Our mission at Imply is to help you develop modern analytics applications powered by Apache Druid. Interactivity is the most important feature of these apps, and this is where Druid-based apps really excel. Interactive slice-and-dice, at scale, without precomputation, is the main reason people choose to use Druid, and I’m very proud of the speed that we are able to deliver to developers. The largest Druid installations scale to petabytes of data, served by thousands of data servers, and are able to return queries on billions and billions of rows in less than a second.
At Druid Summit in November, I shared our plans for Project Shapeshift, an effort to improve the Druid experience to be more cloud-native, simple, and complete. Today I’d like to share one important way that we’re executing on this vision.
Experience tells us that while Druid excels at interactive slice-and-dice, this is not the full story for a modern analytics app. There are other user-facing features that analytics apps need, like data export and reports, that rely on much longer-running or more complex queries. In Druid, these workloads have historically been limited by bottlenecks at the Broker, a situation that I’ll explore further in the next section. Today, people often handle these workloads by using other systems alongside Druid. But this adds cost and complexity: the same data must be loaded up twice and two separate data pipelines must be managed.
To tackle all of this, we set out to build a multi-stage query engine for Druid that eliminates this bottleneck. And once we started thinking it through, we realized that if we did it right, we could do much more than just handle more complex queries. We could open up the ability to run queries and ingestion using a single system and a single SQL language. We could move past the need to have separate operational models for ingestion and query execution. We could enable querying external data, and enable deployment modes with separated storage and compute. Together, these effects will elevate the functionality and transform the economics of Druid, and set a new standard for real-time analytics databases.
Today, I’m prepared to share our progress on this effort and some of our plans for the future. But before diving further into that, let’s take a closer look at how Druid’s core query engine executes queries, so we can then compare it with the multi-stage approach.
Druid query execution today
A few years back, an image listing “the rules of perf” at Dropbox circulated on the nerdier corners of the web and sparked a conversation about high-performance programming. The number 1 rule on the list was “Don’t do it”. That’s really good advice!
Performance is the key to interactivity, and in Druid, “don’t do it” is the key to performance. It means minimizing the work the computer has to do.
Druid doesn’t load data from disk to memory, or from memory to CPU, when it isn’t needed for a query. It doesn’t decode data when it can operate directly on encoded data. It doesn’t read the full dataset when it can read a smaller index. It doesn’t start up new processes for each query when it can use a long-running process. It doesn’t send data unnecessarily across process boundaries or from server to server.
Druid achieves this level of efficiency through its tightly integrated query engine and storage format, designed in tandem to minimize the amount of work that each data server has to do. Druid also has a distributed design that partitions tables into segments, balances those segments automatically between servers, quickly identifies which segments are relevant to a query, and then pushes as much computation as possible down to individual data servers.
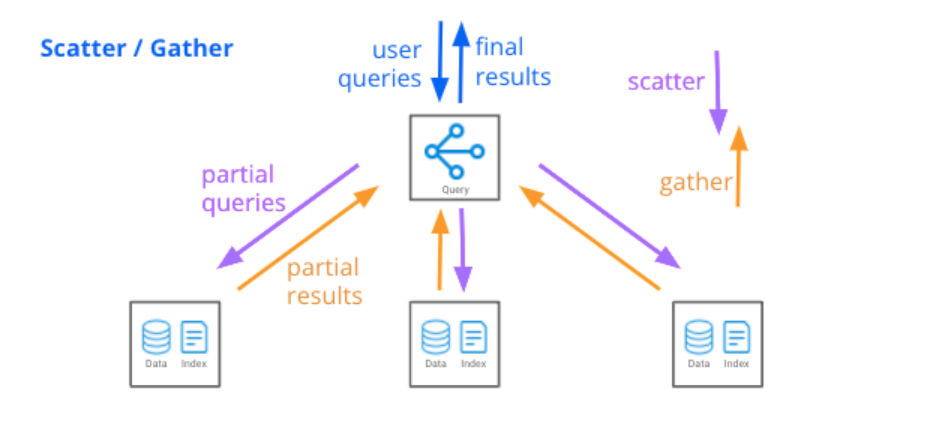
Druid’s query entrypoint, which we call a Broker, executes these queries with a “scatter/gather” technique: it fans out chunks of the query to each relevant data server, gathers filtered and aggregated results from each server, then performs a final merge and returns results to the user. Each data server may be processing billions of rows, but the partial resultset returned to the Broker is much smaller due to pushed-down filters, aggregations, and limits. So, Brokers do not have to deal with large amounts of data. This design means a single Broker can handle a query that spans thousands of data servers and trillions of rows.
