Clickstream Analysis – An Open Source Architecture
Jun 12, 2019
Mike McLaughlin
Making decisions and asking questions about the digital services you provide should be easy. But the data you need is filtered and processed before it reaches you – often when it’s too late. A triad of open source projects – Divolte, Apache Kafka and Apache Druid – can power real-time collection, streaming and interactive visualisation of clickstreams, so you can investigate and explore what’s happening on your digital channels as easily as looking out of your office window.
User behavior in digital applications is recorded as a stream of individual events, chronicling every step a visitor takes as they travel around websites, read articles, clicked links and submitted forms.
For many years, this data was accessible only to server administrators, collected as web server logs in such volume and complexity that gaining business insight was challenging. But as digital channels rose in prominence to the mission critical status they have today, so rose the importance of figuring out how to harness this data to quickly understand customer behaviour and profiles and make impactful business decisions.
Popular products like Google Analytics and Adobe Analytics (fka Omniture) were built in the 2000s to address this need and provide ways to surface this data to various teams in the organization. These tools store the data on hosted platforms and provide a limited set of preformatted and often delayed views of user interactions.
As digital channels have proliferated and increased in both business criticality and data speed and volume, product and market development strategists need faster and more flexible access to this behavioural data, even as data sets balloon to massive modern scale. They need an intuitive interface that lets them explore always fresh data in real-time, feeding their curiosity and enabling proactive decision-making. They cannot act quickly and with confidence if that data is late and pre-packaged.
Now three open source software (OSS) projects allow you to keep data flowing down the Data River from digital citizen to digital decision-maker for ad-hoc exploration on real-time data, while putting your clickstream data back under your own control: where it’s held, what’s held, and how long it’s held for.
A new stack for clickstream analysis
Using open source technologies to build a powerful, scalable, fault-tolerant, and real-time clickstream analytics service is easier than you might expect. All the components are readily available and are ever-improving thanks to an army of committed and devoted individuals and organizations.
Let’s look at the stack to make this all work: the DKD clickstream stack comprising Divolte, Apache Kafka, and Apache Druid. The details of each component are described below.
Data Producer: Divolte
Divolte can be used as the foundation to build anything from basic web analytics dashboarding to real-time recommender engines or banner optimization systems. By using a small piece of JavaScript and a pixel in the browser of the customers, it gathers data about their behaviour on the website or application.
The Apache-licensed Divolte tool was open-sourced by GoDataDriven, who commit to key open source projects, such as Apache Airflow and Apache Flink.
The server-side component is the Divolte Collector, which receives events from a lightweight client-side Javascript component embedded in your web site or application. Once embedded, this component will automatically collect and send details to the Divolte Collector. It’s scalable and performant server for collecting clickstream data and publishing it to a sink, such as Kafka, HDFS or S3.
The details included in the default dataset provides a wealth of information. Here is a sample of what is included broken down into categories:
Session
Activity
Device
First Session?
Page Visit Identifier
IP Address
Referring Site
Page Url
Viewport & Screen Size
Session Identifier
Page Action Type
Browser Information
Visitor Identifier
Time & Date Requested
Device Type
Time & Date Received
Operating System Information
You can go further by introducing new events and data to add richness and breadth to the default. An example would be to trigger a message to be recorded as users scroll down long-form pages, and publish this to a real-time dashboard so that content editors can adapt their content minutes after publication to drive up ad impressions and improve the quality of their output.
Data Broker: Kafka
These attributes collected by Divolte can be streamed in real-time from straight into Apache Kafka with a simple configuration change.
A typical pipeline for Kafka starts with ingestion from databases, message buses, APIs, and software adapters (which is where Divolte fits), pre-processing (normalization, filtering, transformation, and enrichment), analytics (including machine learning and pattern-matching) and then consumption by tools for reporting and process control, user apps and real-time analytics.
Data Store: Druid
Once events have been delivered to an Apache Kafka topic, message consumers consume the events. Apache Druid is a perfect partner for consuming real-time data from Kafka; it allows you to power the creation of dashboards and visualisations that use real-time data, a truly experiential data exploration experience for the kinds of ad-hoc analysis marketeers and product developers need. Using a visualisation tool on top of Druid, they can explore data in real-time, and come to conclusions about what’s going on now without involving engineers.
