What is a Modern Analytics Application?
Every organization needs insight to succeed and excel. While insights can come from many wellsprings, the foundation for insights is data: both internal data from operational systems, and external data from partners, vendors, and public sources.
For decades, the approach to gaining insights from data has focused on data warehousing and business intelligence. It’s the traditional approach of BI experts querying historical data “once in a while” for executive dashboards and reports.
Leading organizations like Netflix, Target, Salesforce, and Wikimedia Foundation have found that traditional analytics still has value, but it’s not enough. They are some of the thousands of teams building real-time analytics applications that deliver insights continually, on demand, and at scale.

- Real-time analytics applications enable interactive conversations with data, allowing humans and, sometimes, machines, to quickly and easily see and comprehend complex information, drilling down to deep detail and panning outwards to global views, all with subsecond response times. Many real-time analytics applications support interactive conversations with large data sets, maintaining subsecond performance even with Petabytes of data.
- Real-time analytics applications support high concurrency, with large numbers of users,thousands or more, each generating multiple queries as they interact with the data. Data warehouses that support a few dozen concurrent queries are no longer sufficient – thousands of concurrent queries must be able to be executed. Of course, this must be done affordably, not by piling on large amounts of expensive infrastructure.
- Real-time analytics applications combine both real-time and historical data. Real-time data is usually delivered in streams, using tools like Apache Kafka®, Confluent Cloud, or Amazon Kinesis. Data from past streams and from other sources,such as transactional systems, is delivered as a batch, through extract-load-transformation processes. The combination of both data types allows both real-time understanding and meaningful comparisons to the past. Many real-time analytics applications ingest millions of events per second from one or more streams.
What is Druid?
![]() Apache® Druid is a leading database for real-time analytics applications. It enables interactive conversations with data, provides high concurrency at the best value, and easily ingests and combines both real-time streaming data and historical batch data. It is an open-source, high-performance, real-time analytics database that is flexible, efficient, and resilient.
Apache® Druid is a leading database for real-time analytics applications. It enables interactive conversations with data, provides high concurrency at the best value, and easily ingests and combines both real-time streaming data and historical batch data. It is an open-source, high-performance, real-time analytics database that is flexible, efficient, and resilient.
Origins of Druid
In 2011, the data team at a technology company had a problem. They needed to quickly aggregate and query real-time data coming from website users across the Internet to analyze digital advertising auctions. This created large data sets, with millions or billions of rows.
They first implemented their product using relational databases, starting with Greenplum, a fork of PostgreSQL. It worked, but needed many more machines to scale, and that was too expensive.
They then used the NoSQL database HBase populated from Hadoop Mapreduce jobs. These jobs took hours to build the aggregations necessary for the product. At one point, adding only 3 dimensions on a data set that numbered in the low millions took the processing time from 9 hours to 24 hours..
So, in the words of Eric Tschetter, one of Druid’s creators, “we did something crazy: we rolled our own database!” And it worked! The first incarnation of Druid scanned, filtered, and aggregated 1 billion rows in 950 milliseconds.
Druid became open source a few years later, and became a project of the Apache Software Foundation in 2016.
As of April 2022, over 1,000 organizations use Druid to generate insights that make data useful, in a wide variety of industries and a wide range of uses. There are over 10,000 developers active in the Druid global community.
Scalable & Flexible
![]() Druid has an elastic and distributed architecture to build any application at any scale, enabled by a unique storage-compute design with independent services.
Druid has an elastic and distributed architecture to build any application at any scale, enabled by a unique storage-compute design with independent services.
During ingestion, data are split into segments, fully indexed, and optionally pre-aggregated. This enables unique value over other analytics databases which force a choice between the performance of tightly-coupled compute and storage or the scalability of loosely-coupled compute and storage. Druid gets both performance and cost advantages by storing the segments on cloud storage and also pre-fetching them so they are ready when requested by the query engine.
Each service in Druid can scale independently of other services. Data nodes, which contain pre-fetched, indexed, segmented data, can be dynamically added or removed as data quantities change, while Query nodes, which manage queries against streams and historical data, can be dynamically added or removed as the number and shape of queries changes.
A small Druid cluster can run on a single computer, while large clusters span thousands of servers, and are able to ingest multiple millions of stream events per second while querying billions of rows, usually in under one second.
Efficient & Integrated
![]() Performance is the key to interactivity. In Druid, “if it’s not needed don’t do it” is the key to performance. It means minimizing the work the cluster has to do.
Performance is the key to interactivity. In Druid, “if it’s not needed don’t do it” is the key to performance. It means minimizing the work the cluster has to do.
Druid doesn’t load data from disk to memory, or from memory to CPU, when it isn’t needed for a query. It doesn’t decode data when it can operate directly on encoded data. It doesn’t read the full dataset when it can read a smaller index. It doesn’t start up new processes for each query when it can use a long-running process. It doesn’t send data unnecessarily across process boundaries or from server to server.
Druid achieves this level of efficiency through its tightly integrated query engine and storage format, designed in tandem to minimize the amount of work done by each data server. Druid also has a distributed design that partitions tables into segments, balances those segments automatically between servers, quickly identifies which segments (or replicas of segments) are relevant to a query, and then pushes as much computation as possible down to individual data servers.
The result of this unique relationship between compute and storage is very high performance at any scale, even for datasets of multiple petabytes.
Resilient & Durable
![]() Druid is self-healing, self-balancing, and fault-tolerant. It is designed to run continuously without planned downtime for any reason, even for configuration changes and software updates. It is also durable, and will not lose data, even in the event of major systems failures.
Druid is self-healing, self-balancing, and fault-tolerant. It is designed to run continuously without planned downtime for any reason, even for configuration changes and software updates. It is also durable, and will not lose data, even in the event of major systems failures.
Whenever needed, you can add servers to scale out or remove servers to scale down. The Druid cluster rebalances itself automatically in the background without any downtime. When a Druid server fails, the system automatically understands the failure and continues to operate.
As part of ingestion, Druid safely stores a copy of the data segment in deep storage, creating an automated, continuous additional copy of the data in cloud storage or HDFS. It both makes the segment immediately available for queries and creates a replica of each data segment. You can always recover data from deep storage even in the unlikely case that all Druid servers fail. For a limited failure that affects only a few Druid servers, automatic rebalancing ensures that queries are still possible and data is still available during system recoveries. When using cloud storage, such as Amazon S3, durability is 99.999999999% or greater per year (or a loss of no more than 1 record per 100 billion).
