Introduction
Today analytics is everywhere—and it’s no longer solely for internal stakeholders. A personal finance portal may provide spending data to consumers, while a fitness app will help users understand and improve their fitness journey. On an organizational level, an aerospace manufacturer may provide performance and maintenance analytics to airlines, while a utility can provide usage and billing data to homeowners.
Clearly, companies are starting to see that external-facing analytics should be a core part of their business. But this customer-facing data has to be interactive and contextual to each user—after all, if they can’t quickly understand this information or explore it flexibly and in real time, they can’t derive value from it.
In addition, new analytics requirements also require completely new ways of thinking and building. Previously, the majority of analytics were for internal users, usually other engineers, data analysts, or data scientists on different teams within the same company. This means looser service-level agreements (SLAs) around query times and performance, higher data latency, and for the most part, lower concurrency due to a smaller user base (larger organizations being the exception). All of this equated to less pressure to rapidly deliver data, or to enable open-ended exploration.
On the surface, transitioning an in-house analytics platform into a product for paying customers may seem simple. After all, all the tooling and code is likely already there, and one may think that it’s only a matter of building a new UI to enable outside users to query data using SQL or other popular data tools.
In truth, if a company decides to expand into external analytics, they will face a completely new landscape. First, any external data product has to perform under load, regardless of how large a dataset may be or how many users are accessing analytics, because latent or incomplete queries are unacceptable. While internal stakeholders may be fine with leaving a report to compile over the course of a day, an outside user will likely be frustrated by such delays and consider switching to a competitor.
Another consideration is reliability. Not only will an outage affect a data product provider, but it will also impact their client organizations as well. For example, if a security platform goes down, its users (like banks or government institutions) will now be left vulnerable as well. As a result, many data products have stringent SLAs for availability and uptime, with downtime incurring monetary consequences (in addition to any customer dissatisfaction or churn).
Ultimately, data products-as-a-service are a completely different animal than internal analytics. Because revenue is tied directly to performance, the stakes are far higher than an application for in-house use.
External-facing data products: an overview
Today, these data products encompass a diverse array of analytics applications across many different fields. While customer-facing data products are unified by their functionality of providing data and analytics to external customers, they can be broadly classified into two groups. The first is a standalone application, such as a monitoring solution or a cybersecurity platform. These SaaS offerings are centered entirely around dissecting and leveraging data, and generally packaged and sold independently. Depending on their niche, they are often compatible with various data sources and environments.
The second category is embedded analytics, which could include the charts and graphs within a fitness tracker, a calendar widget charting time spent in meetings, recommendations for related products and services, or a tool for measuring reader behavior for a wiki. In contrast to standalone data products, this type is part of a larger solution, and can best be described as individual features.
Overall, data products for paying users may have several (or all) of the following capabilities:
Advanced analytics, such as aggregations, GROUP BY, segmentation, window functions, and other operations to extract insights from data. These functions facilitate detailed, granular queries, enabling teams to draw conclusions by indicators such as geographic area, time intervals, and more.
Simulations for modeling different scenarios based on data. This could take the form of a stock trading algorithm forecasting market prices over the next thirty days, or a navigational data product modeling upcoming wind speeds and trajectories for a tropical storm.
Dashboards populated with detailed graphics that can break down vital information in various ways, such as pie charts for percentage, maps for geographical regions, and heatmaps for user attention and activity. Ideally, these dashboards would be interactive, enabling users to zoom in, drill down, or drag and drop in real time.
APIs for integrating data directly into a customer’s website or tools, powering features such as personalization algorithms. For instance, when a user interacts with an application, they receive recommendations on anything from relevant products (for an ecommerce platform) to purchase to possible acquaintances (for a social networking site).
Customizable reporting that dissects results and insights in a variety of formats. Unlike dashboards, these reports can have varying levels of interactivity, but what is important is that users can tailor these graphics to represent the data that matters most to them.