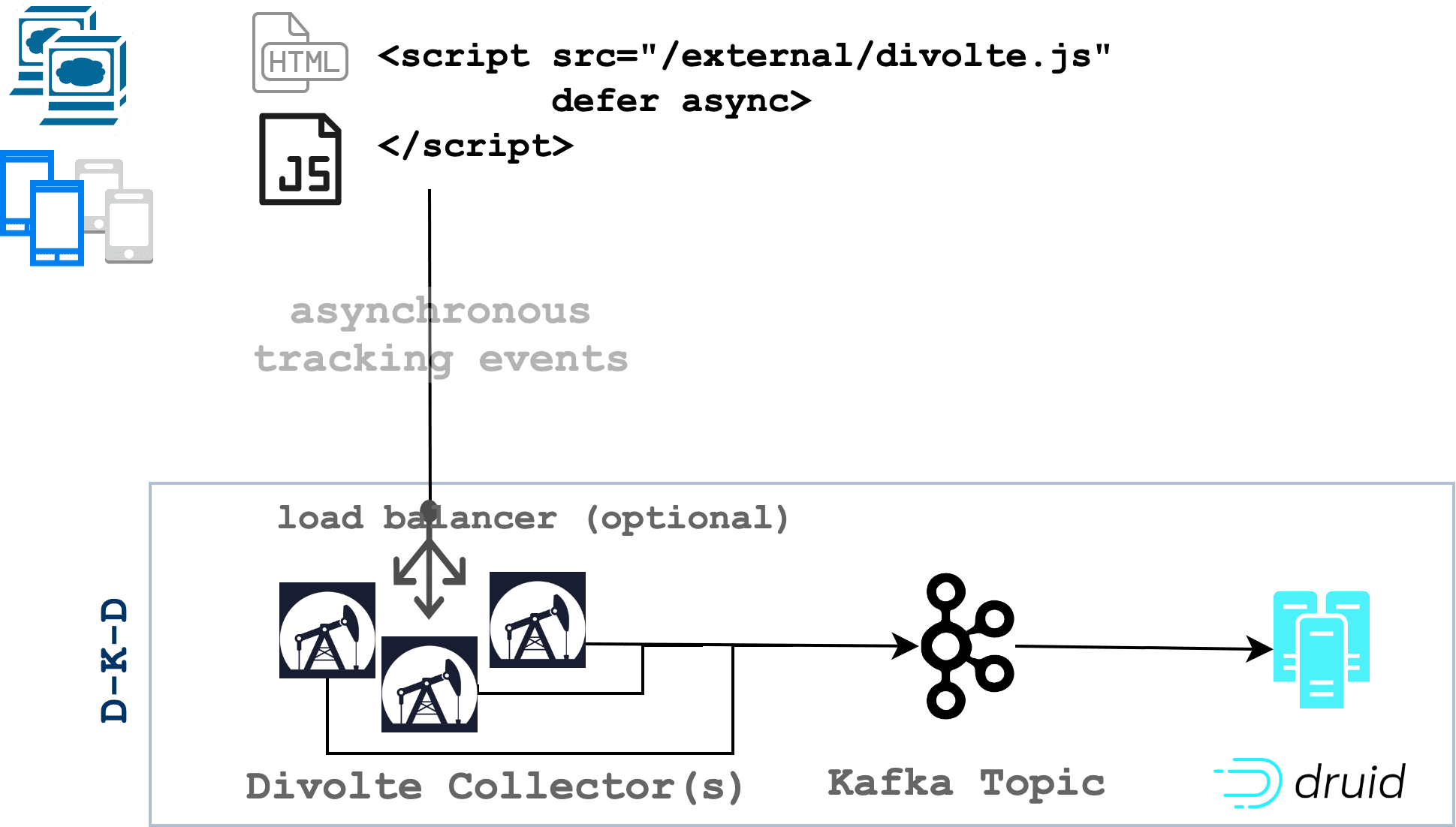
This is what we are aiming for: an application where Divolte javascript snippets have been embedded into the code of the site or app, and where Divolte Collectors have been deployed that send their data on to Apache Kafka. Then, to power the business exploration of the data, Apache Druid consumes and processes those events from Kafka in real-time ready for display in a data exploration app.
Let’s walk through setting up the DKD stack one step at a time.
