Farewell Lambda Architectures: Exactly-Once Streaming Ingestion in Druid
Jul 05, 2016
David Lim
The recent rise of stream analytics has been generating palpable excitement in the big data world and it’s not all that hard to see why. Gone are the days when slow and unwieldy batch processing systems with their high query latencies were the only option for processing large quantities of data. Today, many companies are turning to nimble streaming solutions which are enabling them to understand and make business decisions from their data immediately, resulting in an operational agility that was unthinkable only a few years ago. In many cases, the ability to analyze data in real-time has not only made businesses more responsive but has also opened up new avenues of opportunity to better understand and engage their customers.
On the Druid project, we are extremely interested in the maturation of streaming technologies. Although Druid is a system able to handle vast amounts of data simultaneously from both batch and streaming sources, it is in stream-oriented systems where Druid really shines, allowing users to execute sub-second class queries against dynamic indices being updated in real-time. This has given rise to a new breed of exploratory analytics powerful enough to support interactively-fast dashboards backed not only by petabytes of historical data but also real-time events.
Engineering problems typically involve tradeoffs, and constructing distributed data pipelines is no exception. Batch processing systems are very reliable but have frustratingly high latencies that stretch out the waiting time between event and insight. Streaming systems are able to provide low latency processing, but often have difficulties supporting reprocessing and offering exactly-once message delivery guarantees.
Previously, reliable Druid deployments utilized a combination of streaming and batch pipelines known as a Lambda Architecture to support the immediate querying of real-time events while maintaining long-term correctness when message delivery was not guaranteed. Queries performed against the streamed data would return “good enough” results which may have missing or repeated data, while a batch ingestion job ran periodically to rebuild the indices once we were sure that all the data was available.
Lambda Architectures are effective, but are rightly challenged for their inherent complexity and the engineering and operational overhead involved in working with two separate pipelines that must play nicely together. We have been working hard to advance Druid’s ingestion technology to take advantage of the latency benefits of streaming systems while offering better correctness guarantees, and the 0.9.1.1 release represents a significant milestone in this pursuit.
The Difficulty With Exactly-Once Ingestion
In an ideal computing world, messages passed between components of a distributed system would be delivered to the recipient exactly one time. In practice however, achieving this kind of guarantee is non-trivial, and progress towards this ideal requires thoughtful design on the part of both the sender and the receiver.
The difficulty in achieving exactly-once delivery is fairly easy to reason about. As an example: having sent a message and not receiving an acknowledgment, what action should the sender subsequently take? The lack of acknowledgment could be because the message was not received, which leaves ambiguity in whether or not the message will ever be received in the future. If on the other hand the message delivery was successful, the lack of response may indicate that the recipient failed during processing, or it may be because the acknowledgment was lost on the way back to the sender. Without knowing exactly what happened, the system must make a decision between retrying or continuing on, and the decision it makes could lead to dropped data or repeated data.
Exactly-once delivery requires a coordination mechanism between the sender and receiver which is able to tolerate failures in the system. In the case of Druid ingestion, we need to be resilient to failures in the worker nodes and have the ability to reprocess data that was previously indexed but still stored in-memory or on local disk when the failure occurred. The ability to coordinate a re-read of data is implementation specific, and in Druid 0.9.1.1 we are introducing a new indexing service that is able to provide exactly-once delivery guarantees when ingesting data from Apache Kafka.