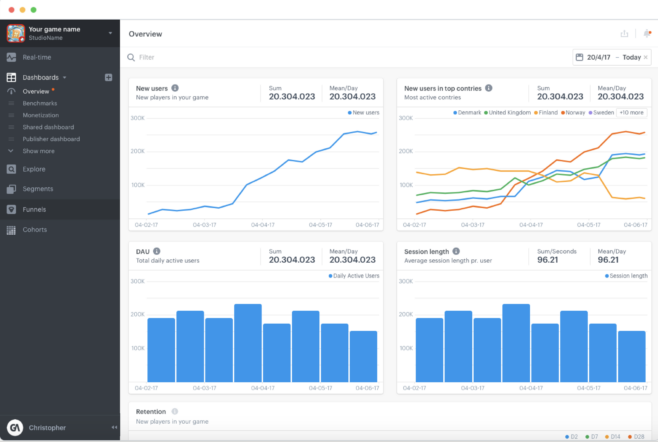
Figure 1: A sample dashboard from GameAnalytics, a prominent user of Apache Druid.
Collaboration and sharing. Customers should be able to annotate or comment on insights surfaced by analytics features. Similarly, they should be able to share widgets and graphics with their own clients through web browser links, embeddable graphics, or guest accounts. In some cases, customers (or their clients) may want to white label data and graphics with their own branding.
Alerting and automated workflows. In some use cases, a customer needs to be alerted on anomalies or to set triggers for automatic actions. For example, a cybersecurity platform will alert a bank’s fraud prevention team when it detects anomalous credit card activity, while facility operations teams may configure a smart asset management tool to activate climate control when temperatures exceed or drop below specific thresholds.
Building for scale: challenges and opportunities
Because these data products are for external customers, performance measures such as service-level agreements (SLAs) and user satisfaction are of the utmost importance. For consumers (such as a digital marketing team or a SRE department), data products provide important insights that are inherently important to operational efficiency, high performance, and ultimately, profitability.
Without timely access, data products for external customers are perhaps less valuable than they could be. Lacking the real-time element, data product users are forced to adopt a reactive stance, which may be undesirable in some situations. For instance, a bank can’t preemptively stop fraudulent credit card transactions, and has to issue chargebacks after the event occurs, thus hurting the merchant, inconveniencing the credit card holder, and damaging their brand credibility.
Further, this success criteria becomes much harder to fulfill whenever scale is involved—whether it’s data volume, query traffic, or user numbers. In fact, a high rate of queries is particularly tricky, as it can lead to issues such as coordinating multiple parallel query operations, expensive increases in resource usage (particularly if a data product utilizes vertical scaling), and additional overhead for data teams. Ultimately, scale impacts end users, leading to latency, a poor user experience, and in the worst case scenario, loss of revenue from customer churn.
Here are the requirements for any database intended to power an external analytics product.
Scalable and affordable.
Scalability has to be achieved in a cost effective manner. While adding hardware is the easy way to scale a database, it is also expensive—and thus not an option for every organization. Therefore, a database should scale horizontally through sharding or partitioning (a more complex but cheaper approach), but also do so in an intuitive manner—no small task.
Performant under load.
When data streams, user numbers, and query rates spike, data products still have to maintain rapid responses to ensure that end users can access data in real time. Any latency means that dashboards and other tools are no longer interactive, which may lead to customer frustration. As an example, a cybersecurity analyst using a data product to investigate a possible intrusion needs answers quickly, or else they risk allowing in a malicious hacker or delaying critical business transactions.
In fact, heavy traffic and large volumes of queries are inevitable, either during periods of rapid growth or amidst crises. Whatever the case may be, a data product has to consistently perform under load, as customers themselves have revenue, SLAs, or other matters at stake.
One example could be shopping seasons such as Single’s Day in Asia or Black Friday in North America, or games like the Super Bowl or World Cup. In the weeks and months leading up to these events, marketers and advertisers may be intensely busy buying and personalizing ads, running targeted campaigns, segmenting audiences, and much more.
During this time, many members of teams would log onto their marketing platforms to iterate campaigns so that they can meet various metrics, such as conversions, clickthrough rates, and more. It’s very likely that marketing analytics solutions will encounter heavy traffic as marketers, executives, and clients all log on to view the successes (or failures) of their initiatives, and review what could be changed or improved.
Reliable and durable
Resilience and high availability is a core requirement, given the increasingly global nature of commerce today, as well as the high stakes inherent in some fields, such as cybersecurity or banking. Durability is another important requirement—in sectors that require continuity of data for safety or compliance reasons, such as healthcare or finance, data loss can have serious, even life-threatening consequences.
