CONSIDERATION 1:
High Concurrency
Snowflake’s design is optimized for infrequent use. High concurrency can become expensive.
Snowflake
Snowflake’s value proposition is built on a pay-as-you-go model that saves money when your system is not in use. This makes it ideal for relatively infrequent queries with a small number of users, and is why the maximum concurrency of a cluster is 8. Of course this can be adjusted and tested by an administrator, and up to 10 clusters can be added to a virtual warehouse with the more expensive enterprise edition. This accommodates as many as 80 concurrent queries (not necessarily users). But consider how burdensome and costly this will be with concurrent user growth.
Druid
Druid’s unique architecture handles high concurrency with ease, and it is not unusual for systems to support hundreds and even thousands of concurrent users. Quite the opposite of Snowflake, Druid is designed for high queries per second requirements, with an efficient scatter-gather query engine that is highly distributed: scale out instead of scale up. With Druid, ingestion, query, and orchestration can each be scaled independently as loosely coupled services.
CONSIDERATION 2:
Sub-Second Response Times
Snowflake’s architecture requires bringing data to compute at query time, which inhibits query performance.
Snowflake
Because Snowflake is designed to save money with pay-as-you-go licensing, they implement an architecture of separate storage and compute. This means at query time data has to move over a network from deep storage to the compute layer. Snowflake implements local caching to compensate, but even with this, initial query times can take minutes. Repeated queries will run faster once cached, but this does not account for ad-hoc, interactive queries or systems where new data is added constantly.
Druid
Druid also implements a separate storage-compute architecture for flexibility and cost saving measures like data tiering. Crucially, however, Druid pre-fetches all data to the compute layer, which means that nearly every query will be sub-second, even as data volumes grow since queries never are waiting on a caching algorithm to catch up. With a very efficient storage design that integrates automatic indexing (including inverted indexes to reduce scans) with highly compressed, columnar data, this architecture provides the best performance at scale.
CONSIDERATION 3:
Real-Time Data Ingestion
Snowflake can connect to streaming data, but through a connector that ultimately ingests the data via batch processing.
Snowflake
While Snowflake has connectors to streaming data (such as Kafka), it still has only one way to load the data: buffered in batches. Queries must wait for data to be batch-loaded and persisted in storage, and further delays happen with checks to make sure events are loaded exactly once, a difficult proposition when thousands or even millions of events are generated each second.
Druid
With native support for both Kafka and Kinesis, you do not need a connector to install and maintain in order to ingest real-time data. Druid can query streaming data the moment it arrives at the cluster, even millions of events per second. There’s no need to wait as it makes its way to storage. Further, because Druid ingests streaming data in an event-by-event manner, it automatically ensures exactly-once ingestion.
CONSIDERATION 4:
Flexible Deployment Options
Snowflake deployment is limited to their cloud service.
Snowflake
For some organizations, a proprietary, fully-managed cloud is a good choice. But this can be problematic if you require more control or have regulatory requirements you need to meet.
Druid
Druid is open source, so you are not locked-in to a particular vendor. Imply offers flexible cloud deployments for Druid, including a fully-managed DBaaS with Imply Polaris. Imply’s Enterprise Hybrid is co-managed by you and Imply on your cloud, with you in control. You determine when updates happen, giving you time to fully test your application. Additionally, Imply’s enterprise solution is ready for organizations that still need to deploy and completely control their own systems.
Hear From a Customer
Learn why Athena Health switched from Snowflake to Druid for their analytics apps.