The Kafka Indexing Task
Apache Kafka is an ideal system to integrate with Druid, not only for its high throughput and reliability, but also because it has a well-designed architecture that allows downstream systems fine and deterministic control over their read position in the message stream. Kafka has the following properties that make exactly-once ingestion possible:
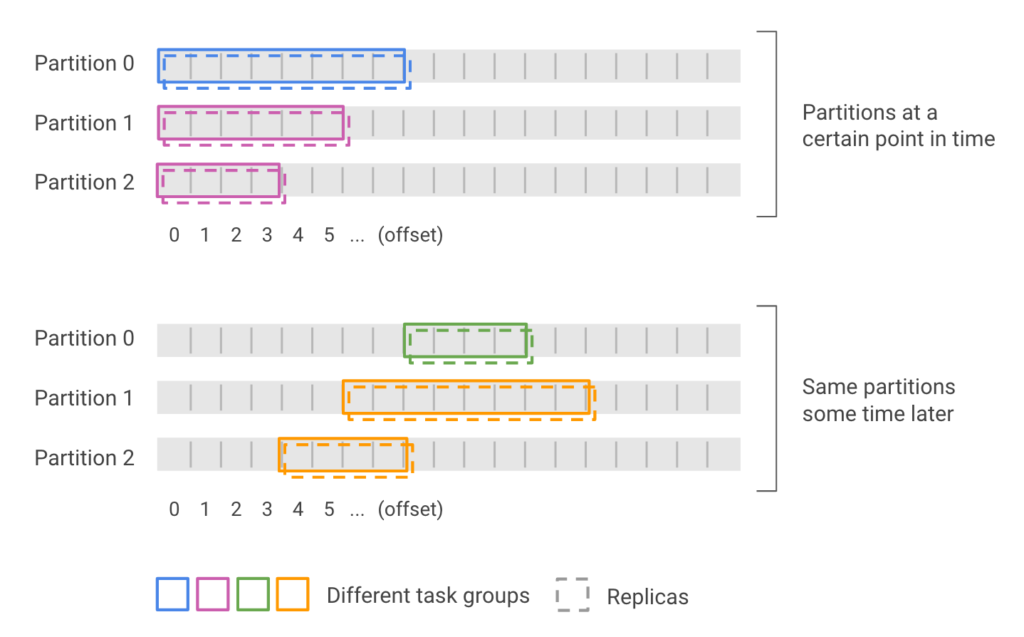
Each message written to Kafka is placed into an ordered and immutable sequence called a partition and is assigned a sequentially incrementing identifier called an offset. Thus, an individual message can be uniquely identified by its partition-offset pair and a message’s position will never change relative to all other preceding and succeeding elements in the sequence.
Messages are pulled by the consumers rather than being pushed by the brokers. This allows consumers to manage their own rate of ingestion and avoids a number of complications inherent in push-based systems.
Consumers can seek to any offset in any partition, allowing them to “rewind” the stream to any position in the past while the data is still present in Kafka’s buffers.
Messages are tagged with metadata that includes their partition and offset. This provides consumers with a mechanism to verify that they received what they expected and that no messages were inadvertently dropped or re-sent. Equally importantly, it provides consumers with markers that can be used to coordinate reads between processes, suspend and resume ingestion, and rewind to an exact position in the stream for re-reading.
In Druid, the Kafka indexing task utilizes these properties to achieve exactly-once ingestion. Each task is assigned a set of partitions with corresponding start and end offsets and will begin reading messages from Kafka sequentially until all assigned offsets have been read. During reading, every message received is verified to ensure that it follows in sequence from the previously received message before being parsed and added to the index.
When all messages assigned to the task have been read, the task will push the generated segments to deep storage to be loaded by historical nodes and will publish the segments by writing entries in the segment metadata table. Crucially for exactly-once ingestion, the task will also atomically record the final Kafka offsets in the same metadata transaction as the segment entry. This transaction prevents the segment from being published without the offset marker being updated or vice versa. Hence a successful task is guaranteed to have written both a segment descriptor and the corresponding Kafka offsets and a failed task is guaranteed to have written neither.
The offset is used to ensure that no messages are lost or duplicated between indexing tasks, and that indexing tasks which may have read the same offsets cannot both publish their segments. This requirement is enforced by a consistency check that happens when the offset marker is written to the metadata store: if the starting offsets of the to-be-published segment match the ending offsets of the last published segment then the transaction succeeds; otherwise the segment is rejected, since allowing it would mean that at least one message will be repeated or has been dropped. Synchronizing processed events at segment insertion time allows the task to provide an exactly-once guarantee without incurring a performance penalty while the index is being generated.
