I. Introduction
Lately we have noticed a surge in demand for GCP amongst enterprises. The volume of data moving to the cloud is growing, and part of that data is of very high value, with analysts and operators requiring lightning fast access in order for the business to identify and act on important trends. New technologies that enable low-latency queries at scale in the cloud will need to be adopted. One of them is Apache Druid (incubating).
Druid is a distributed, realtime database that is designed to deliver sub-second query response on batch and streaming data at petabyte scale. On top of Druid, Imply provides an interactive query-and-visualize UI so non-technical business operators can iteratively explore the data and quickly discover opportunities for improvement.
Imply was founded by the authors of Druid and delivers an enterprise-ready Druid solution – including visualization, management and security – to customers across the globe. Imply enables enterprises to operate on-prem or via their cloud platform of choice, including GCP.
To help you get to know GCP and Druid, the tutorial below will walk you through how to install and configure Druid to work with Dataproc (GCP’s managed Hadoop offering) for Hadoop Indexing. Then it will show you how to ingest and query data as well.
Hadoop Indexing using Druid is an important use case since the majority of enterprises today have Hadoop deployments but Hadoop does not natively support indexing or low-latency real-time queries.
Prerequisites
There are several key requirements that need to be completed before Imply and Dataproc are deployed.
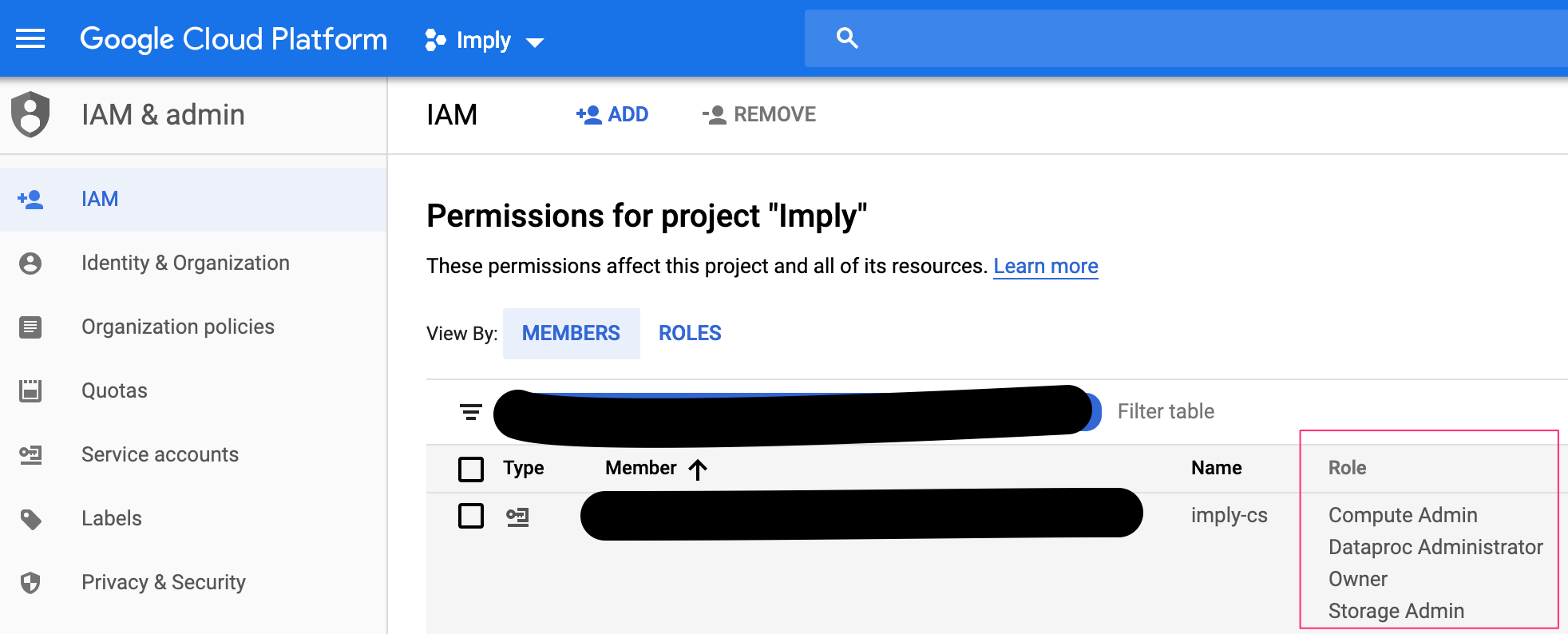
Service Account
The service account that will be deploying GCP vms for Imply and Dataproc environment must have the following roles set up.
