CONSIDERATION 1:
Old, inflexible architecture
The architecture you are committing to will shape your growth plans and cost of ownership. Make sure it is flexible.
ClickHouse
ClickHouse is built on a “shared nothing” architecture where each node in a cluster has both compute and storage resources. While this decades-old concept results in good query performance, it cannot scale out without service interruptions to rebalance the cluster, sometimes long ones. Shared-nothing systems cannot effectively leverage cloud architectures, which separate storage and compute. This makes growth expensive and difficult.
Druid
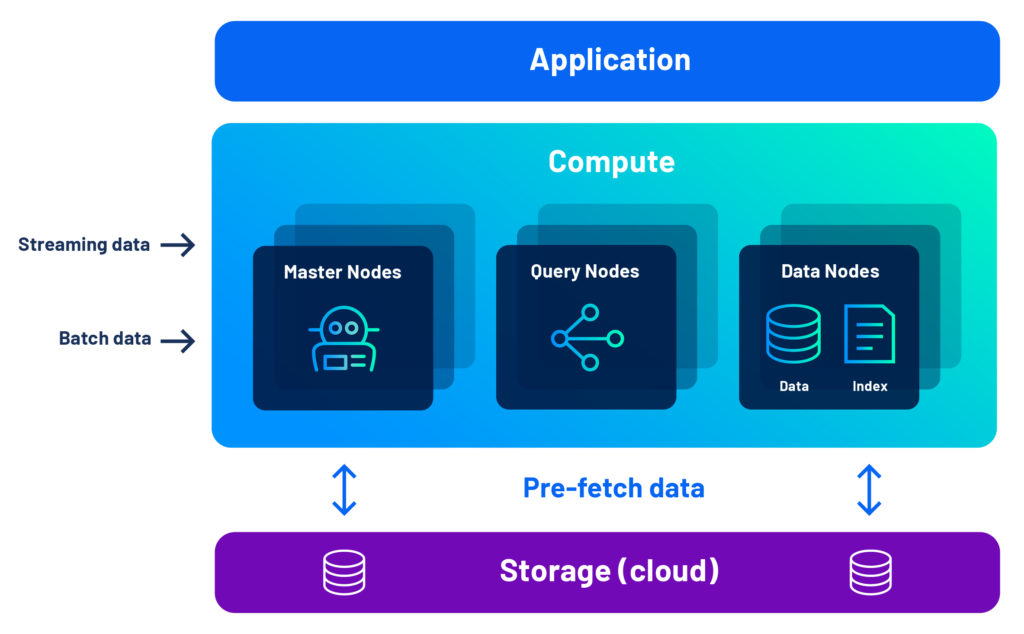
Druid features a unique architecture with the best of both worlds: shared-nothing query performance combined with the flexibility of separate storage and compute. This means you get query performance comparable to the best shared-nothing systems, and even better with streaming data. Plus, you can add or remove nodes to your cluster easily and Druid will automatically rebalance.
CONSIDERATION 2:
Painful scale-out
Anyone can claim “linear” scale-out growth. Making it happen is a different issue, especially if the database does not automatically rebalance.
ClickHouse
With ClickHouse, scaling-out is a difficult, manual effort. If you have a lot of data, it could take days to add a node:
- Add a node to the cluster.
- Rename the existing table then create a new table with the old name.
- Copy the data from the old table to a holding area.
- Re-attach the data to the new table on all nodes, making sure to set the “Shard Weight” properly to ensure load balancing.
How much downtime this will involve and the consequences of any mistake in the process is difficult to determine.
Druid
With Druid:
- Add a node to the cluster.
Druid automatically does the rest.
CONSIDERATION 3:
Does not support real-time data
Streaming data is essential to any modern analytics application. It shouldn’t require workarounds.
ClickHouse
ClickHouse does not support true streaming data ingestion despite having a Kafka connector. In fact, ClickHouse recommends batch insertions of 1,000 rows. Some customers have “rolled their own” block aggregators for Kafka to approximate an “exactly once” delivery, but still in batch mode. If you cannot create your own aggregator, the risk of duplicating data is high. While there is a SQL workaround for this as well, it is limited to single-threading which can severely degrade performance, making it behave more like a traditional RDBMS.
Druid
With native support for both Kafka and Kinesis, Druid ingests true event-by-event streams with exactly once semantics and is unique in that streaming data can be queried the moment it arrives at the cluster, even millions of events per second. There’s no need to wait as events make their way to storage. Thanks to Druid’s independent components and segmented data storage on data nodes, no workarounds are needed to ensure data integrity or performance. This effortless connection and performance is one reason why Confluent, the leading distributor of Kafka, uses Druid for their own analytics applications.
CONSIDERATION 4:
Not fully-protected against data loss
Applications that drive revenue or customer retention cannot afford even one instance of data loss.
ClickHouse
ClickHouse likes to tout that it has “no single point of failure.” This should be the minimum expectation of a system powering critical analytics applications. Most ClickHouse customers replicate nodes at least once to recover from failure (at increased cost, of course), but this is not a substitute for backup. What happens when multiple nodes fail? Or when the entire cluster goes down due to technical or human causes? ClickHouse backups are dependent on the customer’s usage of their manual backup utility, which could be completely arbitrary. Since ClickHouse does not track streams, you could lose streaming data during recovery.
Druid
Druid will not lose data, even if multiple nodes or the entire cluster fails. This is because Druid has something ClickHouse does not: deep storage due to separation of storage and compute. Data are automatically replicated in durable deep storage (Amazon S3, for example), and when a node fails, data are retrieved from deep storage and then Druid automatically rebalances the cluster. If the entire cluster fails, all data have been automatically replicated in real-time to deep storage, ensuring no data loss. Further, since Druid automatically tracks stream ingestion, autorecovery includes data in both table and stream, even for data arriving after the failure.
CONSIDERATION 5:
No automatic indexing
Handling high cardinality data requires optimized indexing. It should be automatic.
ClickHouse
ClickHouse requires that administrators select and implement each index. For high cardinality data, there are “data skipping indexes” that have a large array of attributes that need to be configured manually. For very large tables, the problem of “query amplification” can cause small queries to affect the performance of the entire cluster (a problem common to many shared-nothing systems). ClickHouse customers can deploy “bi-level sharding” for large tables to mitigate this issue, but this adds another layer of management complexity.
Druid
Druid automatically indexes data optimally for each column’s data type. Indexes are stored alongside the data in segments (instead of shards). Automatic indexing combined with this segmented data architecture and independent data nodes means you never need a workaround or manual effort for any queries.
CONSIDERATION 6:
No ability to prioritize work (tiering)
Another benefit of distributed systems is saving money on less important queries, but this requires a coordinator component.
ClickHouse
ClickHouse simply cannot do this. Its shared-nothing architecture does not have a coordinating (or master) component necessary to do tiering. In effect, a shared-nothing cluster can have only one tier, which makes all workloads equally expensive.
Druid
Druid’s architecture is based on independent, scalable components for coordination, query, data, and deep storage. As a result, older data can be placed on slower (but cheaper) nodes, thus saving money while prioritizing queries for newer data on better resources.
Druid’s Architecture Advantage
With Druid, you get the performance advantage of a shared-nothing cluster, combined with the flexibility of separate compute and storage, thanks to our unique combination of pre-fetch, data segments, and multi-level indexing.
Developers love Druid because it gives their analytics applications the interactivity, concurrency, and resilience they need.
Leading companies leveraging Apache Druid and Imply

