Introduction
The potential of the advertising market is enormous. In 2022, roughly $880 billion will be spent on advertising, with more than 90% going to web, mobile, in-game, and other digital ads. Success in digital advertising is not possible without AdTech: the software and tools used to buy, sell, deliver, and analyze billions of targeted digital ads every hour. AdTech itself is now a $30B global industry, with a growing group of providers offering support for different segments of the AdTech ecosystem.
AdTech and big data are inseparable—to exist in the AdTech industry is to work with terabytes if not petabytes of data generated from user behavior, ad engagement, real-time auctions, and more. And when it comes to speed, the stakes are high: much of AdTech operators’ business hinges on how fast they can react based on streaming data. Advertisers, ad exchange platforms, and publishers drive demand for this data, which they need to convert consumers and fill ad inventory. So, to succeed in this ever-changing landscape, AdTech providers need to deliver real-time analytics to their internal and external customers.
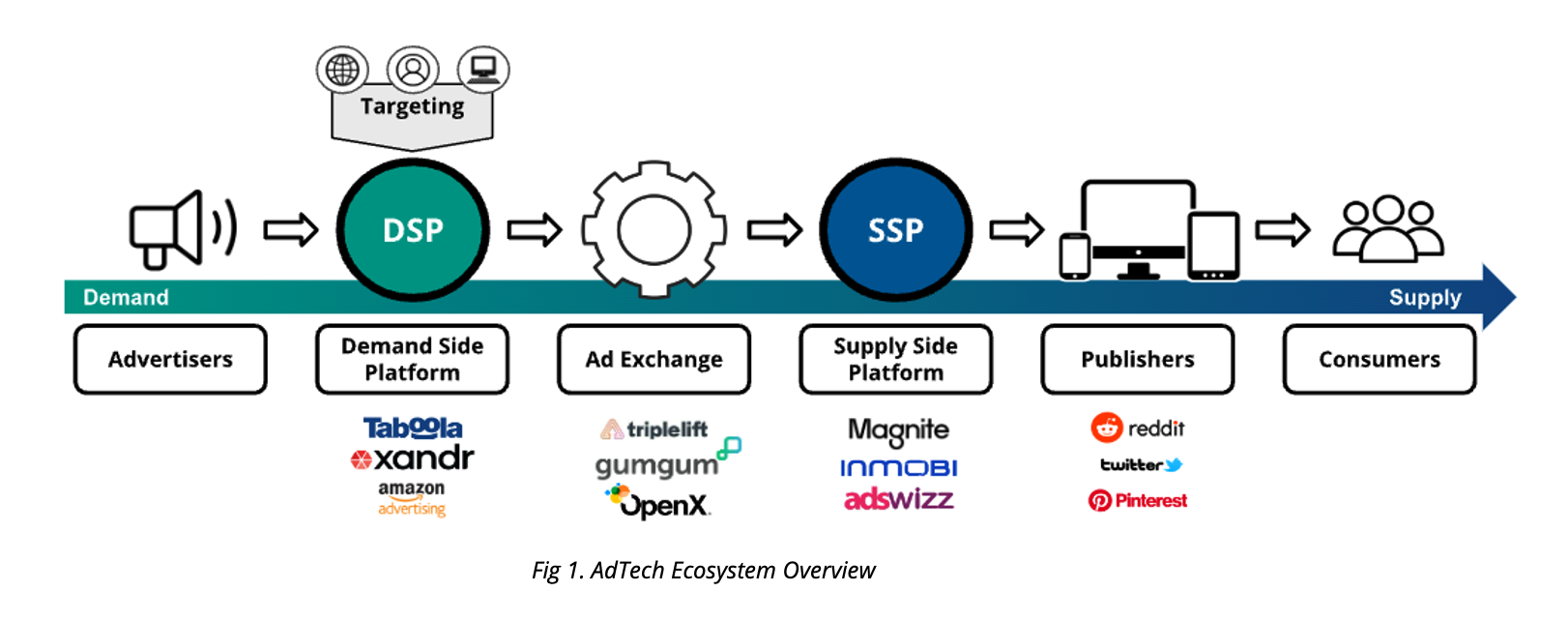
Fig 1. AdTech Ecosystem Overview
Apache Druid is an analytics database built for real-time ingestion, fast query performance, and high availability. Druid was initially designed to power user-facing analytics applications for event-based digital advertising data, ingesting a billion events in under a minute and querying those events in under a second. After a decade of use by over 1,000 organizations, Druid today can manage much larger data sets at even higher speeds. It is often used to compute impressions, clicks, eCPM, and other key conversion metrics, but is just as powerful for user activity and platform health monitoring.