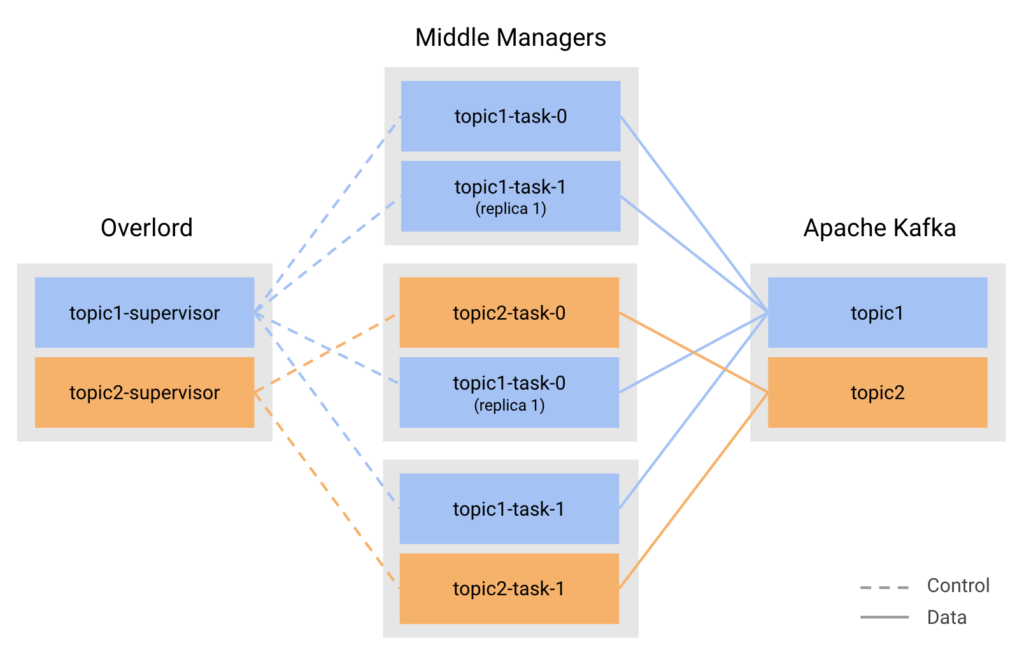
The Kafka Supervisor
Retrying tasks which have failed due to consistency violations is one of the jobs of the Kafka supervisor, which together with the indexing task comprise the Kafka indexing service. The supervisor runs as a component of the Druid overlord and manages the lifecycle of Kafka indexing tasks. A supervisor is configured by submitting a specification to the overlord which contains an indexing schema, the Kafka broker address and topic, and the number of concurrent tasks to run for scalability and redundancy. Supervisors are also provided with a duration defining how long tasks should run, which is necessary since indexing tasks do not push segments to deep storage until they complete and having long-lived tasks is not recommended for stability or scalability.
Once the supervisor is configured, it will create the necessary indexing tasks to achieve the scalability and redundancy targets and will monitor their progress, recreating failed tasks and coordinating the creation of subsequent tasks when the previous ones have completed. The Kafka supervisors are persistent and will survive overlord restarts and leadership changes. Supervisors will also coordinate schema migrations, by automatically stopping tasks running with the old schema and creating new tasks with the new configuration such that no messages are dropped or duplicated during transition.
Farewell Window Periods!
The Kafka indexing task is the first real-time ingestion option in Druid that does not require events to fall within a window period. The window period mechanism existed to simplify the optimal generation of segments but restricted streaming ingestion to relatively recent events. With the removal of the window period restriction, the Kafka indexing service can be used to ingest data with arbitrarily old timestamps, making a batch pipeline unnecessary in many situations.
Note that if your event stream contains a wide range of timestamps relative to your segment granularity, this will result in a large number of segments being created which may have an adverse effect on query performance. If your data falls into this category, you should monitor the number and size of segments created and periodically run batch indexing tasks to compact the segments.
A Few Numbers
The following results were obtained on an Amazon EC2 r3.8xlarge instance (Intel Xeon E5-2670 v2) ingesting randomly generated events. Each event consisted of a value field (processed with a longSum, longMin, and longMax aggregator) and a number of dimensions of varying cardinality. Your results may vary based on tuning, hardware used, and data complexity.
Dimensions/Cardinality
Ingestion rate (events/sec/task)
1 low
160k
1 high
80k
5 low
70k
5 low, 1 high
60k
10 low, 1 high
50k
10 low, 3 high
40k
30 low
30k
50 low
25k
50 high
15k
In our testing, we were able to achieve a sustained aggregate ingestion rate of 3.3M events/sec on a single r3.8xlarge instance when indexing simple events with very high roll-up. When ingesting more complicated data (10 low cardinality dimensions + 1 high cardinality dimension) which required more processing power for index generation and frequent spills to disk, a single instance was able to handle just over 600k events/sec. It is worth noting that these numbers are comparable to Druid’s other stream ingestion methods, demonstrating that the Kafka indexing service is able to provide its additional correctness guarantees without sacrificing performance.
What’s Next?
We are continuing to refine the Kafka indexing service and welcome any suggestions and feature requests. Additionally, the components that make up the indexing service can be easily extended to support ingestion from other sources of data. If you are interested in adding to Druid’s ingestion capabilities, the community warmly welcomes your contributions!
Final Thoughts
The Kafka indexing service is an exciting milestone in the maturity of Druid’s ingestion technology, giving users an easy-to-use mechanism to stream arbitrarily old data into Druid with exactly-once correctness. While it’s important to note that constructing an end-to-end exactly-once streaming pipeline is still a challenging engineering problem, with the Kafka indexing service Druid is making it easier than ever to realize business value from your big data and garner immediate insights from your real-time event streams.
If you are interested in trying out Druid with the Kafka indexing service, we recommend that you check out the documentation and work through our Kafka real-time quickstart which will get you up and running with Druid in minutes.
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....