Foundations of Design
Druid is deployed in a cluster of one or more servers that run multiple processes:
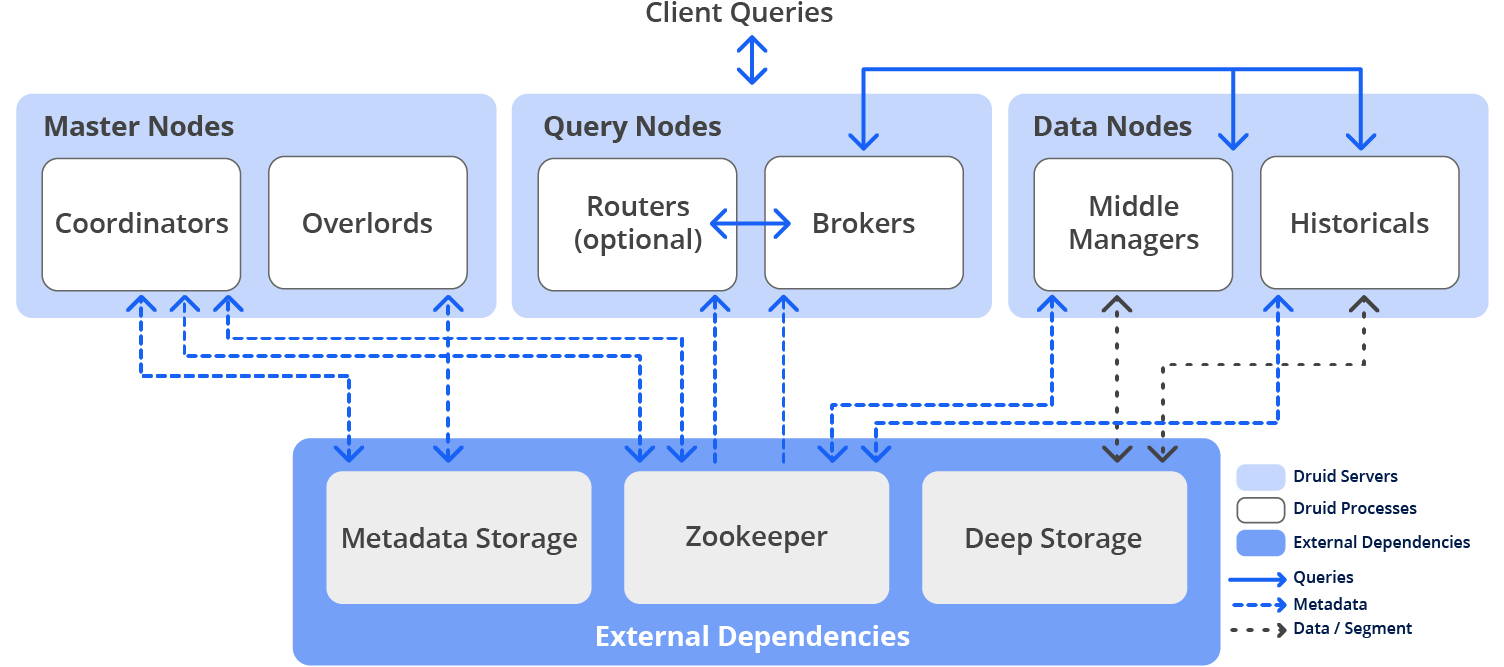
Usually, Druid processes are deployed on three types of server nodes:
- Master Nodes govern data availability and ingestion
- Query Nodes accept queries, execute them across the system, and return the results
- Data Nodes execute ingestion workloads and store queryable data.
In a small configuration, all of these nodes can run together on a single server. For larger deployments, one or more servers are dedicated to each node type.
In addition, Druid also has three external dependencies:
- Deep Storage contains an additional copy of each data segment using cloud storage or HDFS. It allows data to move between Druid processes in the background and also provides a highly durable source of data to recover from system failures.
- Metadata Storage is a small relational database, Apache Derby™, MySQL, or PostgreSQL, that holds data about managing the data. It is used by Druid processes to keep track of storage segments, active tasks, and other configuration information.
- Apache ZooKeeper™ is primarily used for service discovery and leader election. It was historically used for other purposes as well, but they have been migrated away.
Each of the node types are independently scalable: you can add or remove nodes without downtime when your storage, query, or coordination needs increase or decrease. Druid automatically rebalances, so added capacity is immediately available.
Druid has a distributed design that partitions tables into segments, balances those segments automatically between servers, quickly identifies which segments are relevant to a query, and then pushes as much computation as possible down to individual data nodes.
Druid also takes advantage of approximation. While Druid can perform exact computations when desired, it is usually much faster to use approximations for ranking, calculation of histograms, set operations, and count-distinct.
Performance
These features of Druid combine to enable high performance at high concurrency by avoiding unneeded work. Pre-aggregated, sorted data avoids moving data across process boundaries or across servers and avoids processing data that isn’t needed for a query. Long-running processes avoid the need to start new processes for each query. Using indexes avoids costly reading of the full dataset for each query. Acting directly on encoded, compressed data avoids the need to uncompress and decode. Using only the minimum data needed to answer each query avoids moving data from disk to memory and from memory to CPU.
In a paper published at the 22nd International Conference on Business Information Systems (May, 2019), José Correia, Carlos Costa, and Maribel Yasmina benchmarked performance of Apache Hive™, Presto, and Druid using a TPC-H-derived test of 13 queries run against a denormalized star schema on a cluster of 5 servers, each with an Intel i5 quad-core processor and 32GB memory. Druid performance was measured as greater than 98% faster than Hive and greater than 90% faster than Presto in each of 6 test runs, using different configurations and data sizes. For Scale Factor 100 (a 100GB database), for example, Druid required 3.72s, compared with 90s for Presto and 424s for Hive.