Use Case #1: Real-time Bidding
Real-Time Bidding (RTB) is the process of automating auctions to allow publishers to make ad inventory available and advertisers to purchase ad placement. Speed is crucial to success in RTB—as the process of sending bids, evaluating bids against targeting criteria, determining inventory price, and ultimately placing an ad all takes place programmatically, within 300ms or less (faster than the blink of an eye).
While racing the clock, RTB operators are processing massive amounts of data. Each step in the bidding process involves sending or receiving information about the user, the browser and OS they’re using, the advertiser, and more, which translates to billions, or even trillions, of data events per day. With this data, RTB operators need to give their sellers, marketers, and users the ability to specify targeting criteria, evaluate current and historical ad performance, and predict how well future campaigns are expected to perform—all in real time.
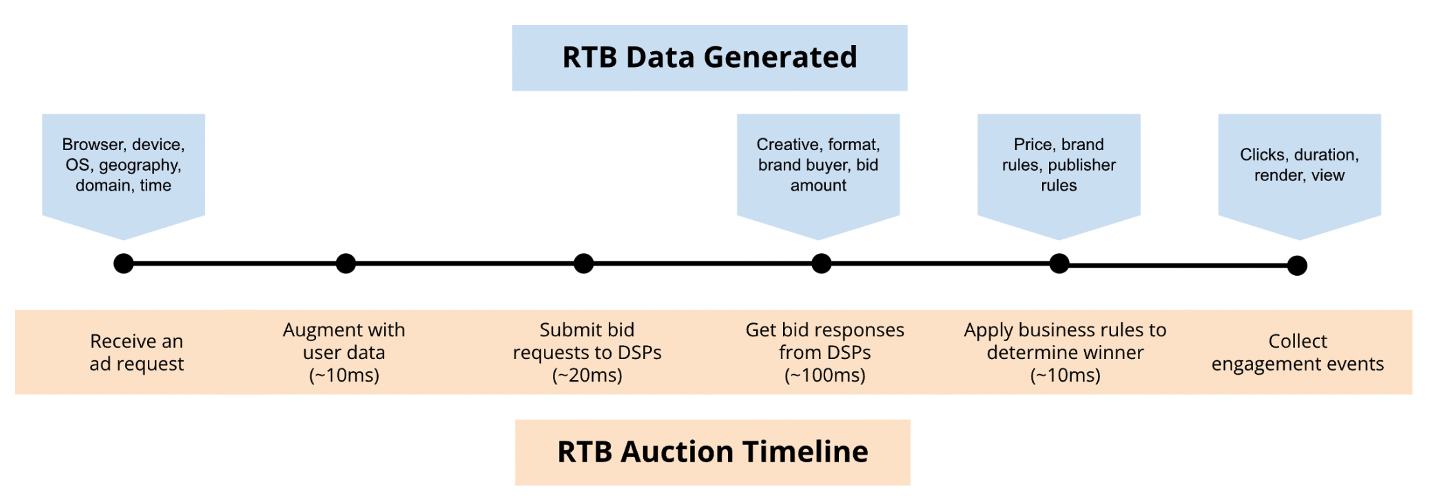
Fig 2. Real-time Bidding Auction Timeline and Data Points
Challenges
- Speed is key, and every millisecond counts to maintain competitiveness.
