds to thousands of concurrent queries.
Recommended limit of 200 concurrent queries
Mixed Workloads
Query laning and service tiering to assign resources to queries based on priority.
All queries are in one pool, so can only assign priority by creating multiple ClickHouse clusters
Backups
All data continuously backed up into Deep Storage. Zero data loss during system outages.
Backups must be scheduled and managed. In an outage, all data since the previous backup can be lost.
Indexing
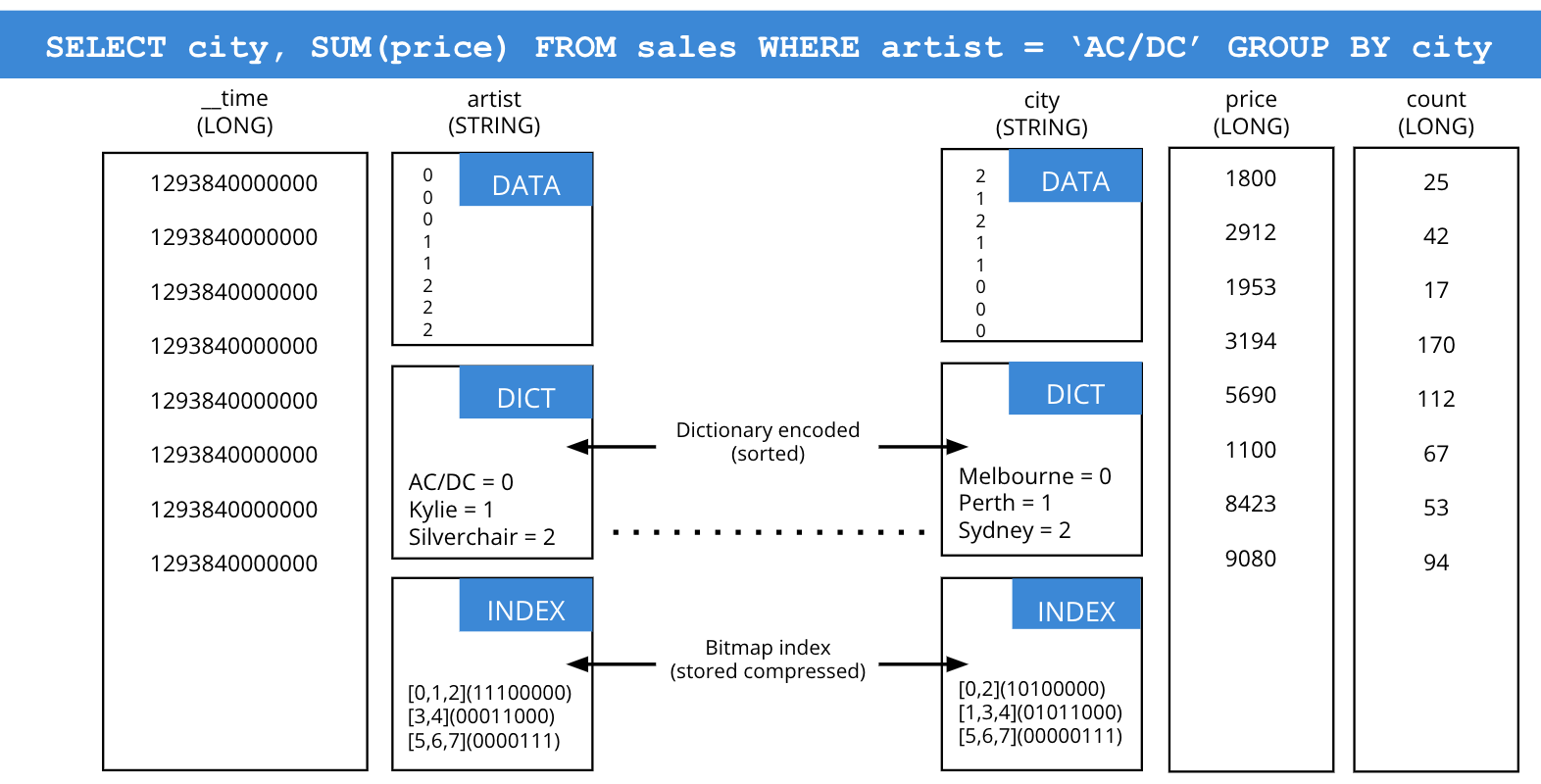
Druid auto-indexes all data, automatically applying the best index for each column’s data type, such as text strings, complex JSON, and numeric values. High-efficiency bitmap indexes, inverse indexes, and dictionary encoding indexes are created and applied to maximize the speed of every query. There is no need to manage indexes in Druid.
Indexing in Druid: automatic for each column and tightly integrated with the query engine.