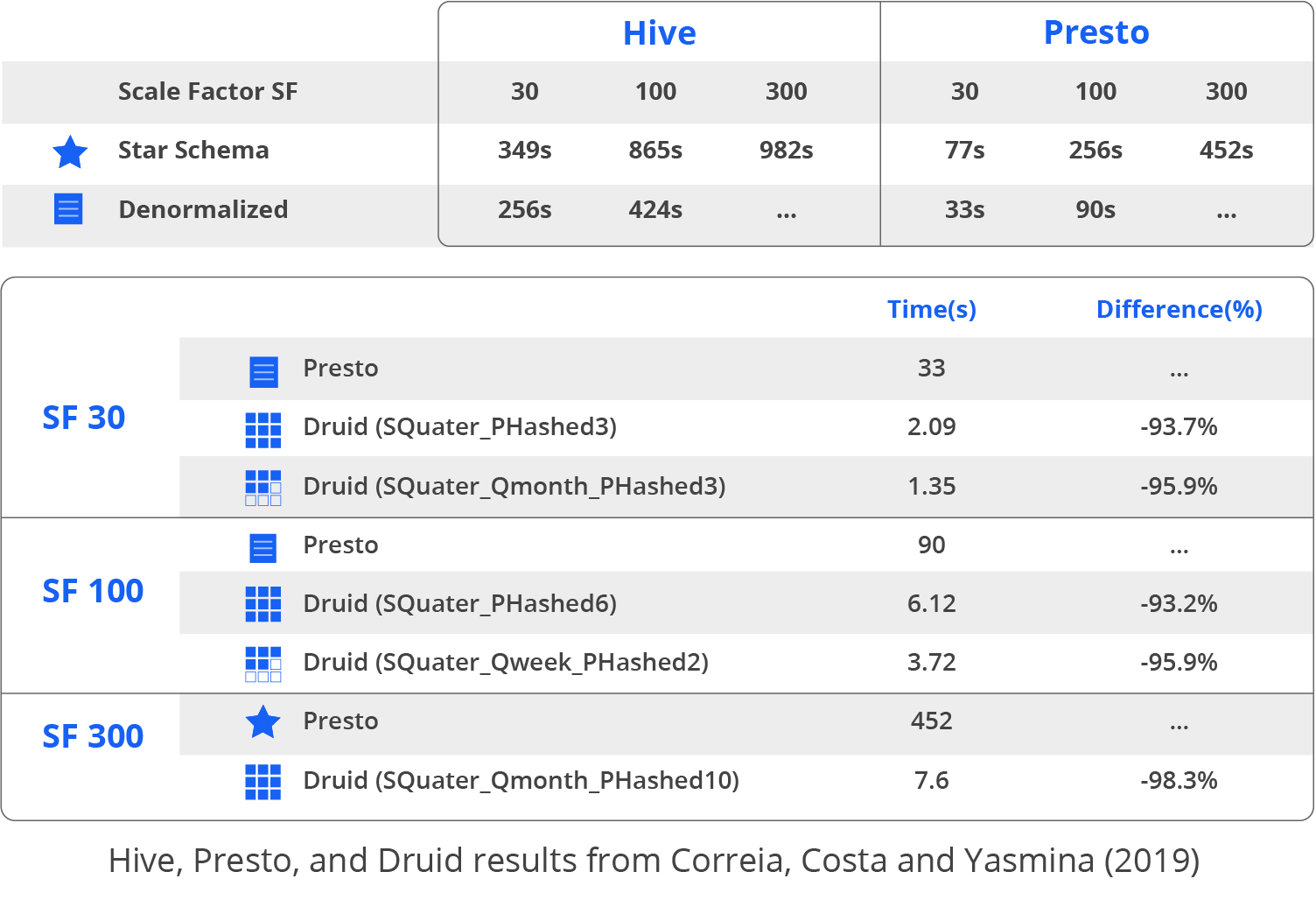
In November, 2021, Imply Data published the results of a benchmark using the same star schema benchmark, with Druid on a single AWS c5.9xlarge instance (36 CPU and 72GB memory) at Scale Factor 100 (a 100GB database). The 13 queries executed in a total of 0.747s.
Storage
Much of Druid’s ability to provide high performance and high concurrency while also being cost-efficient and resilient is enabled by a unique relationship between storage and compute, blending the “separate” and “local” approaches used by other databases.
Local storage uses high-speed disk, or other persistent storage technologies, like solid-state drives, to keep all data quickly available for queries. This is the design used by most transactional databases, such as Oracle, SQL Server, Db2, MySQL, and PostgreSQL. It provides good query performance, but it can be expensive, and very expensive for the large datasets common in analytics. Fortunately, Druid can provide the advantages of local storage without high expenses.
Many data warehouses use separate storage, where all ingested data resides on a remote storage system. On the cloud, that’s an object storage service, such as Amazon S3 or Azure Blob. On-premise, that’s a distributed storage system like HDFS. Databases with separate storage query data directly from that remote storage, potentially with some caching. This allows compute capacity to be bursted up and down quickly, which is great for infrequently-accessed data or irregular query load.
But there is a downside to the separate storage approach: these systems don’t perform as well as systems that store data locally on data servers. This doesn’t work well for high-performance application-oriented use cases: the system performs well when the cache is warmed up, but performance on cold cache is poor.
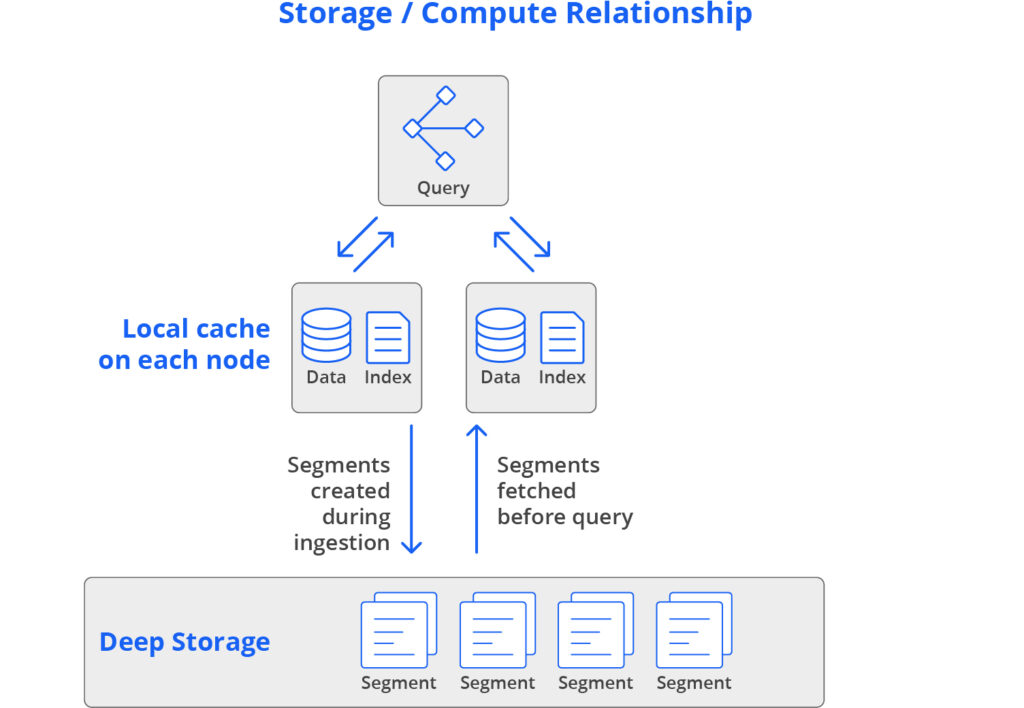
Druid blends the “separate” and “local” approaches. It uses separate storage, labeled “deep storage”, as a common data store. This makes it easy to scale Druid up and down: simply launch or terminate servers, and Druid rebalances which segments are assigned to which servers. Meanwhile, Druid also preloads all data into local caches before queries hit the cluster, which guarantees high performance; there is never a need to load data over the network during a query.