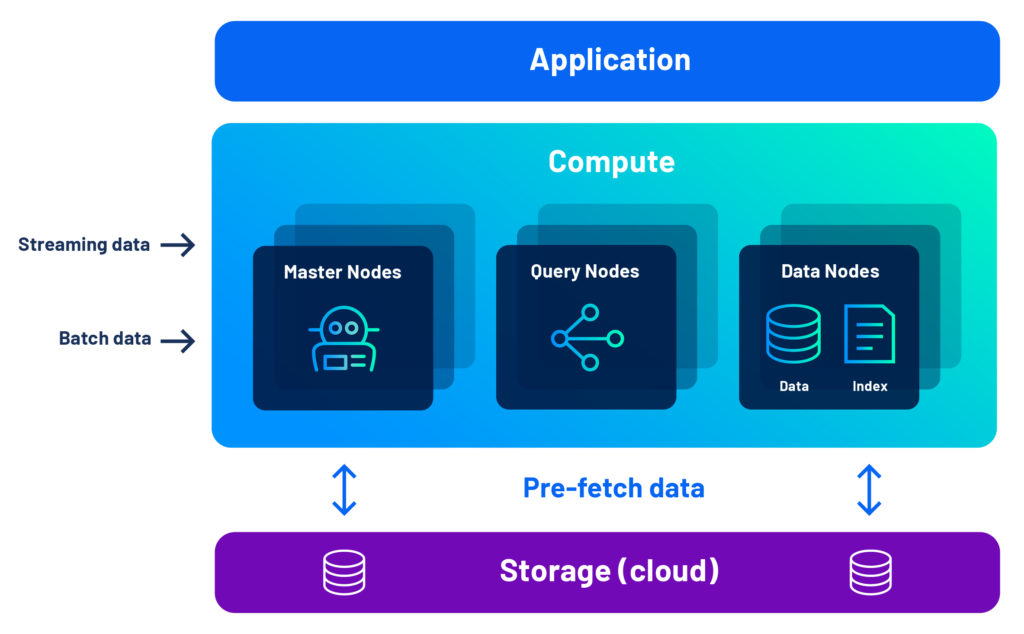
Druid’s Architecture Advantage
With Druid, you get the performance advantage of a shared-nothing cluster, combined with the flexibility of separate compute and storage, thanks to our unique combination of pre-fetch, data segments, and multi-level indexing.
Developers love Druid because it gives their analytics applications the interactivity, concurrency, and resilience they need.
In a world full of databases, learn how Apache Druid makes real-time analytics apps a reality. Read our latest whitepaper on Druid Architecture & Concepts
Leading companies leveraging Apache Druid and Imply

“By using Apache Druid and Imply, we can ingest multiple events straight from Kafka and our data lake, ensuring advertisers have the information they need for successful campaigns in real-time.”

Cisco ThousandEyes
“To build our industry-leading solutions, we leverage the most advanced technologies, including Imply and Druid, which provides an interactive, highly scalable, and real-time analytics engine, helping us create differentiated offerings.”

GameAnalytics
“We wanted to build a customer-facing analytics application that combined the performance of pre-computed queries with the ability to issue arbitrary ad-hoc queries without restrictions. We selected Imply and Druid as the engine for our analytics application, as they are built from the ground up for interactive analytics at scale.”

Sift
“Imply and Druid offer a unique set of benefits to Sift as the analytics engine behind Watchtower, our automated monitoring tool. Imply provides us with real-time data ingestion, the ability to aggregate data by a variety of dimensions from thousands of servers, and the capacity to query across a moving time window with on-demand analysis and visualization.”

Strivr
“We chose Imply and Druid as our analytics database due to its scalable and cost-effective analytics capabilities, as well as its flexibility to analyze data across multiple dimensions. It is key to powering the analytics engine behind our interactive, customer-facing dashboards surfacing insights derived over telemetry data from immersive experiences.”

Plaid
“Four things are crucial for observability analytics; interactive queries, scale, real-time ingest, and price/performance. That is why we chose Imply and Druid.”
© 2023 Imply. All rights reserved. Imply and the Imply logo, are trademarks of Imply Data, Inc. in the U.S. and/or other countries. Apache Druid, Druid and the Druid logo are either registered trademarks or trademarks of the Apache Software Foundation in the USA and/or other countries. All other marks and logos are the property of their respective owners.