“By using Apache Druid and Imply, we can ingest multiple events straight from Kafka and our data lake, ensuring advertisers have the information they need for successful campaigns in real-time.”

Cisco ThousandEyes
“To build our industry-leading solutions, we leverage the most advanced technologies, including Imply and Druid, which provides an interactive, highly scalable, and real-time analytics engine, helping us create differentiated offerings.”

GameAnalytics
“We wanted to build a customer-facing analytics application that combined the performance of pre-computed queries with the ability to issue arbitrary ad-hoc queries without restrictions. We selected Imply and Druid as the engine for our analytics application, as they are built from the ground up for interactive analytics at scale.”

Sift
“Imply and Druid offer a unique set of benefits to Sift as the analytics engine behind Watchtower, our automated monitoring tool. Imply provides us with real-time data ingestion, the ability to aggregate data by a variety of dimensions from thousands of servers, and the capacity to query across a moving time window with on-demand analysis and visualization.”

Strivr
“We chose Imply and Druid as our analytics database due to its scalable and cost-effective analytics capabilities, as well as its flexibility to analyze data across multiple dimensions. It is key to powering the analytics engine behind our interactive, customer-facing dashboards surfacing insights derived over telemetry data from immersive experiences.”

Plaid
“Four things are crucial for observability analytics; interactive queries, scale, real-time ingest, and price/performance. That is why we chose Imply and Druid.”
© 2022 Imply. All rights reserved. Imply and the Imply logo, are trademarks of Imply Data, Inc. in the U.S. and/or other countries. Apache Druid, Druid and the Druid logo are either registered trademarks or trademarks of the Apache Software Foundation in the USA and/or other countries. All other marks and logos are the property of their respective owners.