For all organizations, downtime (both planned and otherwise) is a problem. A data product whose database cannot keep pace with the demands required to run analytics, respond to queries promptly, and accommodate user traffic will have negative impacts on provider revenue. This is especially the case when the data product is a core company offering, and something on which the company stakes their reputation.
Stream compatible
Streaming remains the most efficient way to ingest data in real time, and to analyze and act upon time-sensitive data and insights. By relying on data streams as their primary ingestion, organizations can effectively fulfill use cases that depend very heavily on highly perishable data, such as observability, personalization, cybersecurity, and more.
Easy to use
Automation and simplification are critical for any database upon which a data product is built, as the less human intervention required, the more time that teams have to focus on building or improving their data product.
Future proof
Often, a team will prototype and build a commercially viable data product using one database—only to find that this database, which could handle the limited user traffic and query activity of the data product’s early days, will struggle to keep up with growth in customers, queries, and data. These databases tend to be limited by design, such as PostgreSQL, which features a single node architecture, presenting liabilities for scaling and resilience.
By adopting a scalable, distributed database like Apache Druid from the beginning, teams can lay a foundation for future success, ensuring that their database (and the data product) will be able to keep up with customer growth. Equally important, using the right database from the beginning will remove the need for costly, time-consuming migrations and any associated impacts, including time spent onboarding team members or planned downtime.
Ultimately, the fact of the matter is that creating an external, customer-facing data product for scale–whether it takes the form of queries, data volumes, user traffic, or all of the above—is a completely different beast than building analytics for internal use. Not only is there a greater complexity involved, but there are also much higher stakes associated with paying users.
Why Apache Druid for external data products?
Apache Druid is the database built for speed, scale, and streaming data. Not only was Druid created specifically to overcome the challenges of massive datasets, but it was also created to provide reliability, scalability, and availability—an ideal match for companies building data products for outside consumption.
One key feature is Druid’s subsecond query responses for virtually any size data set—a vital advantage for data products, which are often tasked with tracking real-time trends or providing data instantaneously to users. While some databases, including cloud data warehouses such as Snowflake or Databricks, can store and query vast volumes of data, they may not necessarily be able to return results as rapidly as Druid.
To achieve this, Druid uses parallel processing via scatter/gather. Queries are split up and routed to the data nodes that store the relevant segments (scatter), scanning data simultaneously before being pieced back together by broker nodes (gather). For the most performance-sensitive queries, Druid also preloads data into local caches to avoid having to load data for each query.
Druid can scale elastically and seamlessly. Relational databases like MySQL or PostgreSQL are ill suited for the complexities of horizontal scaling approaches such as sharding or partitioning, both of which may cause issues with critical operations such as JOINs. Other databases, such as MongoDB, may struggle to provide analytics on massive datasets.
In contrast, Druid’s architecture is inherently scalable. By design, Druid separates tasks by different node types: data nodes for ingestion and storage, query nodes for executing queries and retrieving results, and master nodes for handling metadata and coordination. Each of these can be scaled up or down depending on demand. To facilitate scaling up or down, Druid can also pull data from deep storage and rebalance it across servers as they are added or removed.
Deep storage (which can take the form of either Hadoop or cloud object storage like Amazon S3) also provides an extra layer of durability. Data is continuously (and automatically) copied into deep storage. When nodes are lost due to errors, outages, or failures, the data stored on the lost node is automatically retrieved from deep storage and loaded onto other, surviving nodes. Druid also does not require any planned downtime for upgrades or maintenance, so that data is always available.
Druid is also uniquely suited to the challenges of real-time, streaming data. Because it is natively compatible with Amazon Kinesis and Apache Kafka, the two most common streaming platforms today, Druid can ingest data without any additional workarounds or connectors. Data is also ingested only once, so that events are not duplicated, but are also instantly made available for queries and analytics.
Finally, Druid provides schema autodiscovery to remove manual maintenance. Rather than defining and maintaining rigid database schema (this includes updating schema to match any changes in data sources), Druid can automatically adjust to changes, modifying fields as needed. For Druid users, schema autodiscovery can also provide the best of both worlds: the performance and organization of a strongly-typed database with the flexibility of a schemaless data structure—simplifying both data ingestion and database upkeep.