In the vast majority of cases, data will already be cached in memory. And even if it isn’t, it will be available on the local disk of at least two data servers. This unique design gives Druid the elasticity, resilience, and cost profile of separate storage, with the high performance profile of local storage.
Segments and Data Storage
Data in Druid is stored in segments. Each segment is a single file, typically comprising up to a few million rows of data. Each Druid table can have anywhere from one segment to millions of segments.
Within the segments, data storage is column-oriented. Queries only load the exact columns needed for each request. This greatly improves speed for queries that retrieve only a few columns. Each column’s storage is optimized by data type, which further improves the performance of scans and aggregations. String columns are stored using compressed dictionary encoding, while numeric columns are stored using compressed raw values.
Each segment is created as mutable. Data is immediately queryable. Meanwhile, a background process works to accelerate future queries by indexing and compacting the data. As data in a segment is mutable, it can be converted to columnar format, indexed, dictionary encoded (for columns with text data), and type-aware compressed. Once the segment has been prepared, it is committed: a copy is published to deep storage to ensure data durability, while an entry about the segment is written to the metadata store.
Usually, one segment is created for each time interval, with the size of the interval calculated to match the characteristics of the data set – about 5 million rows, with each segment typically between 300MB and 700MB in size. Sometimes, there will be multiple segments for a single time interval, which are automatically grouped together as a block.
If changes are needed in committed segments, such as a schema change or data updates, the segment is replaced. Druid does this with atomic control, so all segments in a time interval block are replaced before queries use the new data.
Segments in the same table may have different schemas, and Druid will take the right actions to allow queries to be accurate. If a column exists in some segments but not others, queries will treat the missing column as a null value and ignore it for aggregations.
Data Modeling
In most databases, much time and effort must be invested in modeling the data, creating normalizations, star- and snowflake-schemas, and other designs for organizing data storage.
This isn’t needed in Druid. Each table is wide and denormalized. Each field value is determined at ingestion and stays that way.
In some cases, attribute values change over time: for example, in a table tracking consumer addresses, people sometimes move to new addresses. Druid manages these changing dimensions with lookups, a key-value map to connect the value of a dimension, such as “address”, with a time interval.
Queries and Query Engines
You use a query to retrieve information from a database. Druid queries are fast, support high concurrency, and can run across data sets of any size.
Druid supports two query languages: Druid SQL and Druid native queries. Native queries are JSON objects that execute low-level, lightweight functions for aggregation, scan, search, and metadata functions.
Most Druid queries use SQL. Druid enables SELECT statements with all of the most common SQL functions, including filters (WHERE), rollups (GROUP BY, ORDER BY), combinations (JOIN, UNION ALL), pagination (LIMIT, OFFSET), aggregations (COUNT, SUM, MIN, MAX, AVG), approximations (APPROX_COUNT_DISTINCT, APPROX_QUINTILE), and mathematics (BLOOM_FILTER, VARIANCE, STDDEV). Common numeric scalar, string, and time functions are also included.
Druid also provides some advanced mathematical techniques for rapid insights into large data sets, including HyperLogLog sketches, Theta sketches, and Quantiles sketches.
There is no need for SQL DDL (data definition language) in Druid, such as CREATE TABLE or DROP INDEX. Druid tables are created as part of the ingestion process, while data is deleted by marking segments as unused.
Druid SQL queries are translated into Druid native queries. Other than a very small translation cost (<1ms), both query languages provide the same very fast performance.
Query Engine
Druid queries are managed by the broker process, which usually runs on a query node. Most queries use the core query engine, which uses a scatter / gather approach to distribute queries for fast performance.
