How WalkMe uses Druid and Imply Cloud to Analyze Clickstreams and User Behavior
Apr 03, 2019
Yotam Spenser, WalkMe
This is a guest post from Yotam Spenser, Head of Data Engineering @ WalkMe
WalkMe is a Digital Adoption Platform (DAP) pioneer that offers a 360-degree solution to leading organizations worldwide. WalkMe helps employees and customers at some of the world’s largest companies engage and adopt digital products, and ensures organizations of all sizes can undergo smooth digital transformations.
WalkMe works as an embedded solution that integrates into any web, mobile, or desktop host application and works seamlessly from within to engage, support, or convert users based on their behavior (combined with predetermined rules).
A key element of any intelligent embedded application is that it must monitor its own effectiveness (ideally, as discreetly as possible). This means any tracking should remain effectively invisible, even as the embedded application undergoes rapid evolution.
A WalkMe step-by-step Walk-Thru in action.
Migrating from ElasticSearch to Druid
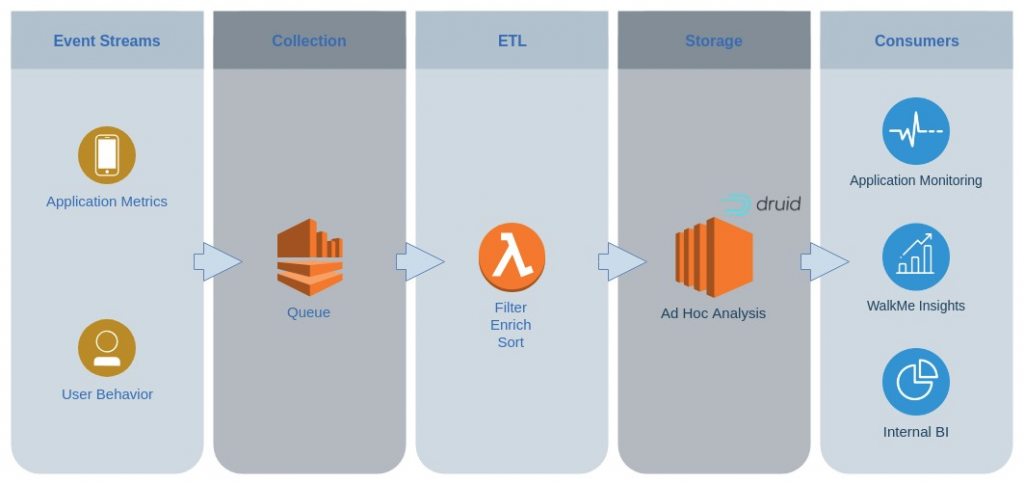
The legacy analytics system that was originally used to track core product usage was Elasticsearch (ES), which we initially leveraged as a simple log management system. We primarily used this system for one purpose: to troubleshoot specific problems in our embedded application (as opposed to monitoring broad trends across host applications).
While ES functioned well as a simple query system to troubleshoot errors in the embedded application, our requirements grew more sophisticated as our product matured. Over time, we started monitoring various aspects of the application’s performance and usage (e.g., length of operations on the client, accuracy of operations, etc.), and as the data grew in both volume and complexity, we realized an ES-based stack wasn’t optimal for real-time arithmetic operations over time-series data. Simply put, our queries were primarily ad-hoc analytic queries that grouped and filtered on several dimensions and aggregated several complex metrics. As our queries evolved from simple troubleshooting queries to ones that measured complex engagement stats, they became less and less well-suited to the search-focused architecture of ES.
Once we realized the legacy architecture was not well suited to behavioural analytics, and would not scale with our growth, we began searching for an alternative to transition our classic log search approach to a real-time OLAP one that scales linearly with our traffic. Druid met this criteria, so we started developing over the open source solution, testing specific use cases as well as load management in a cluster.
Productionalizing Druid
We quickly realized through our early evaluation with Druid that complex distributed systems such as Druid require significant devops and fine-tuning in order to achieve optimal performance and resiliency. Early on, we partnered with Imply, whose founders developed Druid, allowing us to focus on our business objectives, which included monitoring and creating analytics applications. Today, we run our entire Druid cluster on Imply.
High performance user analytics with Druid
Druid is now a big part of WalkMe’s internal and external analytics applications. Druid enables us to monitor performance across billions of client devices in real time. We can leverage Druid to compute any arbitrary metrics over any ad-hoc groups of users. We can track business critical measures such as retention and attrition, plus many other forms of engagement and usage metrics. As a result, we can now gain the type of insight we need to optimize and segment our code for different host platforms, applications, and websites, per their specific needs.
Run Powerful User Behavior Queries Interactively
There are some extremely powerful queries we can run with Druid, that would otherwise be impossible, to analyze the behavior of our users. For example, consider the following query:
SELECT ... FROM tbl WHERE userId IN (SELECT userId FROM tbl WHERE ...)
We issue many queries similar to this one where we first select a large group of users based on an ad-hoc set of criteria. We then further select a subset of these users and compute a wide range of metrics. For many traditional data warehouses, this can be a very expensive query. The first group of users may be in the millions, and to materialize and maintain such a list would be very expensive if we wanted the query to return interactively.
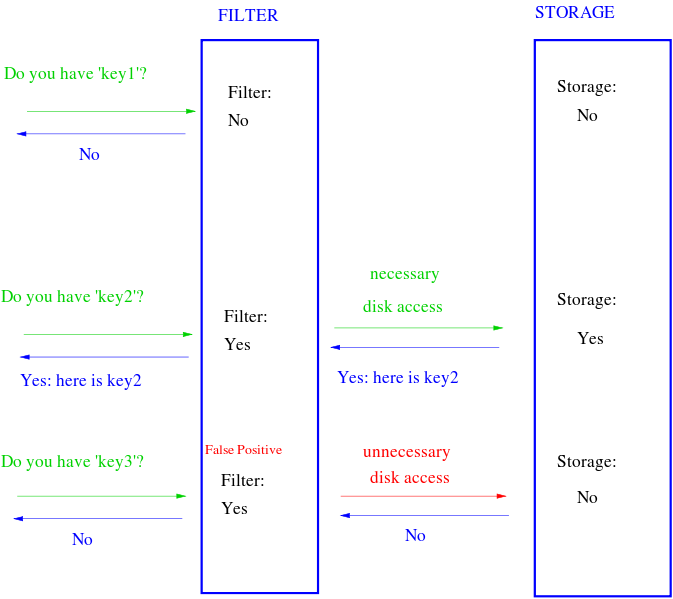
In contrast, Druid can leverage Bloom filters to return all results in a single query. This means that we don’t need to materialize the full set of users that match the first set of criteria. This is extremely powerful because it allows us to interactively engage with the data cost effectively, something we couldn’t do with ES. Although Bloom filters are approximate, we’ve found they have a high degree of accuracy and allow us to see all the important trends we need to follow. If we need 100% accuracy on a few key results, Druid also supports exact computations.
How Bloom filters work.
Conclusions
WalkMe is now using Druid as a part of our flagship customer-facing analytics product, WalkMe Insights, as well as internally for all of our monitoring purposes. If you have problems similar to ours around tracking users for digital products, we encourage you to evaluate Druid and Imply.
Other blogs you might find interesting
No records found...
May 07, 2025
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...