Snowflake’s IPO today is a testament to the importance of data analytics and the cloud in business today. Snowflake has successfully moved numerous enterprises from expensive and inflexible enterprise data warehouses to a simpler, more scalable cloud-native alternative.
Still, data warehouses, while critical to the enterprise, do not address all of a company’s analytics needs. Every day we talk to companies about using Imply for self-service analytics, and inevitably each will ask why they can’t get the job done using their cloud data warehouse, whether it’s Snowflake, Amazon RedShift, Google Big Query or something else.
This short post describes how Imply complements cloud data warehouses for a particular, growing set of workloads we call interactive data applications, which require sub-second query response at high user concurrency. This kind of workload is not what data warehouses are designed for. Most are built to answer large, complex SQL queries from professional analysts. These queries may take minutes to hours to complete, and that’s fine because they aren’t driven by a real-time requirement.
Congruently, Imply isn’t designed for use on traditional data warehouse workloads. Imply is really good at ingesting data extremely fast (millions of events per second) while simultaneously answering ad-hoc analytic queries with low latency against huge data sets, usually issued iteratively by large numbers of concurrent users.
Imply completes most queries, even against very large data sets, in under a second, which is required to deliver a consistent and fluid experience to the analytics user. So Imply can be an excellent complement to your data warehouse by taking on these types of workloads. With Imply, analysts and businesspeople can creatively explore data and investigate anomalies through iterative ad-hoc queries, while getting sub-second results so their flow is not impaired. For this case, a data warehouse just isn’t fast enough.
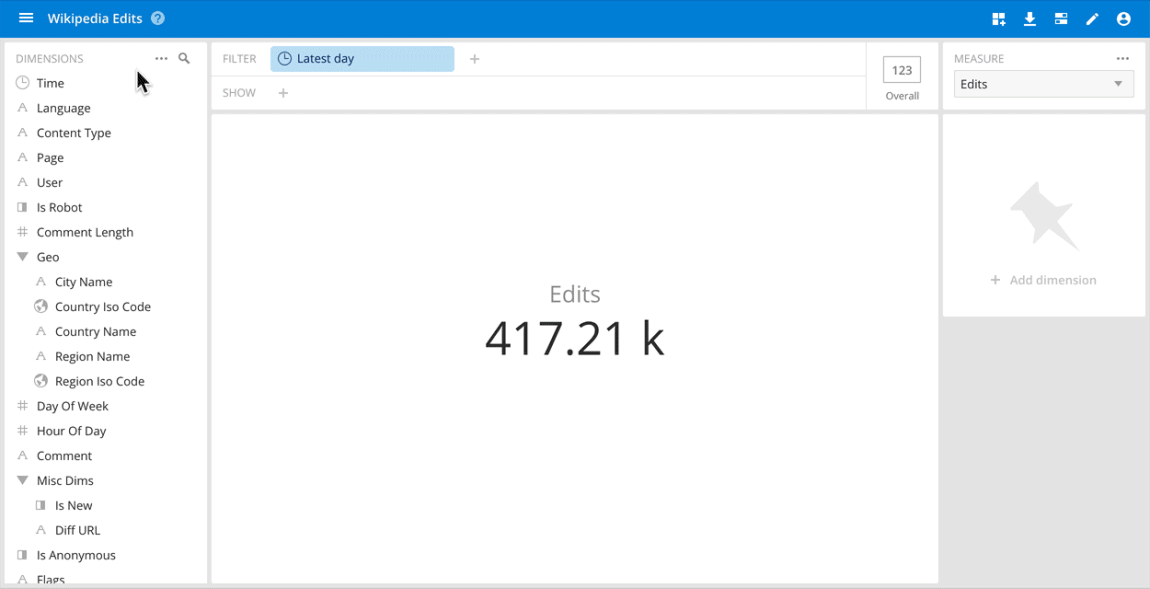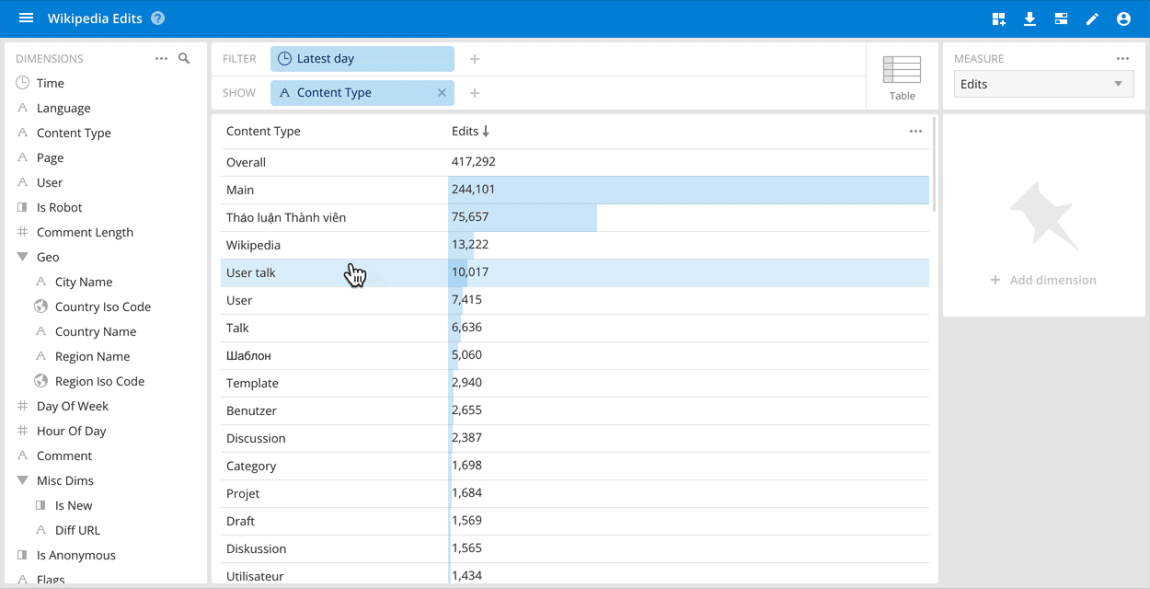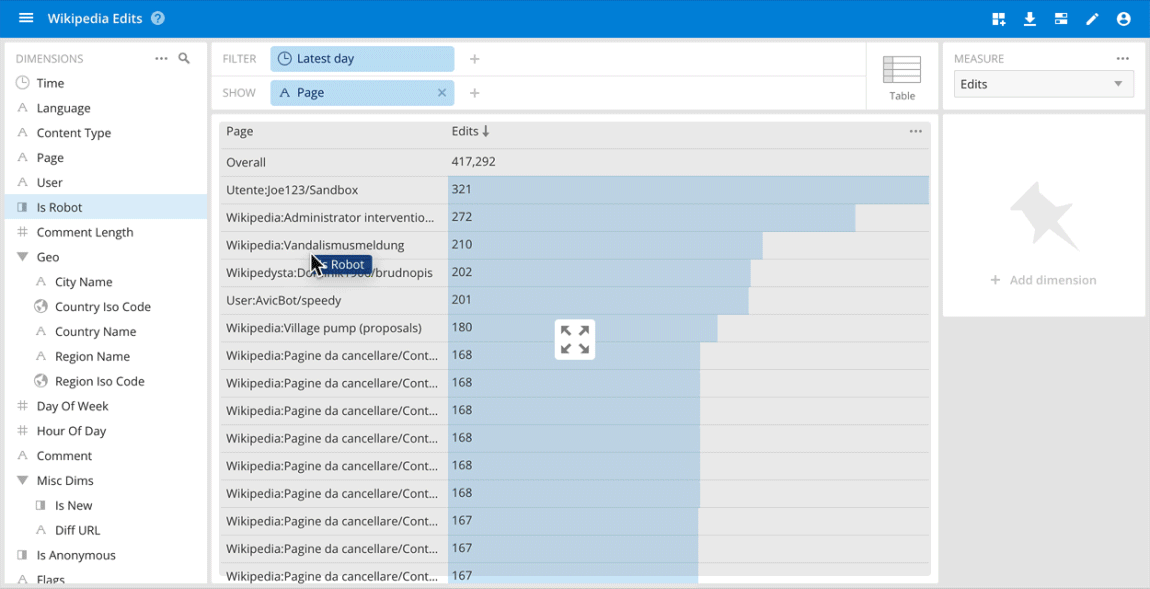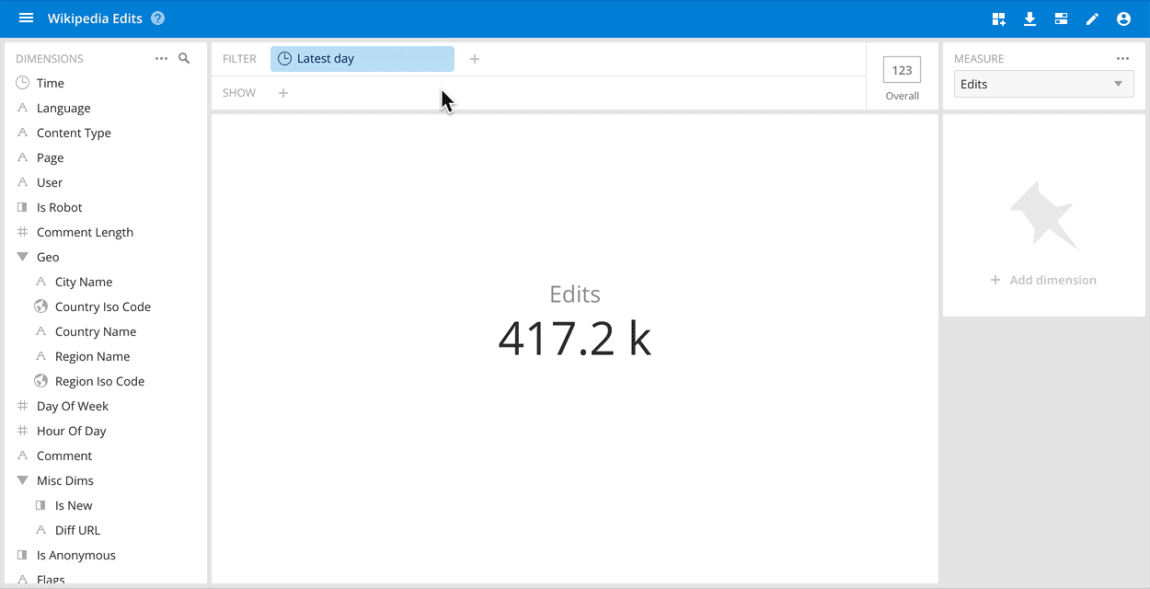
Use cases where ad hoc analysis through an interactive data application is important usually occur on the operational side of analytics. They include quickly understanding anomalies and patterns in clickstreams for digital marketing, product interactions, and user behavior in online games, detecting and diagnosing network traffic issues, handling real-time fraud detection and others.
This type of analysis has a different flavor than advanced analytics performed by the BI group or data science teams; the queries are simple and build on each other in an unplanned fashion as businesspeople apply their intuition and domain-specific expertise to the data analysis through a visual UI.
In a nutshell, data warehouse technology is better for use cases where the end user is a technical analyst and query flexibility takes precedence over query performance. Imply shines when the use cases has one or more of the following requirements:
- powers an interactive data application where users enact OLAP-style slice, dice and drill downs
- requires low-latency ingest at scale
- expects low-latency query response with high user concurrency
- involves real-time streaming data
A great way to get hands-on with Imply is through a Free Imply Download or Imply Cloud Free Tier.