Step 1: Divolte
Collector
First, download the latest distribution of the Divolte Collector and follow the installation instructions to start your first collector. Running the collector generates a divolte.js Javascript file that will be sourced by your application. Output from the running collector will point you to the path of the generated divolte.js script file that will be included just before the closing on every page of your application.
Once the divolte.js script is sourced and is loaded by a user, it will begin sending data to the Collector.
Tip: For large scale deployments, the collectors are ideally placed behind a load balancer for scaling and high availability. In a test scenario like this, you may choose to source the divolte.js file directly to a Divolte Collector.
Schema
When the Divolte Collector receives events from the client, it writes them to a pre-configured set of Sinks. Divolte uses Apache Avro to serialize events using a generic, pre-built schema. However, for most web applications you will want to create a custom schema. The steps for this are documented in Divolte’s Getting Started Guide. At a high level, both a schema and a mapping file (to map an incoming message to the schema) are required. Here is a sample schema and mapping file:
The default behavior of the Divolte Collector is to write its Avro data files to the local disk (by default, /tmp/). But, this can be easily changed to instead (or in addition) write the events to a Kafka topic. In order to enable this, add the following to your Divolte configuration and restart your Divolte Collector(s):
Modify the configuration to match your environment. In particular, update the topic and bootstrap.servers fields.
Step 3: Druid
With the clickstream events arriving from the client and delivered to a Kafka topic, we’re now ready to provide access to end users through Apache Druid.
In a production environment, you will install Apache Druid in a cluster, but, for now we’ll set it up on a single machine. In step four, we’ll use Imply Pivot, a purpose-built user interface for slicing and dicing data at scale, for visualizing and ad-hoc analysis. So, download the Imply distribution of Apache Druid, which includes Imply Pivot, that you can use free for 30 days. Then follow the first three steps of the Quickstart (up to and including “Start up services”) to get Apache Druid running.