- Always-on operations with no room for data loss or downtime—planned or unplanned.
- Cost of processing and storage on ever-increasing data volumes.
- High concurrency, with hundreds or thousands of queries hitting the database at once.
- High cardinality adds volume to data, putting a strain on complex and interactive queries.
Why Use Druid for Real-time Bidding?
Cost-efficient scaling: Big data is limited by money, not technology. For use cases that involve processing terabytes or petabytes of data, the cost of querying and storing that data can quickly become cost-prohibitive. Druid’s elastic architecture scales based on usage, while its pre-aggregation, rollup, and compression capabilities help to curb costs by minimizing the amount of raw data that needs to be stored.
No downtime, no data loss: Advertising is a 24x7x365 industry, and any downtime or data loss can cause significant disruption to your AdTech business. Druid is highly resilient, with zero downtime design and self-healing to enable ongoing operations when hardware fails. All data has at least two copies in high-performance data nodes, plus another copy in highly durable object storage. With continuous backup and exactly-once semantics for event streams, Druid is also designed for zero data loss.
Contextualized data: In the context of running ad campaigns, the ability to combine real-time data with historical data to identify outliers and make predictions is core to success. Druid enables analysis of streaming and batch data together, seamlessly ingesting stream events (from tools like Apache Kafka and Amazon Kinesis) and batch data (from source files or other databases, for example) to enable real-time analytics in context.
Example: Leading Ad Exchange Scales to Billions of RTB Events Daily Using Druid
A US-based ad exchange platform and market leader in native programmatic advertisements, this company specializes in transforming video and photo content into engaging, native ads that match the look and feel of a publisher’s website. The exchange’s platform enables advertisers and publishers to programmatically buy and sell ad placement. In recent years, the company’s data pipeline scaled from processing millions of events per day to billions—and continues to grow.
To support this pipeline, the company needed a system that could:
- Scale with rapid data volume growth and support high cardinality
- Aggregate data in a cost-effective manner
- Handle large query loads on their analytics applications, and deliver data to those tools within expected SLAs
The company’s high cardinality data, meaning many distinct values across many dimensions, resulted in snowballing data volumes. For example, with every bid request—of which the exchange receives billions per day—the platform ingests information about the browser, region, operating system, and more. For any single ad request, there could be hundreds of unique dimensions. When performing data analysis, that’s a lot of data to slice and dice.
Minimizing data processing and storage costs is especially important in AdTech, where the ROI of processing and storing data is not guaranteed. When an auction is lost, the exchange is still stuck with data expenses associated with running the auction—including the storage of several days to weeks’ worth of auction log-level data. With the company’s legacy database, Amazon Redshift, storing data for even one or two days became cost-prohibitive. So the challenge remained: how could they make their platform accessible to users, while making it cost-effective enough to handle the scale?
Ultimately, the company switched from Redshift to Druid to provide insights into performance aspects of its native programmatic exchange for sales/business development opportunities, as well as provide reporting used by advertisers and publishers to increase the ROI on their ad campaigns or inventory. With Druid, they were able to go from minutes to subsecond query response times, scale to hundreds of metrics and dimensions with ease, and replace dozens of data tables with a single table—all without breaking the bank.
“Druid’s key advantage is that it’s designed for interactive analytics. We moved almost all of our Redshift tasks to Druid, which enabled us to load all of our dimensions into a single file and let Druid handle all of the indexing and optimization. Bottom line is if you want something that makes it quick and easy to slice and dice, use Druid.” – VP of Engineering
Use Case #2: Platform and Audience Insights
Providing transparency is a critical feature for most businesses within the AdTech ecosystem. Whether it’s reporting to advertisers on how users engage with their ads or enabling them to assess the value of every consumer and optimize their bidding accordingly, AdTech companies must be able to deliver and act on more data, faster, and at every level of their organization.
