Why GameAnalytics migrated to Apache Druid, and then to Imply
Feb 14, 2019
Ramón Lastres Guerrero, GameAnalytics
This is a guest post from Ramón Lastres Guerrero, Backend Team Lead @ GameAnalytics
Managing a large amount of data is no easy feat, especially when you have a rapidly increasing user base.At GameAnalytics, our user base has grown several times over in the past 12 months, and this growth has promoted us to rethink our user experience analytics system.
GameAnalytics is a popular and free cross-platform tool that helps developers refine their games by making informed changes based on data. Inside the platform, users can see all of the most important KPIs about their titles, including metrics such as ARPPU, retention, conversion, and more. A small backend team manages the core infrastructure behind our product, which is broadly divided among a few areas: ingestion, storage, annotation, analysis, and API access We run most of our infrastructure in AWS.
Life before Druid
Our raw data (JSON events) is delivered and stored in AWS S3. This data is not easily consumable by downstream systems in its preprocessed form, so we enrich and annotate it before it enters our primary analytics system.
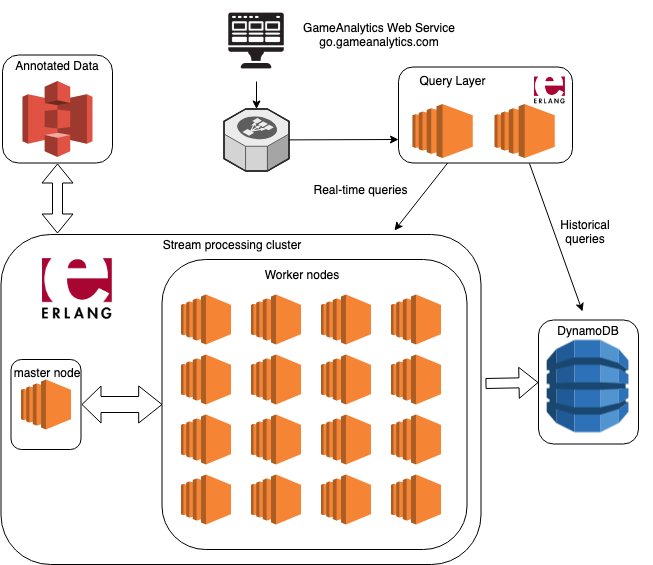
Our original analytics system relied on 2 primary sub-systems: a homegrown Erlang/OTP system for real-time queries, and DynamoDB for historical queries. Our homegrown system utilized a MapReduce-like framework for computing results for real-time queries (data in the past 24 hours), and it was also responsible for creating a set of pre-computed results to store in DynamoDB. Although this setup was able to provide low latency queries through pre-computed results and functioned fine for a period of time, many difficulties began surfacing as we scaled.
Over time, we found our homegrown real-time system was not able to provide the level of stability, reliability, and performance we required. Furthermore, we quickly realized that although key/value stores such as DynamoDB are very good at fast inserts and fast retrievals, they are very limited in their capability to do ad-hoc analysis as data complexity grows.
Pre-computing results is about determining the queries users are likely to make, calculating the results to those queries ahead of time, and storing the queries and results in a fast retrieval system (such as a key/value store such as DynamoDB).The problem with this approach is that as more attributes/dimensions are included in the data, the total query set will grow exponentially in size. It quickly becomes computationally intractable and financially infeasible to pre-compute out all permutations of queries and results and store them. To combat these scalability issues, we initially tried to reduce the set of queries users could issue. We limited users to be able to only filter on a single attribute/dimension in their queries, but this became increasingly annoying for our clients as they could not do any ad-hoc analysis on their data. We quickly realized a new system was needed.
Selecting Druid
As we started searching for a new system to power our core analytics, we wanted to be able to offer customers the performance they had with pre-computed queries, but also empower them to issue arbitrary ad-hoc queries without restrictions on the number of dimensions they could group and filter on. We initially looked at timeseries databases such as Riak Timeseries (our team’s skillset is in Erlang and Riak is written in Erlang), but realized TSDBs aren’t great when grouping or filtering on dimensions that are not time Our focus then shifted to Druid.