Taken together, this design means that Druid can execute typical analytics app queries, like these, lightning-fast and at high scale:
SELECT
browser,
browser_version,
COUNT(*) AS "Count",
APPROX_COUNT_DISTINCT(sessionId) AS "UniqueSessions"
FROM website_visits
GROUP BY 1, 2
ORDER BY UniqueSessions DESC
LIMIT 150
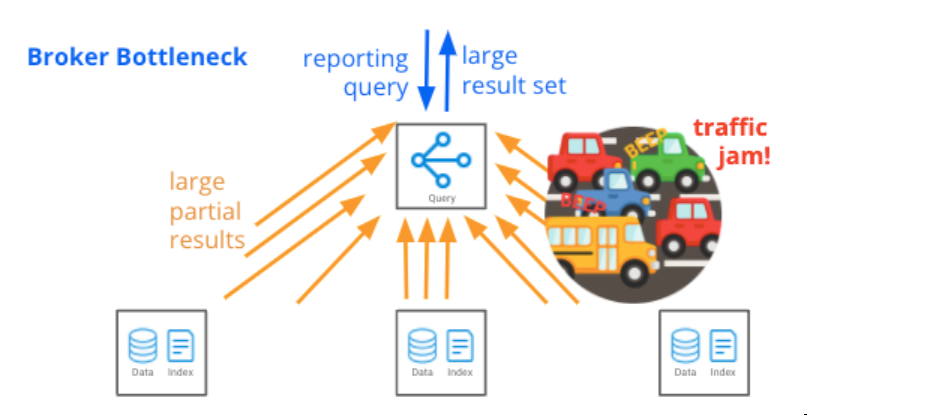
The scatter/gather technique is efficient for these common queries, and enables Druid to scale to petabytes of data served by thousands of data servers. It works because the bulk of processing is done on distributed data servers, and a relatively small amount of filtered and aggregated data is sent to the Broker to return to the caller. But the technique has one Achilles’ heel: the Broker can turn into a bottleneck when query results are very large, or when a query is structured in such a way that multiple passes over the data are required.
You might be wondering what kinds of queries lead to these sorts of bottlenecks. Some examples include:
Data exports, and long downloadable reports, can generate result sets that are too large to efficiently process on a single machine. In Druid today, this leads to a bottleneck at the Broker, because all query results flow through the Broker.
Exact distinct count requires one pass to compute distinct values, and another pass to count them. In Druid today, the Broker gathers all distinct values from data servers and then counts those values. If there are a large number of distinct values, then gathering those values creates a bottleneck at the Broker. To avoid this today, Druid offers the APPROX_COUNT_DISTINCT family of functions, which operate using a single pass and are free of bottlenecks no matter how many distinct values are being counted. The error of these functions is quite low and they are suitable for highly-interactive, application-oriented use cases. However, some use cases cannot tolerate even small errors and so they require exact distinct counts.
GROUP BY + ORDER BY <aggregation> + LIMIT requires one pass to group the results and a second pass to order and limit them. In Druid today, data servers first compute the grouped results; then, the Broker gathers, orders, and limits the results. If the grouped result set prior to LIMIT is large, gathering it all on the Broker creates a bottleneck. This comes up when grouping on high-cardinality fields. To avoid this bottleneck today, Druid offers an approximate TopN option, which operates in a single pass and is free of bottlenecks no matter how large the pre-LIMIT result set is. In real-world cases the error of approximate TopN is quite low, and the performance gains make it well-suited for highly-interactive, application-oriented use cases. However, when you are doing a report or a data export, absolute correctness becomes more important than speed, which makes approximations less desirable.
Joins between distributed tables, including self-joins on a single distributed table, are implemented in the scatter-gather framework by executing all but the leftmost input as subqueries. The results of those subqueries are broadcast globally and joined to the leftmost input, which remains distributed. This approach only works when the right-hand inputs to a join are of broadcastable size.
A new query engine
When we set out to rethink how queries could work in Druid, we knew that it was important to keep all the good aspects: namely, very tight integration with the storage format, and excellent data server performance. We also knew w e needed to retain the ability to use a lightweight, high-concurrency scatter/gather approach for queries where the bulk of processing can be done on the data servers. But we would have to also support exchanging data between data servers, instead of requiring that every query use scatter/gather.