Customer story: Nielsen Media
Founded in 1923, Nielsen was one of the first companies to provide quantifiable sales and marketing data, pioneering such concepts as market share. Today, Nielsen Media is one of the largest market data firms worldwide, providing audience analytics and data for studios and broadcasters in over 100 countries. In 2021, Nielsen employed 44,000 people and earned $3.5 billion in revenue.
Nielsen’s Marketing Cloud solution provides advertisers and marketers with important performance data, including segmentation, consumption, demographics, and more, across every phase of a campaign or a brand journey.
At first, Nielsen Media used Elasticsearch to power Marketing Cloud, storing, querying, and organizing the raw data. However, as Marketing Cloud started ingesting data at a massive scale—up to 10 billion devices as of 2019—Elasticsearch revealed its limitations.
One example was sampling. Each day, Nielsen’s Big Data Group would sample their data, ingesting about 250 GB from their entire daily intake (which ran into the terabytes) into Elasticsearch. However, indexing this amount of data took almost 10 hours, and significantly slowed down queries—to the point where some would fail to complete.
As the number of concurrent queries increased, so too did the response time: by the time the Nielsen environment processed 120 queries per second, average retrieval times were up to two seconds long. When compounded across many different widgets on various dashboards, this delay made it impossible to provide an interactive end user experience.
There were several reasons for this poor performance. First, the same Elasticsearch nodes used for ingesting the data were also used for querying the data, adding to the load and slowing down clients even further. Also, due to the way that data was structured, queries had to scan every single shard on the corresponding index in order to retrieve data.
After transitioning to Druid, Nielsen’s new data pipeline ingests dozens of terabytes of data. By using features like rollup, Nielsen’s teams can compact a year’s worth of data into about 40 terabytes (with an interval of one day), preserving an acceptable granularity for end users while reducing resource usage.
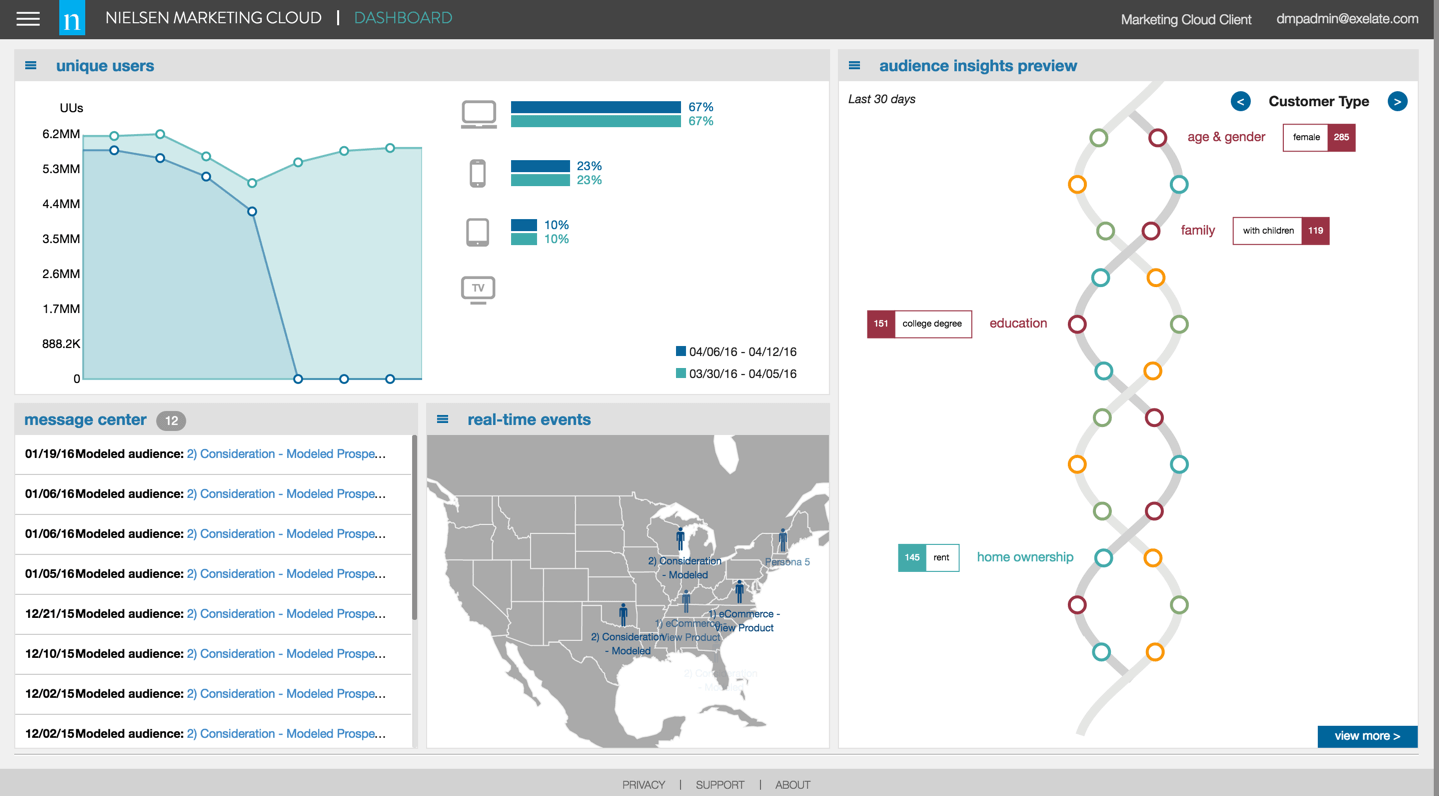
Figure 2. An example of a Nielsen Marketing Cloud dashboard, courtesy of MarTech.
Another helpful capability is the ThetaSketch. In order to discover different intersections of attributes, such as all female customers who use mobile phones and are interested in technology, ThetaSketch can combine these different characteristics in an approximation of COUNT DISTINCT and rapidly surface the results. Customers can quickly build a Boolean formula on Marketing Cloud’s web application, which will then execute the required queries on the backend in milliseconds.