Once Druid is running, we’ll create an ingestion spec describing the Kafka topic and schema of the Avro data, informing Druid how to retrieve the incoming clickstream events from Kafka and load it into Druid. Here’s a simple ingestion spec for the default data you will receive from Divolte via Kafka:
Once the ingestion spec is ready, submit it to the Druid overlord and it will begin consuming events from your Kafka topic as they arrive. You can view progress and check for errors in the Data view of the Pivot UI (port 9095 of your installation).
Step 4: Visualize and Analyze
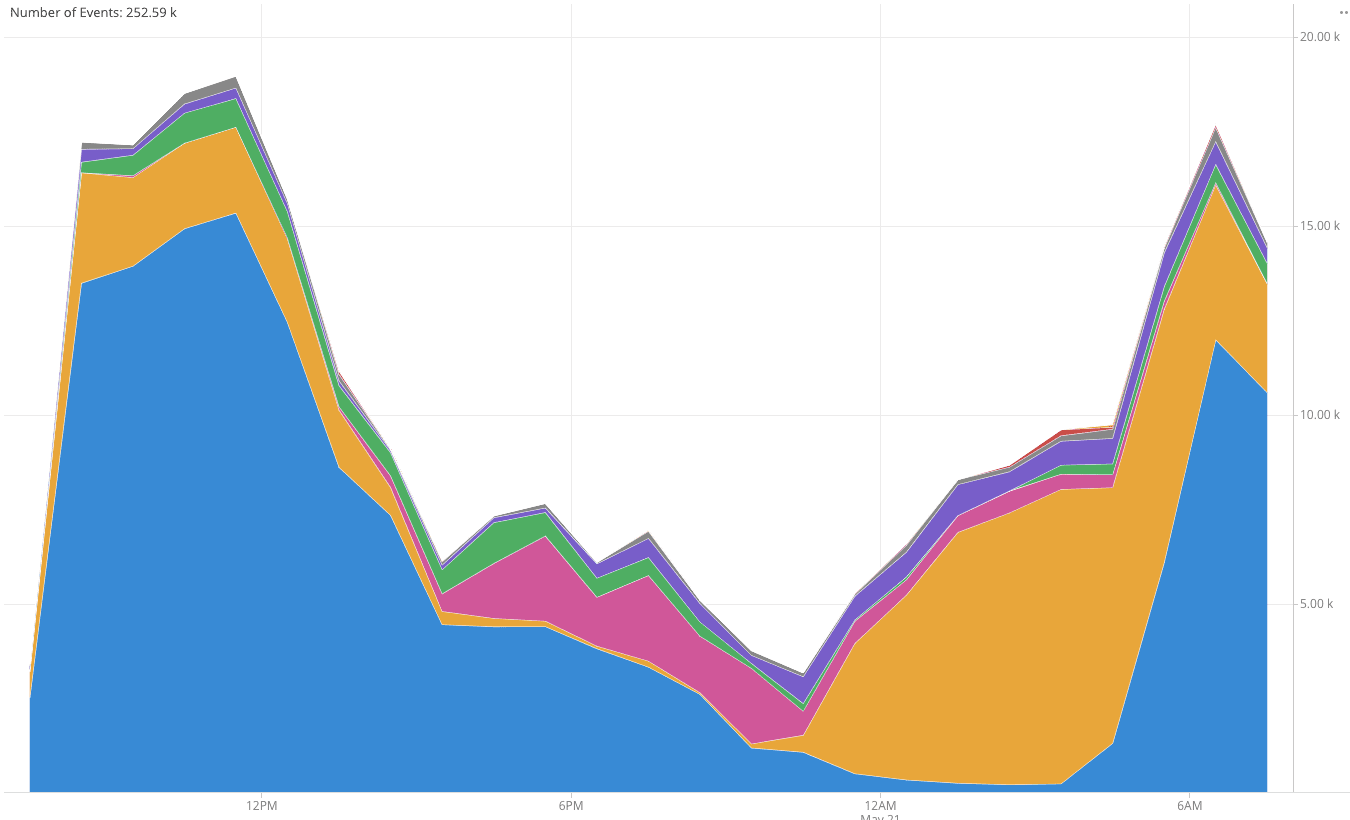
With all components of this stack operating, events from users are ready to be analyzed within seconds by business analysts, engineers, marketing, and all teams in your organization.
Imply provides a purpose-built tool for this exploration called Pivot. If you have loaded your data into the Imply distribution, then create a data cube and begin exploring!
Some examples of questions that can be answered using the default data from Divolte are:
Is our campaign working, right now?
Are we getting more visitors today than we did this time last week?
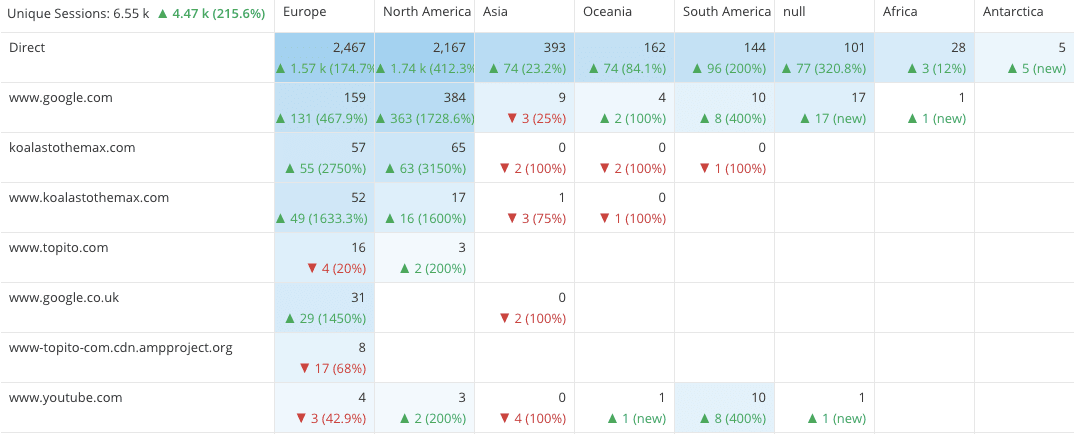
Is now a good time to publish content changes targeted at a particular geography?
Should we target adverts to a different referring website today?
Have yesterday’s SSO changes made that impact we’ve been looking for?
How has the release of a new browser this week affected our customer profile? Do we need to adapt our website code?
Recap: Druid Summit 2024 – A Vibrant Community Shaping the Future of Data Analytics
In today’s fast-paced world, organizations rely on real-time analytics to make critical decisions. With millions of events streaming in per second, having an intuitive, high-speed data exploration tool to...
Pivot by Imply: A High-Speed Data Exploration UI for Druid
In today’s fast-paced world, organizations rely on real-time analytics to make critical decisions. With millions of events streaming in per second, having an intuitive, high-speed data exploration tool to...