- Compute Admin
- Dataproc Administrator
- Owner
- Storage Admin
Here’s a sample entry from the GCP IAM page.
When creating the GCP compute vms, make sure to choose the service account you are provisioning with the proper roles and that the Cloud API access scopes is set to “Allow full access to all Cloud APIs”. Do not use the default GCE service account.
Network & Firewall
Ensure that the vms provisioned for Imply and Dataproc are visible to one another. It is recommended that you put Dataproc in its own subnet. A high speed network is ideal. For large, batch ingest in the double-digit TB range or larger, it is best to have 100G of bandwidth, specially for time-sensitive processing. For time-insensitive ingest, between 10G to 40G is sufficient.
The only thing to consider for the firewall is to make sure that you are providing IP ranges for each rule along with its ports/range of ports. The default rules are sufficient but something specific needs to be setup, specifically for Pivot. As shown below, all except for “pivot-2” rule are defaults. The IPs that would need access to Pivot (port 9095), Coordinator (8081), Overlord (8090), and Broker (8082) need to be defined. The term “Ingress” is equivalent to “Inbound” and “Egress” is the same as “Outbound”.
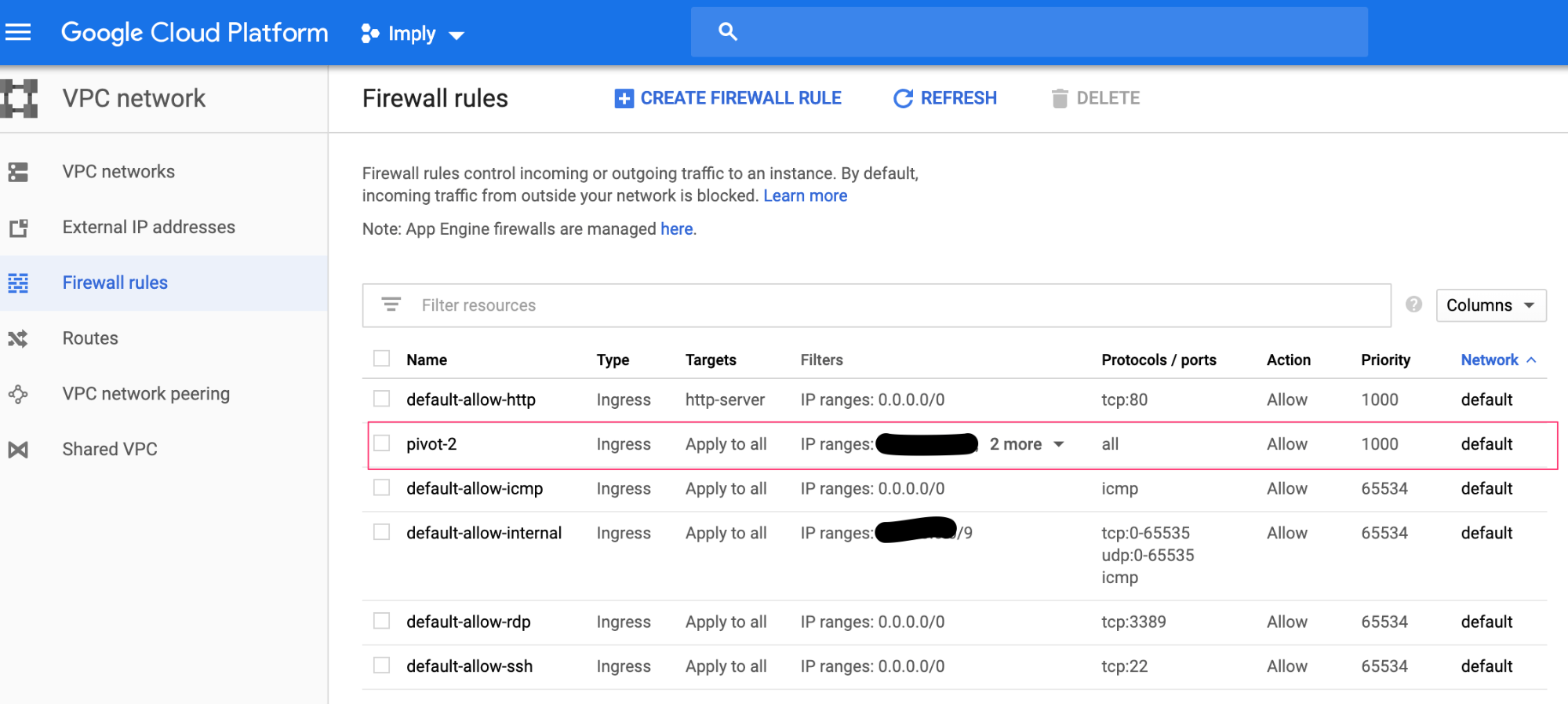
Also make sure to allow HTTP traffic.