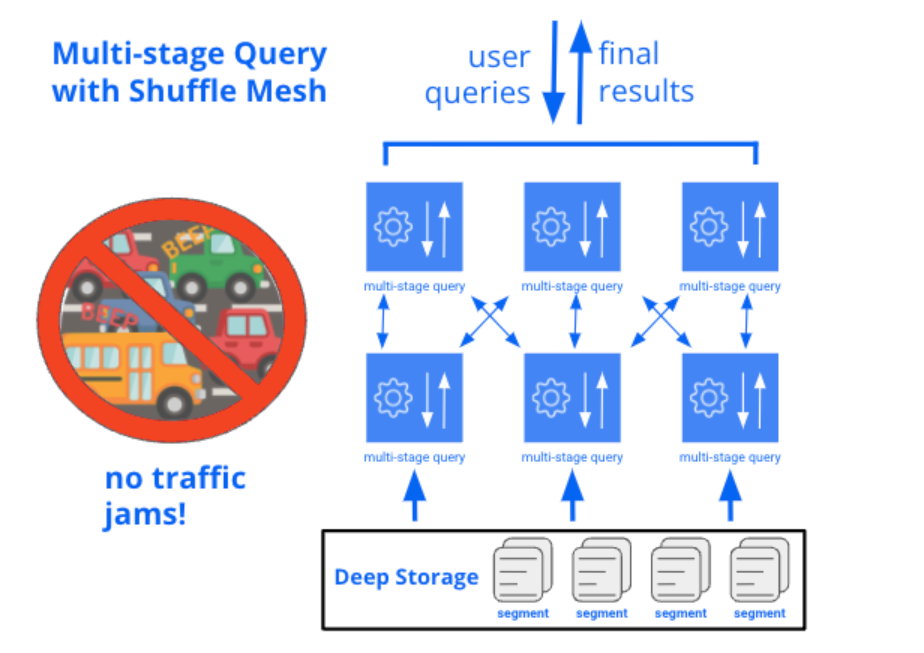
To accomplish this, we’re building a multi-stage query engine that hooks into the existing data processing routines from Druid’s standard query engine, so it will have all the same query capabilities and data server performance. But on top of that, we’re adding a system that splits queries into stages and enables data to be exchanged in a shuffle mesh between stages. Each stage is parallelized to run across many data servers at once. There isn’t any need for tuning: Druid will be able to run this process automatically using skew-resistant shuffling and cooperative scheduling.
By allowing each stage of a multi-stage query to run distributed across the entire cluster, we can efficiently carry any amount of data through all stages of the query, instead of requiring that the bulk of data is processed at the bottom layer.
And on the other hand, single-stage queries will still be able to execute using the same efficient, lightweight technique that Druid uses today.
Ingestion and external data
It would be a shame to use a new multi-stage, shuffle-capable query engine only for doing queries. We can take it one step further: this also lets us totally reimagine ingestion! The key is to think of ingestion as a query that reads external data, clusters and partitions it, and writes the result to a Druid table.
Many databases support “INSERT INTO SELECT” or “CREATE TABLE AS SELECT” to do something like this. In Druid, where new-table creation and inserting into an existing table are typically done using the same command, it’s natural to add “INSERT INTO SELECT”. And because ingestion in Druid is typically pull-based, we’re also building functions that read external data into the query engine. Putting these ideas together, here’s an example of an ingestion job that would read JSON data from S3 into the table pageviews:
INSERT INTO pageviews
SELECT
TIME_PARSE("timestamp") AS __time,
channel,
cityName,
countryName
FROM TABLE(S3('s3://bucket/file', JSON()))
PARTITIONED BY FLOOR(__time TO DAY)
CLUSTERED BY channel
INSERT queries should also be able to read data that already exists in Druid. So, here’s an example of a query that would read from a detailed table pageviews and creates a filtered and aggregated copy in pageviews_fr_rollup:
INSERT INTO pageviews_fr_rollup
SELECT
FLOOR(__time TO HOUR) AS __time,
channel,
cityName,
countryName,
COUNT(*) AS viewCount
FROM pageviews
WHERE language = 'fr'
GROUP BY 1, 2, 3, 4
And, of course, the external data functions would be usable without the INSERT keyword. In that case, Druid would directly query the external JSON data. I don’t think that querying external data directly like that will become a primary use case for Druid; it’s more the domain of query federation systems. But I do think that there are times where it will be useful, like “peeking” at external data prior to a full INSERT, or performing ad-hoc joins of Druid data with external data.
An option to further separate storage and compute
The last item I want to talk about is a really interesting one: the potential for additional separation between storage and compute. I’m particularly excited about this, because it is a “have your cake and eat it too” situation: Druid will be able to offer a wide variety of architectures that give you the exact economics that you need.
To explain what I mean, first a little background: most databases today either use separate storage or local storage. With separate storage, all ingested data resides on a remote storage system; generally that’s cloud object storage, like S3, or a distributed filesystem, like HDFS. Databases with separate storage query data directly from that remote storage, potentially with some caching. This allows compute capacity to be bursted up and down quickly, which is great for infrequently-accessed data or irregular query load.