In particular, ThetaSketches are very helpful for highly specific segmentation and targeting—for both media buyers, who are purchasing ad space from studios and creators, and sellers, such as streaming platforms, broadcast channels, or content creators. As an example, a podcast studio (whose portfolio includes multiple shows and podcasts) could use Marketing Cloud to analyze audience data, build different intersections with ThetaSketches, and more effectively market ad space to buyers.
In doing so, this company might find that the audience of an unsolved mysteries podcast may consist of women with high school degrees (60%) with the majority of those (70%) being older listeners. In contrast, they might discover that the fanbase of an aviation podcast could consist of young men and women aged 18-29. With these intersections in mind, the podcast service can more precisely target ads: given the young age of the aviation podcast’s fandom, it is a safe assumption that some listeners are curious about career changes—and thus, this podcast could be an ideal channel for flight colleges or mechanic schools.
The process is similar for a media buyer that wants to buy ad space. For instance, a cruise line’s marketing department might run ThetaSketches on their traveler base and discover that a high percentage of their trips are purchased by women aged 45-60 years—either individually or in groups, such as couples or friends. As a result, they decide to buy ads for various channels, including the true crime podcast, whose followings match these demographics.
Itai Yaffe, then Nielsen’s Tech Lead for their Big Data Group, explains it best. “When Elasticsearch could no longer meet our requirements, we switched to Druid. The proof of concept was great in terms of scalability, concurrent queries, performance, and cost. We went with Druid and never looked back.”
To learn more about Nielsen Media’s Druid journey, read Yaffe’s blog post or watch his video presentation.
Customer story: GameAnalytics
Founded in 2011, GameAnalytics was the first purpose-built analytics provider for the gaming industry, designed to be compatible with all major game engines and operating systems. Today, it now collects data and provides insights from over 100,000 games played by 1.75 billion people, totaling 24 billion sessions (on average) every month. Each day, GameAnalytics ingests and processes data from 100 million users.