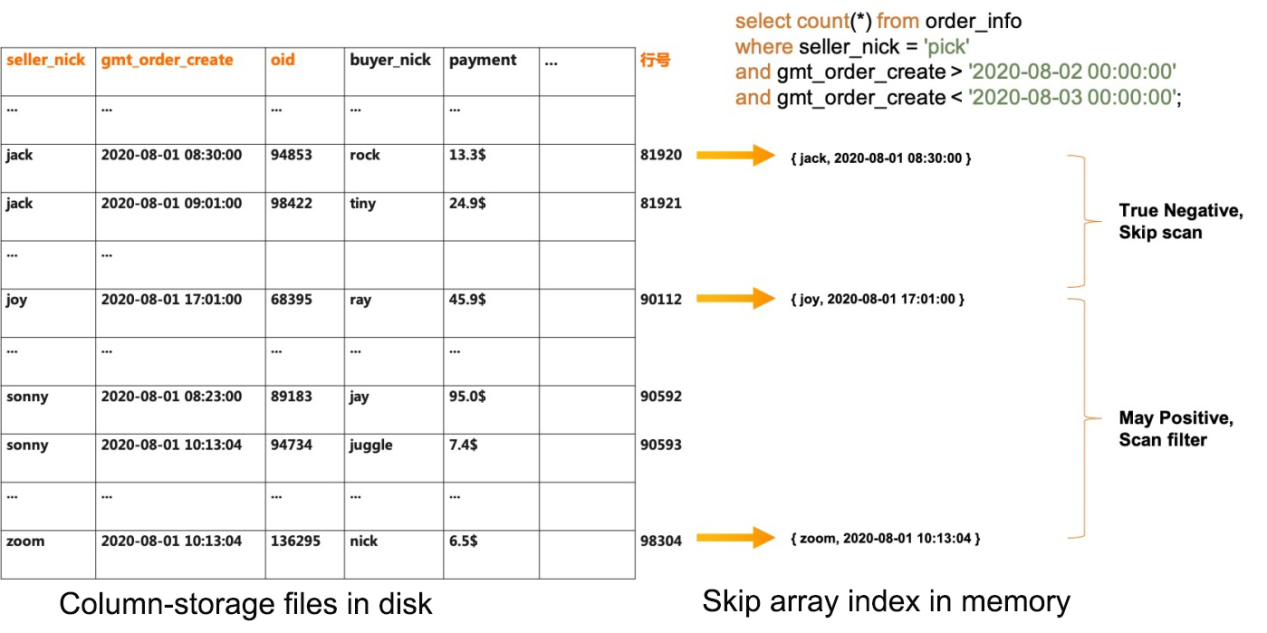
ClickHouse organizes each table by a primary key, which does not need to be unique to each row. Secondary indexes (called “data skipping indexes”) can be created and managed to improve query performance, at the cost of slower ingestion performance.
Indexing in ClickHouse, using data-skipping indices. Source: Alibaba
Like transactional databases, ClickHouse administrators often invest significant time to monitor an optimize indexes to balance ingestion performance vs. query performance.
Ingestion
Both Druid and ClickHouse can ingest both batch data and streaming data.
In Druid, batch data can be ingested using either SQL commands or a JSON ingestion spec. During ingestion, different data sources can use SQL for transformation, using JOINs, rollups, and other SQL techniques.
Druid includes inherent ingestion from Apache Kafka, Kafka-compatible streams (such as Confluent, Redpanda, Amazon MSK, and Azure Event Hubs), and Amazon Kinesis – no connectors needed! Every event in each stream is immediately available for query.
Ingestion in Druid: different processes to ingest events (stream data) and files (batch data).
ClickHouse ingestion is through Integrations: a broad set of core (officially supported), partner (supported by 3rd parties), and community (unsupported) tools to connect a source to ClickHouse. There are over 100 Integrations, covering file types, databases, and programming languages.
All ingestion in ClickHouse is batch ingestion. Using stream Integrations caches incoming events until enough have arrived to trigger a batch, creating a delay between events entering a stream and becoming available for queries.
Schema auto-discovery in Druid, identifying each column and changing, if needed, as future data ingesting has a different shape. In ClickHouse, all columns must be explicitly typed and manually adjusted.
In addition, Druid (but not ClickHouse) offers schema auto-discovery, where column names and data types can be automatically discovered and converted into tables without requiring explicit definition. This enables easier ingestion for wide data sets and can automatically adjust table schemas when data sources change.
Concurrency
Both Druid and ClickHouse support higher levels of concurrency than most other OLAP databases. Druid is designed for very high concurrency, with many uses executing 5000 or more concurrent queries.
ClickHouse’s default setting allow 100 concurrent queries, though this can be increased to 200, if needed.
Mixed Workloads
Sometimes, you need to manage a mix of different requirements, with some high-priority queries that need the top performance mixed with lower-priority queries that don’t need to be as fast.
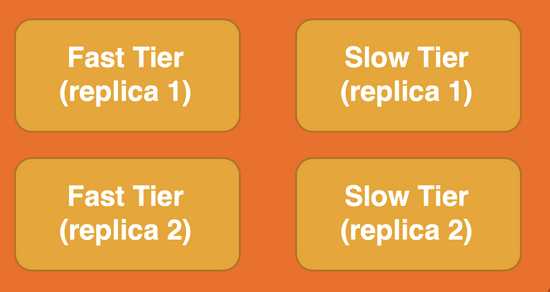
Query laning in Druid. ClickHouseCl lacks this capability.
Druid includes Query Laning, where any number of tiers can be created to separate queries with different priorities or any other reason for separation (such as segregating workloads from different business units). This ensures that, no matter how many lower-priority queries are being submitted, the high-priority queries always get the resources needed.
Druid also includes Query from Deep Storage, which provides a low-cost, lower-performance option (sometimes called a “Cold Tier”) for older and infrequently used data.
ClickHouse lacks the ability to segregate workloads by priority.
Backups
In Druid, every segment is committed to deep storage, a high-durability object store (Amazon S3, Azure Blob, Google GCS, on-premise HDFS, or similar). This creates a continuous backup, with 99.999999999% durable storage. Druid has zero data loss, even if all processing nodes fail.
ClickHouse, like older database, requires scheduling and managing backups. In the event of a system outage, all data since the last backup is at risk of loss.
Choosing a Database
If your project needs a real-time analytics database that provides subsecond performance at scale you should consider both Apache Druid and ClickHouse..
The easiest way to evaluate Druid is Imply Polaris, a fully-managed database-as-a-service from Imply. You can get started with a free trial – no credit card required! Or, take Polaris for a test drive and experience firsthand how easy it is to build your next analytics application.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...