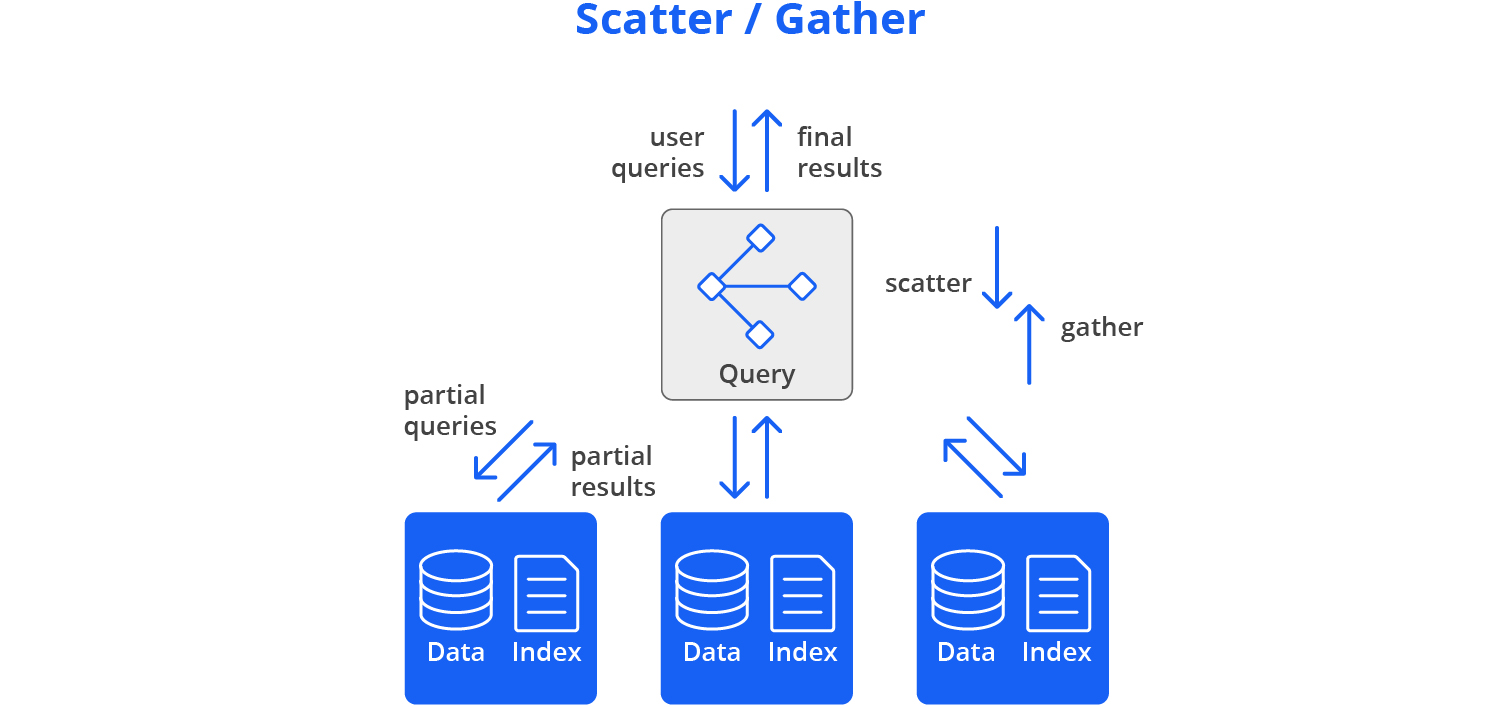
First, the query engine prunes the list of segments, creating a list of which segments are relevant to the query based on time-intervals and other filters. Next, queries are divided into discrete pieces and sent in parallel to the data nodes that are managing each relevant segment or a replica of that segment (“scatter”). On the data nodes, the query is processed and sent back to the broker for assembly (“gather”).
This scatter / gather approach works from the smallest single server cluster (all of Druid on one server) to clusters with thousands of servers, enabling sub-second performance for most queries even with very large data sets of multiple Petabytes.
Concurrency
High concurrency was one of the original design goals for Druid, and many Druid clusters are supporting hundreds of thousands of queries per second.
The key to Druid concurrency is the unique relationship between storage and compute resources. Data is stored in segments, which are scanned in parallel by scatter / gather queries. Usually, scanning each segment requires about 250ms, and rarely more than 500ms.
In Druid, there is no need to lock segments, so when multiple queries are trying to scan the same segment, the resources are released to a new query immediately upon scan completion. This keeps the computation time on each segment very small and enables a very high number of concurrent queries.
In addition, Druid automatically caches query results per-segment from historical data, while not caching, by default, data from fast-changing stream data. This further reduces query times and computation loads.
One of many examples of Druid concurrency was published by Nielsen Marketing, which compared response time as a function of concurrency in Druid with their previous Elasticsearch architecture.
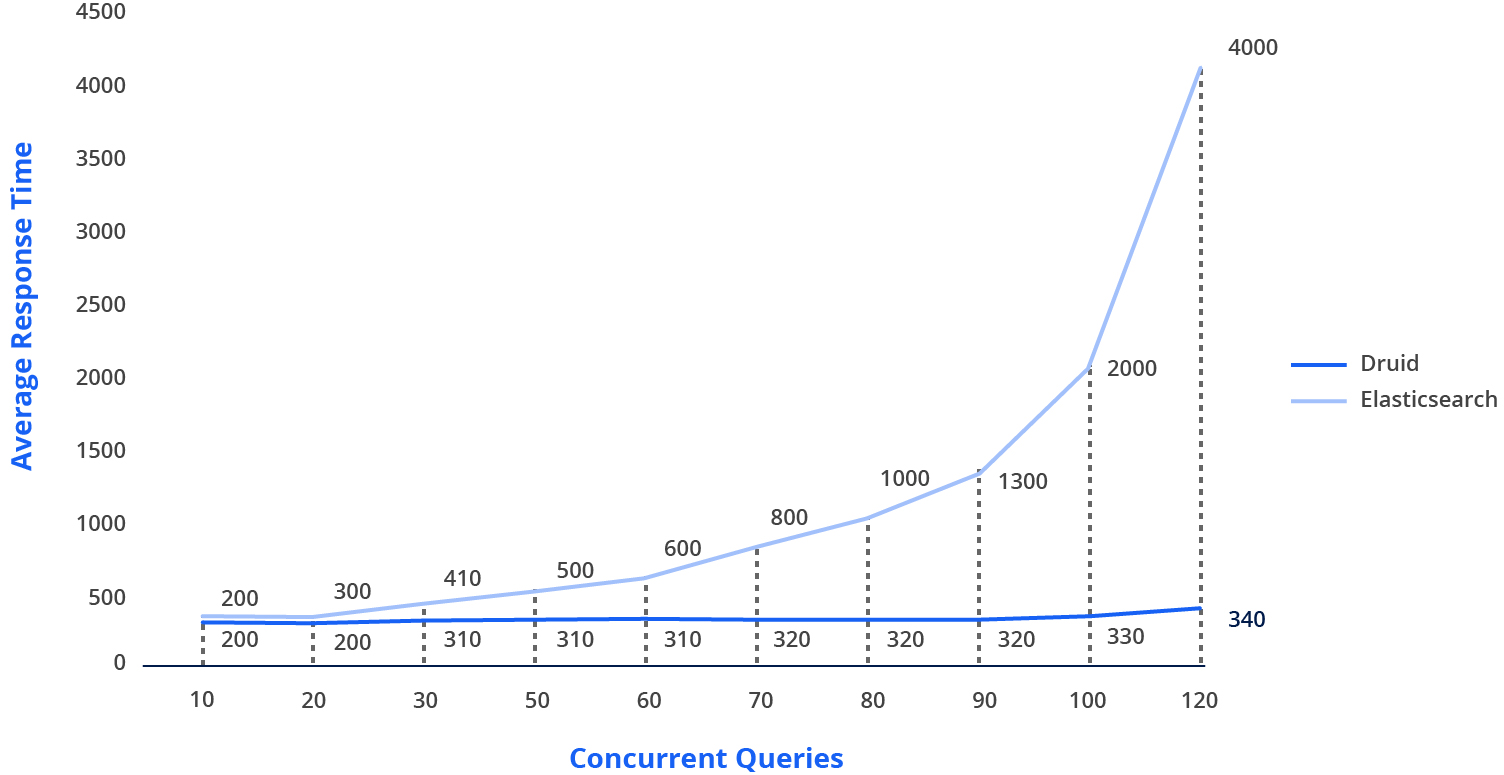
Note that with 10 concurrent queries, average response time was 280ms. Increasing this twelvefold to 120 concurrent queries in Druid only increased the average response time by 18%. The contrast with Elasticsearch is clear.