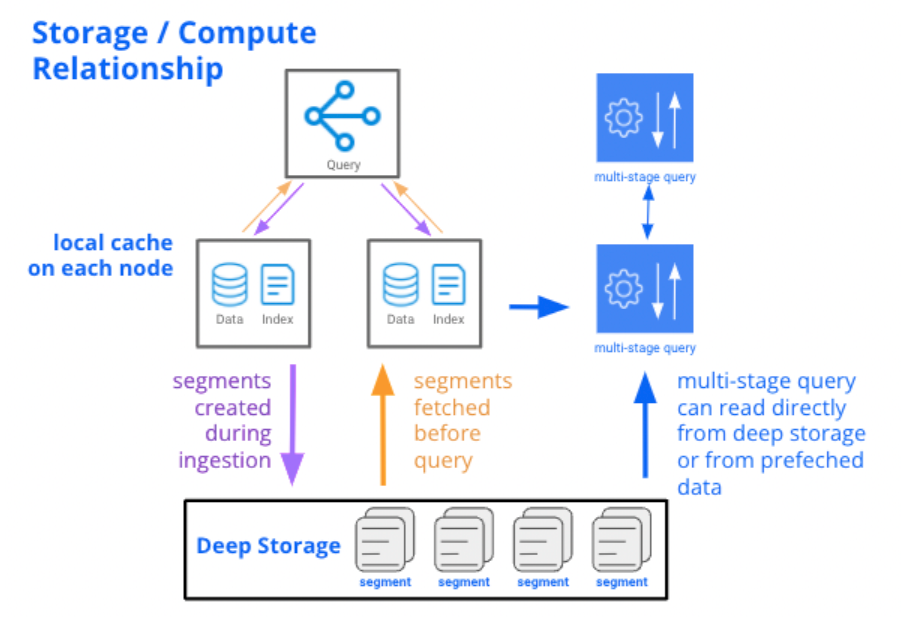
But there is a downside to fully separating storage and compute: these systems don’t perform as well as systems that store data locally on data servers. We know this because Druid’s very first incarnation actually did completely separate storage and compute, with a caching layer, similar to today’s cloud data warehouses. We found that this didn’t work well for application-oriented use cases: the system performed well when the cache was warmed up, but performance on cold cache was not where we needed it to be. We realized that it was important to warm the cache before queries hit the cluster.
So Druid today has a unique relationship between storage and compute, blending the “separate” and “local” approaches. It uses separate storage, which we call “deep storage”, which makes it easy for you to scale Druid up and down: simply launch or terminate servers, and Druid rebalances which segments are assigned to which servers. But it also preloads all data into local caches before queries hit the cluster, which guarantees high performance: there is never a need to load data over the network during a query. In the vast majority of cases, data will already be cached in memory. And even if it isn’t, it will be available on the local disk of at least two data servers. This unique design gives Druid the elasticity and resilience of separate storage, but the performance profile of local storage.
For frequently-accessed data where load is relatively steady, Druid’s approach is perfect: the best of both worlds! But there is one downside: it requires enough disk space across the cluster to cache the entire dataset. For datasets that must be available in real-time, this is actually a good thing, because in these cases performance is so important that you’d want the data available locally anyway. But for other, less-interactive and less-real-time use cases, this isn’t always worth it.
The most common example is actually the same kind of reporting query that originally inspired us to build a new query engine. Imagine an app where users typically interact with one month’s worth of their data at a time, but in some infrequent cases will request a downloadable report that covers years’ worth of their data. The ideal architecture here would be to size your persistent cluster footprint for the typical month-based workload, and burst up temporarily to handle the infrequent, heavier workloads as they come in.
That’s where the new and improved query engine comes in. We’re making sure it will support an optional ability to query ingested data directly from remote storage, without the requirement for prefetching. This is full separation of compute and storage, and I expect that it’ll be especially desirable for these more infrequent, less performance-sensitive use cases. You will be able to choose whether you want the high performance of prefetching, or the flexibility of querying directly from remote storage, on a fine-grained table-by-table or interval-by-interval basis. I’m particularly excited about offering this option, because it will ensure that we can always fit into the correct price/performance sweet spot for any application.
Stay tuned
Today, we’re starting a preview program where we’re making an early version of this query engine available to Imply customers for feedback. This early version sits alongside Druid and provides an alternate query endpoint ideal for heavier-weight queries, batch ingestions, and create-table-from-query workloads. If you’d like to try out this early version, please contact us.
We’ve also begun to work with the community to contribute this engine back to the project and integrate it deeper into Druid. The first act we took is to publish a community proposal, which you can check out and comment on at: https://github.com/apache/druid/issues/12262. I’m very excited about getting these capabilities into the hands of everyone that uses Druid, because this work will make Druid an even better platform for building analytics experiences, and will set the standard for real-time analytics databases for years to come.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...