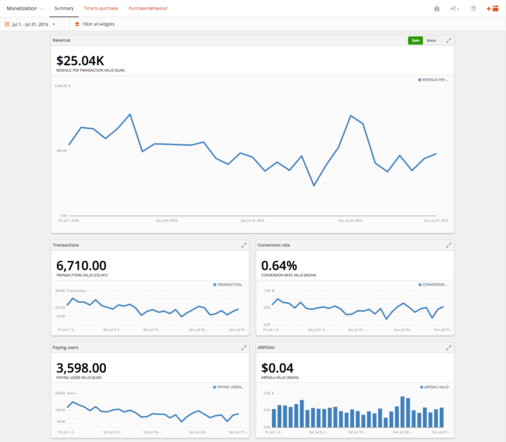
Figure 3: A GameAnalytics dashboard
Prior to switching to Druid, GameAnalytics (GA) utilized a wide variety of products in their data architecture. Data, in the form of JSON events, was delivered to and stored in Amazon S3 buckets before being enriched and annotated for easier processing. For analytics, the GA team utilized an in-house system built on Erlang and OTP for real-time queries, while relying on Amazon DynamoDB for historical queries. Lastly, they created a framework (similar to MapReduce) for computing real-time queries on hot data, or any events generated over the last 24 hours, while also creating and storing pre-computed results in DynamoDB.
While this solution was very effective at first, stability, reliability, and performance challenges arose as GA scaled. “We also quickly realized that although key/value stores such as DynamoDB are very good at fast inserts and fast retrievals, they are very limited in their capability to do ad-hoc analysis as data complexity grows,” CTO Ramon Lastres Guerrero explained.
In addition, pre-computing results for faster queries also created some issues. After all, more attributes and dimensions led to larger query set sizes, and past a certain point, it was impossible to pre-compute and store every possible combination of queries and results. Therefore, “we limited users to be able to only filter on a single attribute/dimension in their queries,” Guerrero explains, “but this became increasingly annoying for our clients as they could not do any ad-hoc analysis on their data.”
This ad-hoc analysis is crucial to game design, especially where it comes to iterating and improving games based on audience feedback. Without the ability to explore their data flexibly, teams can miss out on insights, forfeiting opportunities to optimize gameplay, improve the player experience, and in the worst-case scenario, even lose players to more responsive competitors.
Druid helped resolve many of these problems. Because it was built to power versatile, open-ended data exploration, Druid did not require pre-computing or pre-processing for faster query results. Instead, Druid’s unique design, which could act on encoded compressed data, avoid the need to move data from disk to memory to CPU, and support multi-dimensional filtering, enabled rapid data retrieval—and powered the interactive dashboards so important to GA customers.
In addition, Druid’s separation of ingestion and queries into separate nodes, rather than lumping various functions together into a single server, also provided extra flexibility in scaling and improved resilience. “It allows more fine-grained sizing of the cluster,” backend lead Andras Horvath explains, while the “deep store is kept safe and reprocessing data is relatively easy, without disturbing the rest of the DB.”
Druid also provided ancillary benefits as well. First, it was a single database that unified real-time and historical data analysis, helping GA avoid a siloed data infrastructure. Further, Druid also was compatible with a wide range of GA’s preferred AWS tools, including S3, Kinesis, and EMR. Lastly, Druid’s native streaming support helped GA convert their analytics infrastructure to wholly real-time.
After switching to Druid, the GA environment ingests 57 million events daily, improving performance by 17 percent and reducing engineering hours by 20 percent. To learn more, read this guest blog by CTO Ramon Lastres Guerrero, or watch this video presentation.
Customer story: Innowatts
Founded in 2013, Innowatts provides AI-powered analytics for power plants, utilities, retailers, and grid operators, who collectively serve over 45 million customers globally. Headquartered in Houston, Texas, Innowatts counts major power companies as its customers, including Consolidated Edison and Pacific Gas and Electric.
Because power demand is elastic, ebbing and flowing based on time of day, weather conditions, and even holidays or weekends, it can be difficult for utilities and power plants to anticipate usage. Further, bulk energy storage solutions are not yet reliable enough to ensure a steady, uninterrupted supply of power—which necessitates the balancing of supply and demand across various sources, plants, and transformers.

Figure 4. A sample Innowatts dashboard, designed by Asif Kabani.
This is where Innowatts comes in. Built around customer-facing analytics, Innowatts empowers utilities to rightsize resources to match demand. Utility analysts use Innowatts to analyze consumption, build machine learning models to forecast energy requirements, and inform their bidding for additional power to fill any gaps in generation.
At first, Innowatts used several solutions in their data environment. Data from smart meters would be submitted to Innowatts either directly or through a third-party integration, where it would then be uploaded into Amazon S3 buckets for engineers to create Amazon Athena tables atop the data. Lastly, the data would be pre-aggregated in Apache Spark, exported into MongoDB for analytics, and finally, displayed for analyst customers in a custom UI.