Ingestion
In Druid, ingestion, sometimes called indexing, is loading data into tables. Druid reads data from source systems, whether files or streams, and stores the data in segments.
Unlike some other databases, Druid doesn’t use SQL to create and manage tables. The ingestion process both creates tables and loads data into them. All tables are always fully indexed, so there is no need to explicitly create or manage indexes.
When data is ingested into Druid, it is automatically indexed, partitioned, and, optionally, partially pre-aggregated. Compressed bitmap indexes enable fast filtering and searching across multiple columns. Data is partitioned by time and, optionally, by other fields.

Stream Data
Druid was specifically created to enable real-time analytics of stream data, which begins with stream ingestion. Druid includes built-in indexing services for both Apache Kafka® and Amazon Kinesis, so additional stream connectors are not needed.
Like all data sources, stream data is immediately queryable by Druid as each event arrives.
Supervisor processes run on Druid management nodes to manage the ingestion processes, coordinating indexing processes on data nodes that read stream events and guarantee exactly-once ingestion. The indexing processes use Kafka®’s own partition and offset mechanisms and Kinesis’ own shard and sequence mechanisms.
If there is a failure during stream ingestion, for example, a server or network outage on a data or management node, Druid automatically recovers and continues to ingest every event exactly once, even events that arrive during the outage – no data is lost.
Batch Data
It’s often useful to combine real-time stream data with historical data from the past. This approach to loading data is known as batch ingestion. Many Druid implementations use entirely historical files – data from any source can take advantage of the interactive data conversations, easy scaling, high performance, high concurrency, and high reliability of Druid.
Druid usually ingests data from object stores, which include HDFS, Amazon S3, Azure Blob, and Google Cloud Storage or from local storage. The data files can be in a number of common formats, including JSON, CSV, TSV, Parquet, ORC, Avro, or Protobuf. Druid can ingest directly from both standard and compressed files, using formats including gz, bz2, xz, zip, sz, and zst.
In addition, Druid can ingest batch data directly from HTTP servers or directly from databases such as MySQL and PostgreSQL.
Rollup
A useful option to reduce data storage size and improve performance is to use data rollup, a pre-aggregation to combine rows that have identical dimensions within an interval that you choose, such as “minute” or “day”, and adding metrics, such as “count” and “total”.
For example, a data stream of website activity that gets an average of 400 hits per minute could choose to store every event in its own table row, or could use a rollup to aggregate the sum of the total number of page hits each minute, reducing the needed data storage by 400x. If desired, the raw data can be kept in inexpensive deep storage for infrequent queries where individual events need to be queried.
Reliability and Durability
Druid provides for both very high uptime (reliability) and zero data loss (durability). It’s designed for continuous operations, with no need for planned downtime.
A Druid cluster is a collection of processes. The smallest cluster can run all processes on a single server (even a laptop). Larger clusters group processes by function, with each server (“node”) focused on running management, query, or data processes.
When a node becomes unavailable, from a server failure, a network outage, a human error, or any other cause, the workload continues to run on other nodes. For a data node outage, any segments that are uniquely stored on that node are automatically loaded onto other nodes from deep storage. The cluster continues to operate as long as any nodes are available.
Replicas
Whenever data is ingested into Druid, a segment is created and a replica of that segment is created on a different data node. These replicas are used both to improve query performance and to provide an extra copy of data for recovery.
If desired, for a higher level of performance and resiliency, additional replicas of each segment can be created.
Continuous Backup
As each data segment is committed, a copy of the data is written to deep storage, a durable object store. Common options for deep storage are cloud object storage or HDFS. This prevents data loss even if all replicas of a data segment are lost, such as the loss of an entire data center.
It is not necessary to perform traditional backups of a Druid cluster. Deep Storage provides an automatic continuous backup of all committed data.
Automated Recovery
If all nodes become unavailable (perhaps from a fire, flood, or seismic event damaging a data center or, once again, human error), all data continues to be preserved in both data replicas and durable deep storage. When using cloud object storage such as Amazon S3, Azure Blob, or Google GCS, multiple copies of data are stored in multiple physically-separated data centers in a region, so even destruction of a data center will not cause data loss. Once a Druid cluster is restored, operations can resume with no lost data.
Druid recovers from faults automatically and enables maintenance without downtime windows.
- If a node fails, no action is required by and administrator
- Data are automatically retrieved from cloud storage and distributed across remaining nodes
- Queries are automatically re-distributed across remaining nodes to maintain parallel performance
When a failed node comes back online, the data and queries are automatically re-balanced.
Because data are stored in the cloud as well, nothing is lost if the entire cluster fails or goes offline.
