3 essentials in Apache Druid that make your analytics app ready for real-time
Data teams creating analytic applications are faced with increasing demand from event data and streaming sources like Apache Kafka. This is a very different data source than we’ve handled in the analytics industry. My colleague Darin Briskman reports on this trend and what it means in other articles.
The question, then, isn’t if you will need to include stream data into your analytics apps, but whether your database is ready for it. And therein lies the issue. Every database says they handle streams. What they mean by that is that they can connect to streaming sources like Kafka. But after that, then what? They process it like they do everything else: in batches, persisting data to files before they can be queried. We think you’ll need more than this basic capability if you want real-time insights. That is to say, insights faster than batch loading can deliver.
Apache Druid is a database built for true stream ingestion. In fact, it handles stream data natively, not requiring a connector for sources like Kafka and AWS Kinesis. In addition to native connectivity, Druid provides 3 other essentials for stream analytics.
Query on Arrival
With other databases, events are ingested in batches, then persisted to files where you can then act on them. This is true not just for all cloud data warehouses (like Snowflake and Redshift) but even for some high performance databases like ClickHouse.
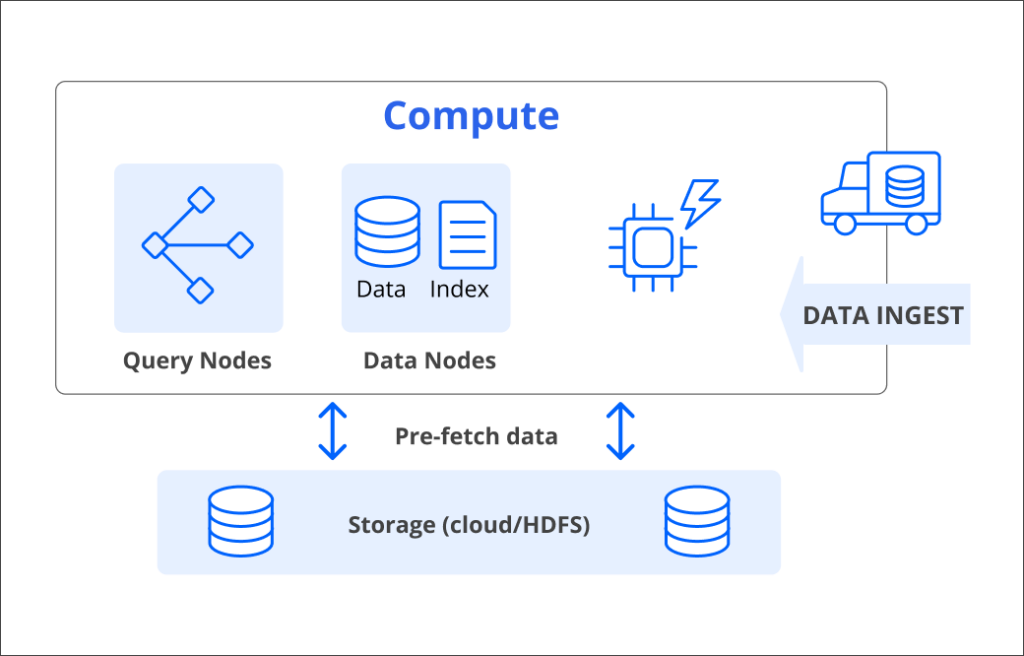
Druid does it differently. With Druid, stream data is ingested event-by-event (not batch) into memory at the data nodes. While it is in memory it can be queried. We call this “Query on Arrival” and it makes all the difference in applications that need real time, such as ad-tech and fraud detection.
Fig 1. Druid workflow showing event data ingested to memory, then data nodes, then persisted to deep storage.
Events are not held in memory forever. They are processed by Druid: columnarized, compacted, and segmented. These segments are then persisted into a deep storage layer, which acts as a continuous backup. So not only do you get query on arrival, you get the same flexibility and non-stop reliability you expect from a cloud data warehouse.
Guaranteed Consistency
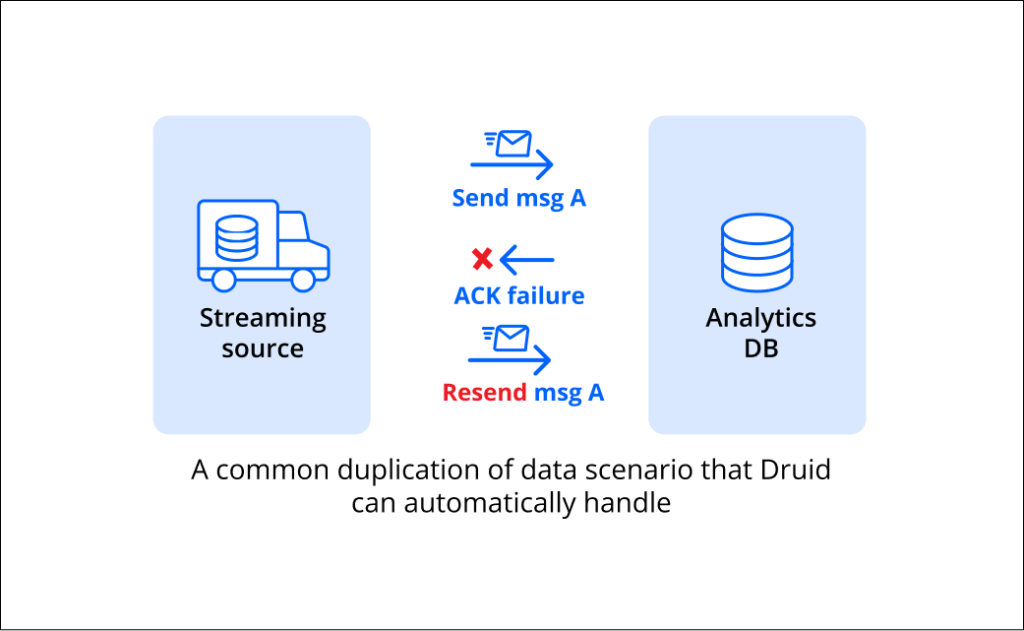
In a rapidly-moving streaming environment, data inconsistencies are a killer problem. A system could possibly survive a duplicate record here or there, but when compounded across millions or even billions of events per day, it becomes a different matter.