As Innowatts grew, doubling its data ingestion from 40 million to 70 million smart meters, however, this data architecture encountered some challenges. Not only was it incapable of scaling, it also could not handle the high concurrency, as more analysts ran more parallel queries within a very limited window of time. In addition, Innowatts could not provide granular, meter-level data to their analyst customers, nor could they support open-ended data exploration by dimensions such as geography or zip code—a feature often requested by customers.
Latency would make data impossible to use. As software engineer Daniel Hernandez explained, “We go off this notion that if the client has it and it’s not fast, then it might as well be broken, because they need to be able to create insights really quickly off of that data.”
By transitioning to Apache Druid, the Innowatts team was able to achieve several milestones. They simplified their data architecture, removing Apache Spark and instead ingesting smart meter data directly into Druid. Their engineers were also able to streamline or automate their workflows, cutting out time-consuming tasks such as constant schema changes and updates. As an example, because Druid could automatically detect new columns, it automatically removed the bottleneck of having to configure a new model for a client.
Most importantly, utility analysts could now enjoy interactive dashboards with detailed visualizations and ad hoc aggregations, enabling operations like zooming in, drilling down, dragging and dropping, and much more. This versatility enabled clients to study their data through a variety of perspectives—and some unexpected ways.
One interesting approach was competitive forecasting. In essence, utilities would use different models or aggregation types to create a variety of predictive models, gauging them for accuracy and selecting the one which most consistently provided the most precise results. “Druid allows clients to be able to do all these competitions really, really fast,” engineer Daniel Hernandez explains, thus enabling utilities to better pinpoint customer trends, predict usage, purchase extra power, and match resources to consumption accordingly.
Innowatts engineers were also able to tailor aggregations in unique ways, even creating a filter to break down event data by specific days while excluding anomalies like weekends or hours with missing data. This enabled a greater degree of customization to better address client needs: for instance, a Texas-based utility will have different holidays or peak periods than a New York-based one, and so each customer can create different filters for their own specific situation.
Ultimately, Innowatts was able to reduce operational costs by $4 million, improve forecast accuracy by 40 percent, and enhance the lifetime value of customers by $3,000.
Customer story: Orb
Orb is a billing engine for companies with modern pricing plans and business models. By using Orb, companies can introduce transparency into the billing process, fine-tune their price strategies, include real-time data in invoices, and remove errors in revenue reporting. Customers span a range of industries, such as infrastructure, developer tooling, fintech, SaaS, and AI.
The Orb environment is straightforward. Customers send usage events in a schemaless format and then set up metrics on top of these events. Finally, Orb ties metrics to pricing and uses this data to generate invoices.
The Orb team had several requirements for any potential database—it had to be mature, stable, and include built-in compatibility for SQL, a language which developers and clients alike were familiar with. For that reason, the Orb team originally built their product with PostgreSQL, which was very effective for a while, as it supported SQL, JSON B columns, and the execution of queries on top of schemaless data.
Figure 5. A sample Orb dashboard.
However, as their customer base (and data volumes) grew, PostgreSQL encountered scaling issues, and couldn’t keep pace with ingestion and queries.
“It was primarily scale,” Kshitij Grover, cofounder and CTO of Orb, explains. “In order to actually be able to issue invoices over really large event sets, we needed to give people access [within] a reasonable time frame…we just couldn’t fulfill our core service contract of issuing millions of invoices every month without having a more performant solution.
“We also needed a datastore that specialized in time series data and was built for aggregations,” Grover continues. Given that PostgreSQL was created as a general-purpose database, it wasn’t necessarily optimized for Orb’s needs—and was not a suitable, long-term solution for continued growth.
“In terms of the [replacement] options we explored…Snowflake can handle lots of data, and was obviously a very flexible system,” Grover explains, though he quickly realized that it was not an exact fit for their needs. Because Snowflake wasn’t intended for real-time analytics, operating Snowflake would require Grover and his team to introduce a two-tier architecture.