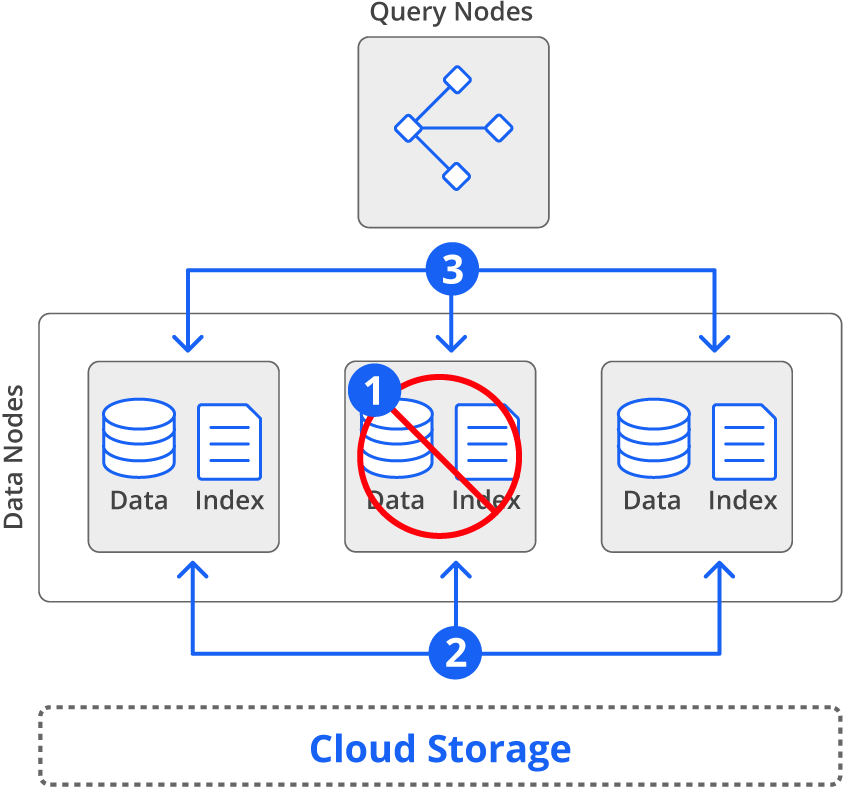
If high availability is required, it’s a good idea to ensure that Druid’s external components are also highly available. Apache ZooKeeper™ should run on a cluster of three or more nodes, while the metadata storage should use MySQL or PostgreSQL with replication and failover.
Rolling Upgrades
Upgrading Druid does not require downtime. Moving to a new version uses a “rolling” upgrade where one node at a time is taken offline, upgraded, and returned to the cluster. Druid is able to function normally during the rolling upgrade, even though some nodes will be using a different Druid version than other nodes during the upgrade.
Security
Druid includes a number of features to ensure that data is always kept secure.
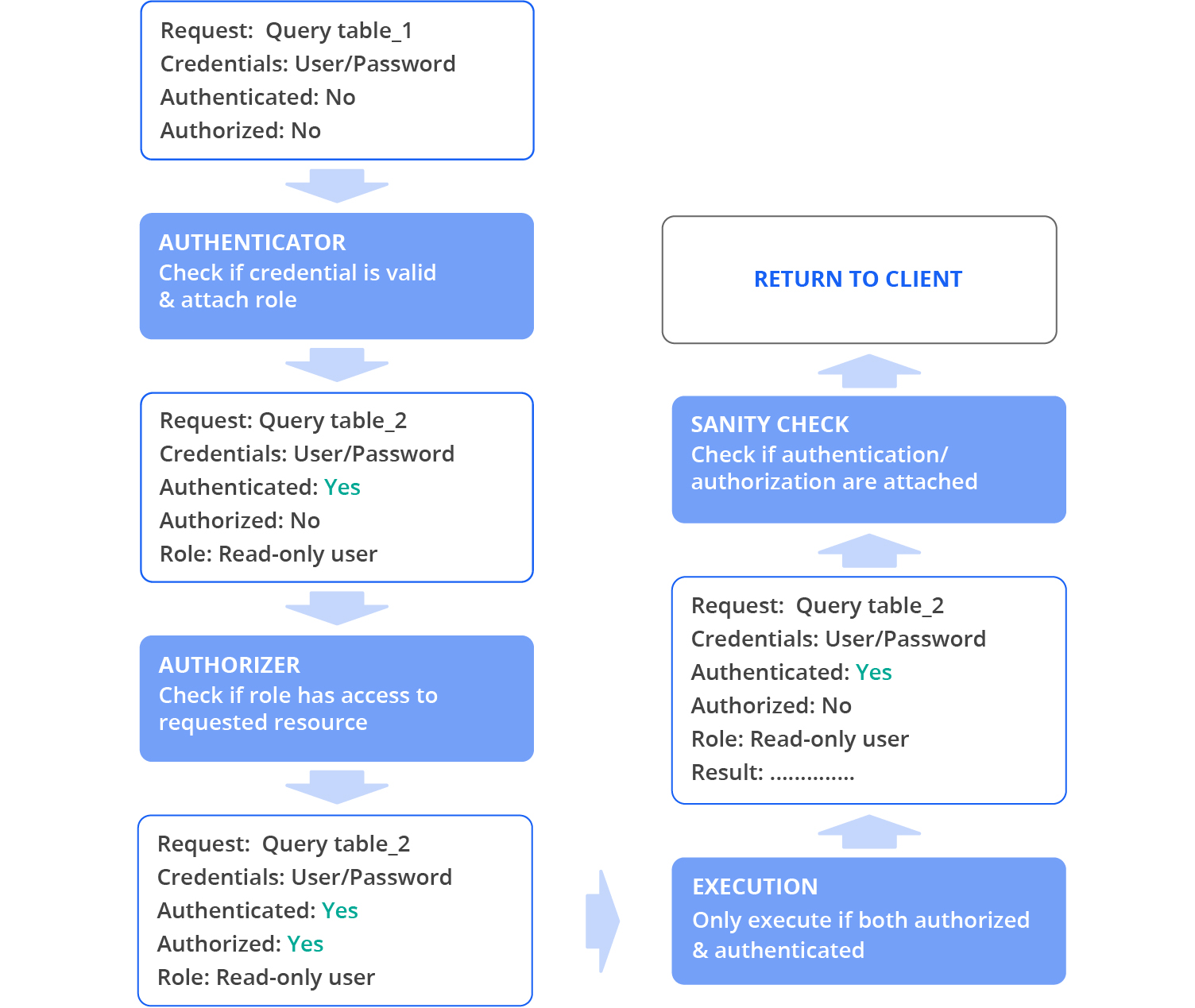
Druid administrators can define users with names and passwords managed by Druid or they can use external authorization systems through LDAP or Active Directory.