This is why the gold standard in consistency is exactly-once semantics. That is to say, the system will only ingest an event exactly once. No duplicates, no data loss. Sounds simple, but in reality this is difficult to attain when a system is still operating in batch mode. It requires developers to write complex code to track events, or install another product that will do this for them, increasing cost and complexity.
Fig 2. A common duplication of data scenario in a streaming environment that Druid automatically manages.
Druid does it differently. Since Druid is a true event-by-event ingestion engine, it automatically guarantees exactly once consistency. This takes a huge burden off developers so they can focus their efforts on more important features. How can Druid do this? By taking advantage, using our native connectivity, of how the Kafka indexing service assigns a partition and offset to each event, making it possible to know exactly if the messages received were delivered as expected (get the details here).
Massive Scalability
It used to be that for an event to be generated, a human had to interact with a system, such as a web site. Each click became an event. Now, data is being generated without any human initiation, such as a phone tracking its location, or your smartwatch sending heart rate data to the cloud for a health app. The result: an explosion of events.
For your database to keep up, it needs to scale easily. It is not unusual to see streams hit millions of events per second. Not only does a database need to be ready to query billions of events, it needs to ingest them rapidly, too. The traditional database approach of scaling up is not an option. Scaling out is the only way to go, and even cloud data warehouses like Snowflake seem to recognize this.
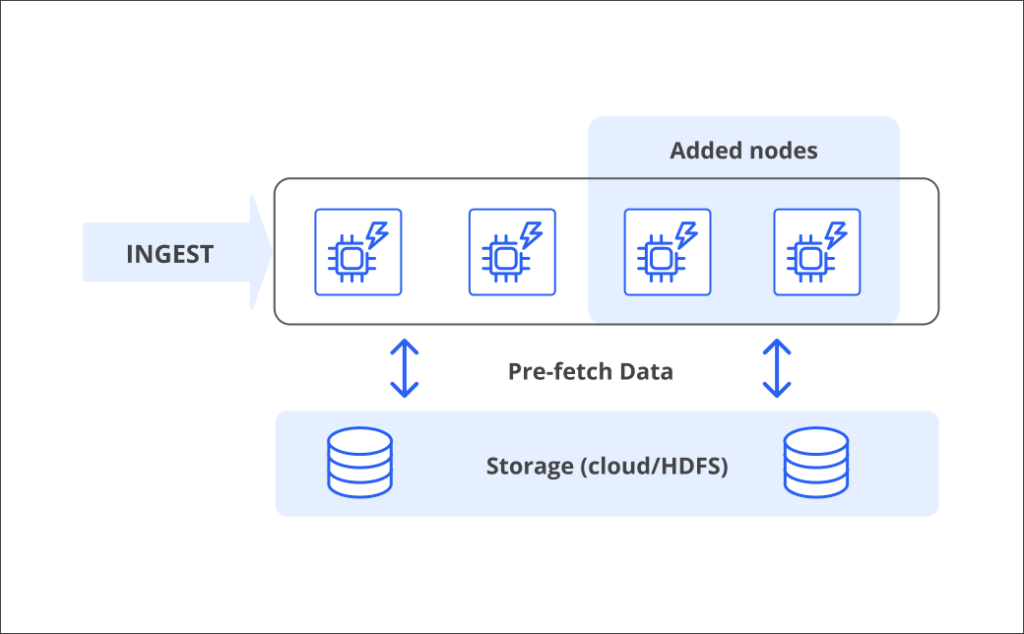
A great way to handle the volume of ingest and query is with an architecture of independently scalable components. Many high performance databases start with a shared-nothing, scale-out architecture. Rapidly-growing databases will require adding components, such as data nodes, frequently. For many of these same databases, adding a node requires downtime to manually rebalance the cluster. This is not conducive to real-time analytics.
Fig 3. Druid’s unique architecture gives you a shared-nothing compute layer that can scale out to thousands of nodes without downtime.
Druid does it differently. Druid’s unique architecture combines the query and ingest performance of shared nothing architecture with the flexibility and non-stop reliability of a cloud data warehouse. This means you can add nodes and scale out without downtime or rebalancing, which is handled automatically. The same architecture also automatically recovers from faults and allows rolling upgrades. This gives you the confidence to handle any amount of stream data, even billions of rows per day.
Learn More
Having a connection to Kafka or other streaming sources is of course just the beginning. We encourage you to consider a database that is built for stream ingest. I invite you to continue learning about Apache Druid:
Try it for free and be setup in minutes with Imply Polaris, our DBaaS built with Apache Druid
Other blogs you might find interesting
No records found...
Nov 12, 2025
The Breaking Point for Observability Leaders
Observability is at a crossroads For years, observability has promised to give teams the visibility they need to keep digital services resilient. But as data volumes explode, many leaders are realizing the...
Logs are exploding. Costs are climbing. Performance is stalling. If you manage logs, you’re in the hot seat Every app, every integration, every security risk—it all generates more data. And when something...
The next evolution in observability: How architecture is following in BI’s footsteps
Modern observability systems are hitting the same wall business intelligence did a decade ago. As data volumes explode, the traditional model — where a single product handles ingestion, storage, compute,...