Through our tests of Druid, we learned that we could leverage it as a single system for both our real-time and historical analysis Furthermore, it is built from the ground up for ad-hoc, multi-dimensional analysis As opposed to precomputing results, Druid instead stores an optimized, indexed version of raw data, and enables any arbitrary query to be issued against this data at any time Most queries we tried were completed in under a second.
As we became more familiar with the system, we also found that there was much more we could do with Druid than we could with our legacy system. We can stream data directly into Druid, which meant we could turn our analytics infrastructure to become entirely real-time Some of our other favourite features so far include:
Multi-dimensional filtering
Clear separation of resources for ingestion and query layer
More flexibility with fine-grained sizing of the cluster (we can now scale it up or down in parts)
Reprocessing data, without disturbing the rest of the DB and even externally using Hadoop/EMR
Built-in reliable real-time ingestion
Plays well with the tools we use within AWS: S3, Kinesis, EMR
Good support for approximation methods (HyperLogLog)
After comprehensive testing, we decided to invest in Druid as our next generation analytics system.
Productizing Druid with Imply
As a complex distributed system, running self-hosted Druid proved to be challenging. It also became clear that with Druid becoming the center of all our data pipelines, and given the lack of experience of the team with operating and maintaining JVM systems, we would need help.
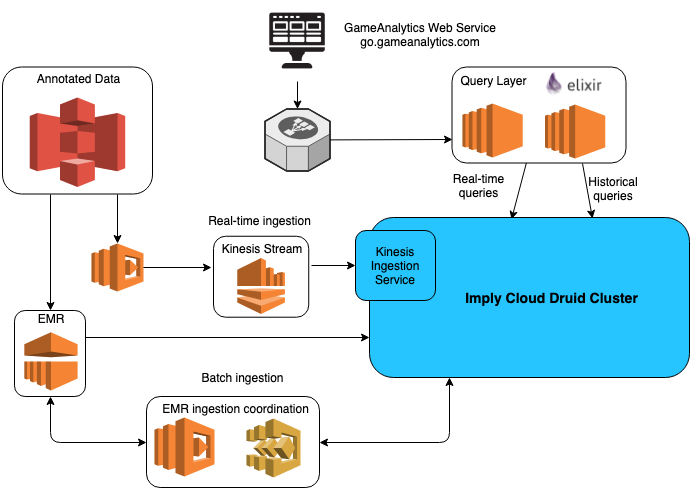
On the backend team, we aim to use managed solutions as much as possible in order to reduce operational overhead. Thus, we partnered with Imply, the company behind Druid, and began using their managed Imply Cloud service, which is 100% Druid at its core. This service let us deploy our Druid application as a service, optimize our costs, and helped us save time. This meant that our small team could focus on other projects without having to maintain a complex deployment codebase.
After partnering with Imply, we found even more value in their suite of products. Pivot is extremely helpful for us, and has become our tool of choice for our support and product teams to explore all of our data in a flexible way. We leverage Clarity to monitor our Imply cluster, and it gives us all of the necessary insights into our production cluster, without the need for us to maintain a separate monitoring solution (such as Graphite).
Imply in production today
At the time of writing, we’ve migrated our entire analytics systems to be real-time. We ingest streaming data from AWS Kinesis into Imply at an average of 10 billion JSON events per day. When it comes to querying, our Imply cluster is serving around 100K requests per hour (at peak time). The average response time is around 600ms, with 98% of the queries being served in less than 450ms.
What’s next for GameAnalytics?
We have a custom query layer built in Elixir for Imply. We plan to expand how this query layer interacts with Imply and did open-source our work for Druid. You can find it here. We’re also investing time into more intelligent caching in our querying layer. This will help reduce response times for the most popular queries, remove pressure from our Imply cluster during peak hours, and improve the user experience. Finally, we just introduced A/B testing for our customers.
We’re very interested in further exploring the data sketches feature in Imply. The data sketch extension encompasses many approximate algorithms that are useful to measure user metrics, such as daily active users, user retention, and funnel analysis.
If you want to learn more about how we use Imply, you can watch our webinar.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...