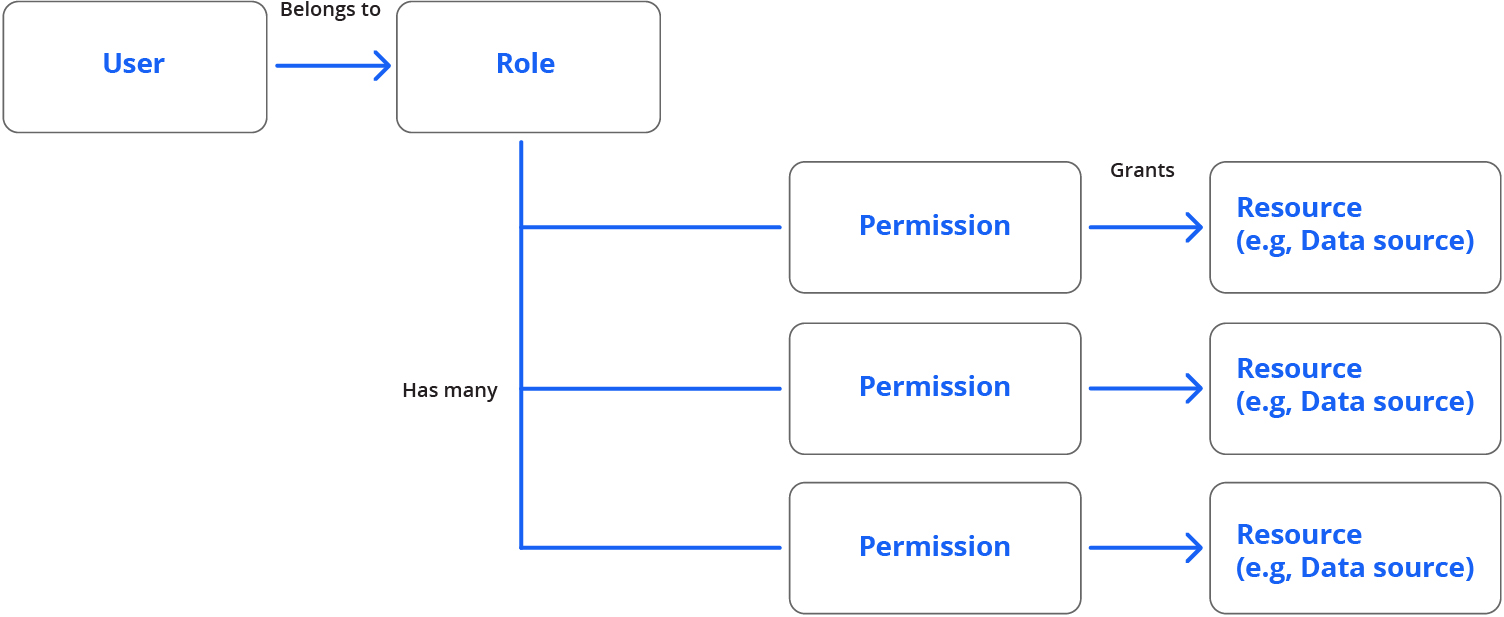
Fine-grained role-based access control allows each user to query only the datasources (such as tables) to which they have been granted access, whether using APIs or SQL queries.
Users belong to roles which are only able to use resources where the role has been granted permission.
All communications between Druid processes are encrypted using HTTPS and TLS. Best practices for production deployment of Druid require clients to use HTTPS to communicate with Druid servers, including the requirement for valid SSL certificates.
Developing with Druid
Druid supports a wide range of programming libraries for development, including Python, R, JavaScript, Clojure, Elixir, Ruby, PHP, Scala, Java, .NET, and Rust. In any of these languages, queries can be executed using either SQL commands (returning test results) or JSON-over-HTTP (returning JSON results).
Since Druid is both high-performance and high-concurrency, it’s a common pattern to use microservices architecture, with many services and many instances of each service able to send queries and receive results without worries about causing bottlenecks for other services.
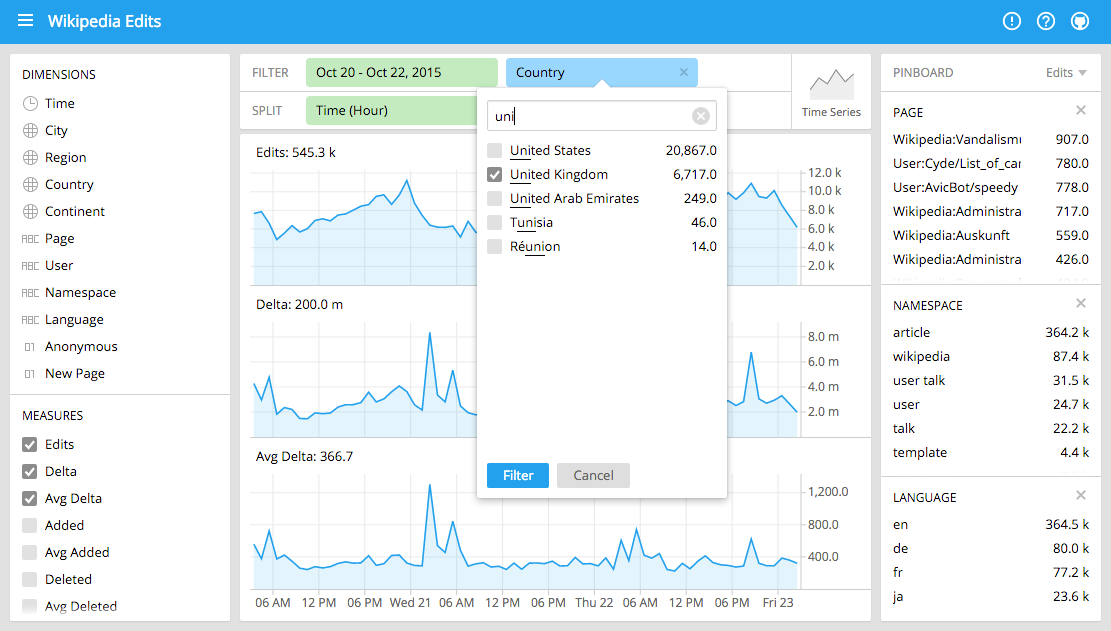
To visualize data in Druid, tools including Apache® Superset and Imply Pivot make it very easy to interactively explore the contents of each table, using various charts and graphics. Druid can also use a wide range of common visualization tools, including Domo, Tableau, Looker, Grafana, and others.
As a global open source project, Druid has a strong community, with mailing lists, forums, discussion channels and other resources.
Resources
- Druid: A Real-time Analytical Data Store, Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, Deep Ganguli; SIGMOD ’14: Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, June 2014
- Introducing Druid: Real-Time Analytics at a Billion Rows Per Second, Eric Tschetter, 2011
- Challenging SQL-on-Hadoop Performance with Apache Druid, José Correia, Carlos Costa, and Maribel Yasmina; 22nd International Conference on Business Information Systems, June 2019
- Druid Nails Cost Efficiency Challenge Against ClickHouse & Rockset, Eric Tschetter, November 2021
- Some of the applications Powered by Apache® Druid
- Apache® Druid homepage
- Apache® Druid community