Making real-time decisions such as where to place an ad and how much that ad placement should cost based on product or platform data depends on a database that can support low-latency, ad-hoc queries at scale. This is precisely where Druid shines: powering applications that deal with high data volumes, require low-latency queries, support high concurrency, and enable the analysis of streaming and batch data together, in real time.
Challenges
- Interactivity for user-facing applications.
- Ad-hoc drill-down and rollup queries on highly granular, petabyte-scale data.
- High concurrency, with hundreds or thousands of queries hitting the database at once.
Why use Druid for platform and audience insights?
Continuous interactivity: Druid is built to support ad-hoc drill-down queries across many dimensions, enabling you to have interactive conversations with your data and gain a deep understanding of the trends that are impacting your customers and your business.
Instant data visibility: Druid is built for rapid data ingest-to-analysis pipelines, with native integration with stream data sources like Apache Kafka and Amazon Kinesis. With Druid, you don’t wait for events to land in a data store before they can be queried—instead, Druid’s “query on arrival” ingestion model makes data instantly available to your application. If you need proven high performance, with millisecond-range queries on multi-Petabyte data sets, Druid will deliver.
High concurrency: An AdTech application can easily receive hundreds of thousands of incoming bid requests within 100ms. Druid makes it possible to run thousands of concurrent queries on that data from thousands of users, without sacrificing query speed or application performance.
Example: Reddit Scales its Reporting Service with Druid
Social content giant Reddit generates tens of gigabytes of event data per hour from advertisements on its platform. To let advertisers both understand their impact and decide how to target their spending, Reddit needed to enable interactive queries across the last six months of data—hundreds of billions of raw events to slice and dice. But Reddit also needed to empower advertisers to see user groups and sizes in real time, adjusting based on interests (sports, art, movies, technology…) and locations to find how many Reddit users fit their target. To do this, they turned to Druid and Imply.
Reddit’s Druid-powered application powers two types of analyses:
- Internal: Reddit automated their billing monitoring system to track advertisers’ spending on the platform and keep tabs on any billing issues that arise. They also use this information to make pricing adjustments on their ad inventory, increasing or decreasing prices based on fluctuations in demand.
- External: Reddit enables their advertisers to analyze user activity on Reddit in real-time, with the ability to visualize data across numerous user behavior dimensions such as clicks, scrolls, and subreddit page views. This enables advertisers to see how Redditors engage with their ads and make adjustments or launch new campaigns based on up-to-date audience insights.
With Druid behind their customer-facing analytics application, Reddit provides advertisers with a real-time look at the behaviors, demographics, and interests of Reddit users. Druid’s search and filter capabilities enable rapid, easy drill-downs of users along any set of attributes, making it effortless to measure and compare user activity by age, location, interest, and more.
Druid’s efficient ingestion-time aggregation saved Reddit from having to write custom logic to pre-aggregate data based on their product needs. Additionally, their reporting service is no longer responsible for implementing any group-by or aggregation logic since it is now just part of the query sent to Druid. This has dramatically reduced Reddit’s reporting pipeline’s maintenance burden and allows them to deliver a more streamlined product.
“By using Apache Druid and Imply, we can ingest multiple events straight from Kafka and our data lake, ensuring advertisers have the information they need for successful campaigns in real-time.” – Shariq Rizvi, Ads Monetization EVP at Reddit
Reddit also uses Pivot, Imply’s intuitive data visualization UI, to build interactive dashboards that monitor the health of their business and equip advertisers with real-time campaign insights. These whitelabled dashboards serve multiple aspects of Reddit’s advertising business, from internal sales and product applications to customer-facing tools for precise audience targeting and campaign performance tracking. Building with Pivot enabled Reddit to deploy powerful, intuitive data visualizations without having to develop a UI from scratch—significantly accelerating time-to-value for their service.
Example: Adikteev Provides User Behavior Insights to Customers using Druid
Adikteev is the leading mobile app re-engagement platform for performance-driven marketers, helping the world’s top-spending app publishers increase retention, reacquire churned users and drive revenue.