“We’d have to build some set of queries that access a different database, and then [another] set of queries that access Snowflake, pre-compute that data, and cache it in a different layer,” Grover explains. “It would have been a lot of engineering complexity, [when we] just wanted to focus on the billing, finance, and reporting side, rather than spending all of our time architecting [a] database.”
Orb also explored other options, such as Clickhouse and Apache Pinot. Still, as Grover says, “I think we were pretty quickly excited about Druid for a couple of different reasons…we knew that correctness and database resilience matter a lot for…our domain and service.”
In particular, Grover and his team liked how Druid included native support for Apache Kafka, thus ensuring exactly-once ingestion for streaming data—and removing the possibility of duplicates. Other databases would require the addition of an external Kafka connector or other third-party workaround, which would require more overhead from Orb’s engineering team.
Other considerations included scaling and support. When they evaluated Clickhouse, Grover explained that his team found that “scaling out a cluster in Clickhouse is a little more painful than Druid…there [also] wasn’t a “very mature managed service around Clickhouse, and we saw that Imply had been working with Druid for a long time…and so we were excited about working with a really experienced team.”
Similarly, Druid’s scalability also enabled stress testing, which helped reassure Orb’s current customers—and perhaps even attract new ones.
“One of the things people want to know about billing vendors is that—as usage grows, are they going to be able to rely on us for critical infrastructure?” Grover explains. “Because we can scale Druid up pretty easily, we can say, ‘Hey if you’re a big company and you want to do this large stress test, we can provision an appropriate cluster for you as your usage grows.’ That talk track has been really positive, and people can understand that.
“Imply also has a lot of great resources around observability into the Druid cluster that you don’t get out of the box,” Grover adds. “The more observability we have, the better we can tailor our cluster to our use case.”
One helpful tool was Imply Clarity for monitoring and analyzing Druid operations. Grover explains that Clarity has “been really useful to understand what exactly is our query pattern? How can we make sure that the sort of queries we’re running on Druid are performant and we’re not missing anything about the initial setup?”
They were also able to get assistance from the Imply team on optimizing this workload and tuning clusters based on requests—an example of how the right visibility and support empower teams to improve Druid performance. In fact, Grover estimates that working with Imply support has saved Orb’s engineers around 20-30 hours per month, time that can be spent on other tasks.
Another benefit is versatility. Recently, the Orb team began using Druid with Imply for tasks that are downstream of invoicing (their original use case), specifically financial reporting, accounting, and revenue recognition. This shift was driven by customer finance teams, who needed the flexibility to group, pivot, and filter by various criteria and metrics.
Druid with Imply also included built-in compatibility with SQL, the Orb team’s preferred query language. “Because Druid supports SQL, it’s been really easy for us to inspect and debug issues,” Grover points out. As a result, the Orb team avoided learning yet another query language, which also shortened the learning curve and enabled them to start using Druid with Imply right away.
Today, Orb has only continued its explosive growth. “Our event volume probably doubles or
triples every few months,” Grover explains. “We also have individual customers doing anywhere from hundreds of thousands to millions of events per second.”
Lastly, Grover adds, “The sorts of things we are looking for are very aligned with what Druid and Imply are building towards. And I think that’s nice because it makes us feel like we’re in the right place, we have the right use case, we’re using the product that’s directionally designed for the sorts of problems we’re trying to solve.”
To learn more about Orb’s journey with Apache Druid, check out this episode of the Tales at Scale podcast, or this presentation from Druid Summit 2023.
Apache Druid: the database for customer-facing data products
Built for scale, speed, and streaming data, Apache Druid is ideal for data products that provide external analytics to paying customers. Druid will provide subsecond response times even amidst the most challenging conditions—such as massive flows of data (anywhere from hundreds of thousands to millions of events per hour), vast datasets (from terabytes to petabytes), high rates of queries per second, and heavy user traffic.
Alongside its open source software, Imply (founded by the original inventors of Apache Druid) also offers paid products including Polaris, the Druid database-as-a-service—and the easiest way to get started with Druid. Another popular product is Pivot, an intuitive GUI for creating rich, interactive visualizations and dashboards—an important pillar of external-facing data products and a key generator of revenue.
To learn more about Druid, read our architecture guide. For more information on how Druid can power your data product, check out our dedicated use case page.
For the easiest way to get started with real-time analytics, start a free trial of Polaris, the fully managed, Druid database-as-a-service by Imply.