Adikteev designs and executes mobile marketing campaigns for their clients in order to boost app use and engagement. To do this, they capture detailed telemetry data and analyze how retargeting campaigns have influenced user behavior; not just purchases, but also impressions, time spent on different screens, and other relevant actions. Adikteev analyzes these outcomes by user segment based on numerous dimensions such as device, OS, location, and app-specific information. All of this data streams in real-time from millions of devices, apps, campaigns, and assets, such as ads.
Before implementing Druid, the data flowed from Adikteev’s MySQL database to static Tableau dashboards, which were used across almost all departments and functions—from front-line practitioners to C-suite executives—to monitor trends, metrics, and KPIs. While these dashboards were useful for pre-defined reporting use cases, Adikteev needed more. Internal users needed to perform quick, exploratory data analysis, but the legacy architecture proved to be too slow to handle ad-hoc queries.
Switching to Druid enabled Adikteev to achieve excellent operational performance for their internal applications, but also opened up the opportunity to provide analytics to their customers. With Druid and Imply, Adikteev built customer-facing dashboards that enable users to understand how well their campaigns are performing, with the flexibility to import data from their own systems to analyze alongside Adikteev datapoints. Besides helping customers make strategic re-targeting decisions, Adikteev’s customer-facing analytics app strengthened trust with customers and reduced churn risk.
“By using Druid and Imply for real-time self-service analytics instead of relying on slow and stale dashboards, we have been able to achieve both internal productivity gains and faster decision-making. We’re also able to provide our customers with the data they need to improve the performance and effectiveness of their retargeting campaigns and notify them of potentially serious threats to their business—often days before the client would have noticed it themselves.” – Margot Miller, Adikteev
Use Case #3: Spam and Fraud Detection
Ad fraud is a large and growing concern in the AdTech industry. The presence of invalid traffic and ad fraud impedes ad performance, corrupts reporting, and costs advertisers billions of dollars in lost revenue. For an AdTech operator, being able to spot false traffic and suspicious bidding activity is critical to the integrity of their programmatic advertising products. For a publisher, spam and abuse detection and prevention are critical to enhancing the health of their platform—making it more attractive to advertisers.
To keep detection from slipping from seconds to days, security analytics applications need to query events the moment that they occur. As each customer’s landscape is unique, getting data from a multitude of sources and formats into an effective platform for analysis can be onerous using traditional data engineering methods. This is why AdTech operators, marketers, and vendors are building modern analytics applications powered by real-time analytics databases for security and fraud analysis. These analytics apps use real-time analytics databases to collect and aggregate both real-time streams and historical batch data, monitor events continuously with subsecond responses, and provide the context required to distinguish genuine threats from false positives.
Challenges
- Many points in the buyer’s journey to analyze.
- Scale: for each of the buyer journey stages, there is lots of data with high dimensionality and cardinality.
- Critical event-to-reporting timeline.
Why use Druid for spam and fraud detection?
Self-serve analytics: Unlock low-latency, ad-hoc drill-downs for security threat detection that enable teams across your organization to quickly spot and investigate security issues.
Real-time ingestion and querying: Ad fraud is a moving target—and fraudsters are always inventing new ways to mimic human behaviors. The ability to correlate threats across multiple platforms and data sources enables your business to identify these tactics with higher speed and accuracy.
Always-on operability: Fraudsters don’t take vacations, and neither can security analytics. Druid is designed for zero downtime (planned and unplanned) and zero data loss so that mission-critical security applications work 24/7.
Example: Using Druid to Fight Fraud at Ibotta
Ibotta is a free cashback rewards platform that enables advertisers to reach more than 120 million shoppers through its network of retailers, publishers, and owned digital properties. In the fast-paced world of online advertising, the window for detecting and stopping
fraud has shrunk to sub-seconds. To address this, Ibotta implemented a multifaceted fraud prevention strategy that combines data from third-party vendors with Iboitta’s own data to make decisions about fraud in real time.
For modern analytics applications focused on fraud detection, the ability to quickly dissect and address potential threats is as important as initial detection. Both historical data for context and real-time events are critical. Ibotta’s legacy architecture, built with Splunk, Elasticsearch, Presto, and Amplitude, did not meet the company’s real-time requirements. Without a database purpose-built to ingest and analyze real-time data to users in subseconds, Ibotta’s on-call team faced several roadblocks:
- Dispersed data: In isolation, the data provided by Ibotta’s third-party vendors told a powerful but incomplete story. They needed a way to combine data from multiple sources in a way that allowed for rapid slice-and-dice analysis.
- Obsolete dashboards: The tools Ibotta had for visualizing their fraud landscape were ill-equipped to ingest real-time data and weren’t agile enough for the pace of change. The shelf life on Ibotta’s BI dashboards shrunk to hours, at best.
- Slow queries: In order to monitor for fraud and other anomalies, Ibotta needed to be able to quickly query and visualize large datasets. Ibotta’s existing analytics stack wasn’t designed for investigative analysis where response time is critical.
To begin addressing these challenges, Ibotta first separated their use cases into three storage layers: a data lake, data warehouse, and data river. The data lake and warehouse layers are used for long-term historical trend analysis, BI reporting, and other use cases where longer SLAs are acceptable. Ibotta then chose Apache Druid as the foundation for the data river, where curated and denormalized data streams are leveraged for time-critical analytics. This tiered architecture filled a major gap in Ibotta’s ecosystem that had prevented them from effectively conducting ad hoc analysis on real-time data.
Since deploying Imply powered by Apache Druid as their core analytics engine and Imply Pivot as their internal operations UI, Ibotta has significantly reduced the maintenance time and risk of operations. Slow queries and syntax struggles have been replaced by Pivot’s drill-down functionality with sub-second response times. With Pivot, Ibotta built highly interactive, real-time dashboards that incorporate both internal customer interaction events and data from third-party vendors, providing teams with a holistic view of the company’s full data ecosystem.
“We found Druid and Imply to be clearly the most robust solution out of all of the platforms we were considering, that would allow us to meet three overarching business goals: supporting rapid incident response, building trust with our end users and partners through proactive fraud prevention, and enabling more of our team to easily make use of our data.” – Jaylyn Stoesz, Data Engineer at Ibotta
About Druid
What is Apache Druid?
Apache Druid is the open-source, real-time analytics database used by developers at 1000s of leading organizations to power modern analytics applications. These applications deliver operational visibility at scale, rapid drill-down exploration, real-time inference, and insights externally to customers.
Developers turn to Apache Druid for its unique ability to enable interactive analytics at any scale, high concurrency at the best value, and insights on streaming and batch data. Its hyper-efficient architecture delivers subsecond responses on billions to trillions of rows for 100s to 1000s of concurrent users with near-infinite scale.
How is Apache Druid unique?
Apache Druid is the right choice when powering an analytics application at any scale, for any number of users, and across streaming and batch data. Capabilities include:
Subsecond at scale: From TBs to PBs and 100s to 1000s of concurrent queries, Druid’s unique distributed architecture delivers consistent subsecond query response times – and does it without breaking the bank. It combines the performance of shared-nothing with the elasticity of shared-everything.
True stream ingestion: Druid was built for streaming data with native integration with Apache Kafka and AWS Kinesis. It supports massive-scale ingestion of millions of events per second, query-on-arrival to analyze events instantly, and guaranteed exactly-once consistency to ensure data quality.
Non-stop reliability: For always-on applications, Druid is designed to never go down and never lose data. Its architecture is built for high availability and no data loss for streams via continuous backup and automatic recovery and rebalancing.
About Imply
Imply delivers the complete developer experience for Apache Druid. Founded by its original creators, Imply adds to the speed and scale of the database with committer-driven expertise, effortless operations, and flexible deployment to meet developers’ application requirements with ease.