Google Cloud Storage
Login to your GCP account and validate that you can create folders, upload files, and delete files in your assigned bucket.
Google Cloud SDK
You can download the Google Cloud SDK here. There are two tools from this SDK that you will be using on a regular basis – gcloud and gsutil. Install the SDK and follow the instructions for initializing it. It will eventually ask you to authenticate yourself with your gmail account.
There are several options to login to the vms for Imply and Dataproc. You can check all the options here but often it is easier to use the OS Login as this doesn’t require managing ssh keys. Before deploying vms, make sure to update your Metadata key/value pair as shown below. The key is “enable-oslogin” and value is “TRUE”. This is at the project level. So if you have multiple projects and you want to use OS Login option, make sure to go to each project and enter the same information. If you do have vms already deployed prior to enabling OS Login metadata update, you can go and edit the vm configuration under “Custom metadata” and enter the same key/value pair. It’s not necessary to restart the vm as this change will take effect immediately.
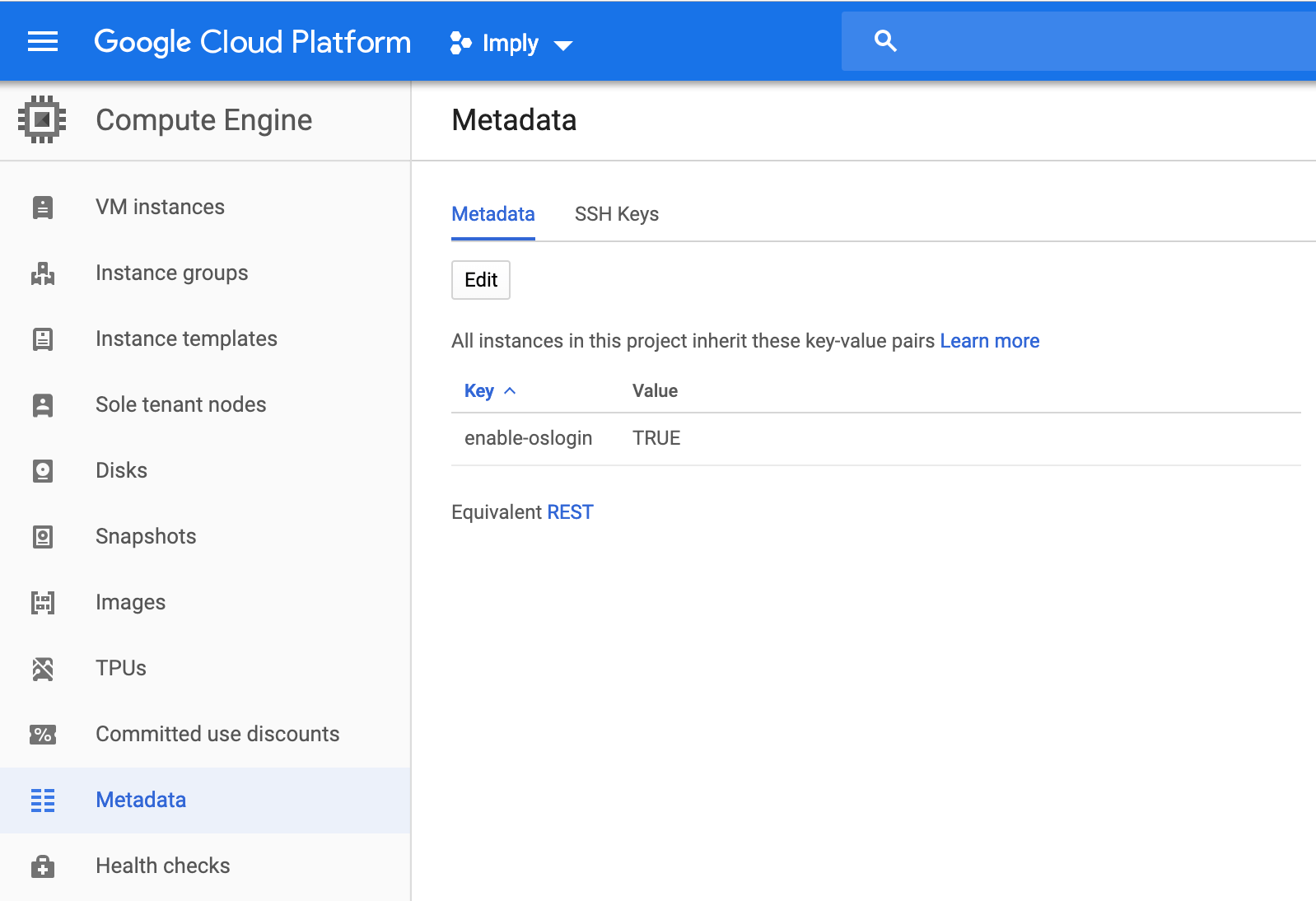
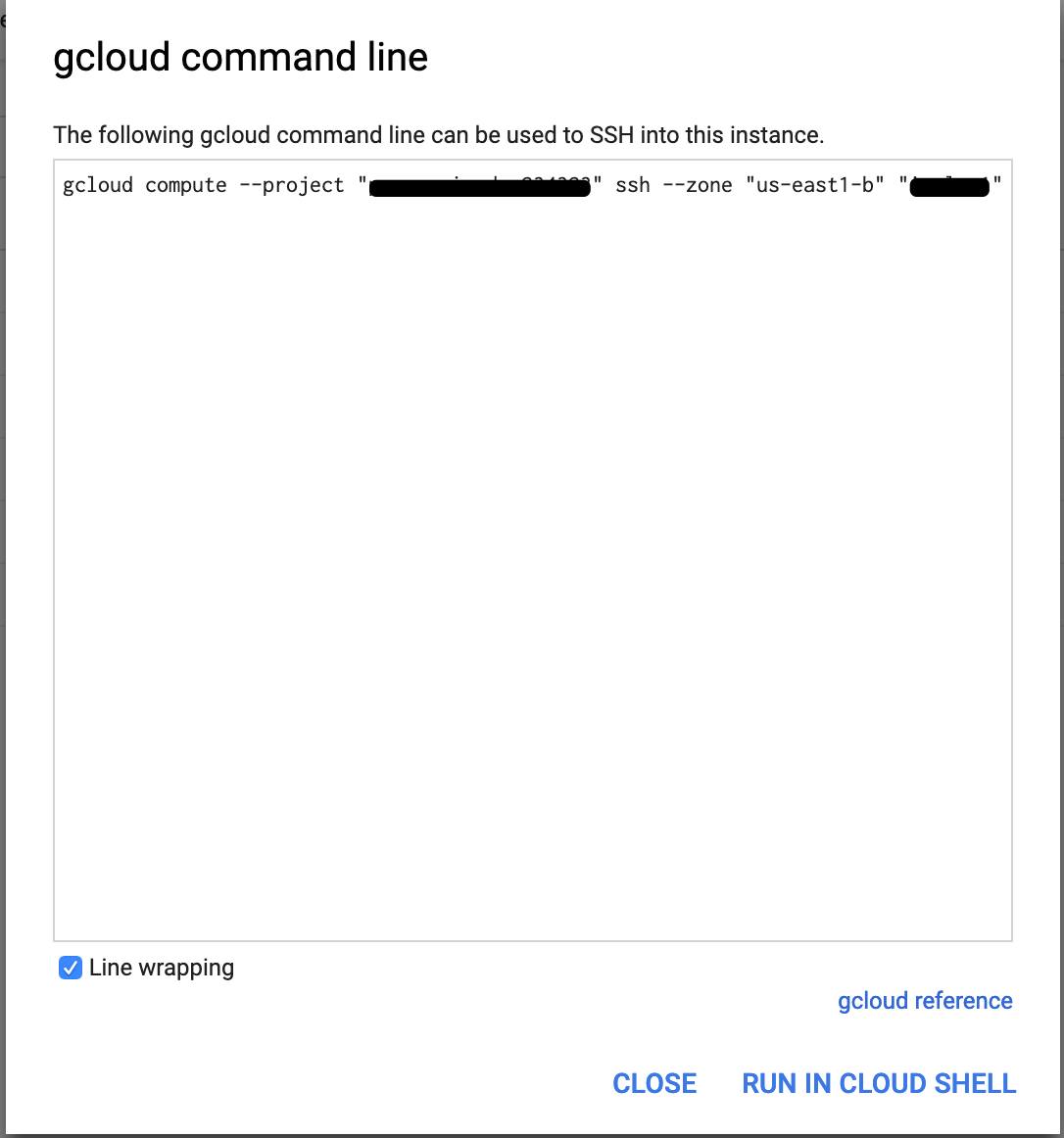
Here are the two steps to login into your vms:
- Go to your vm and click on SSH drop down.
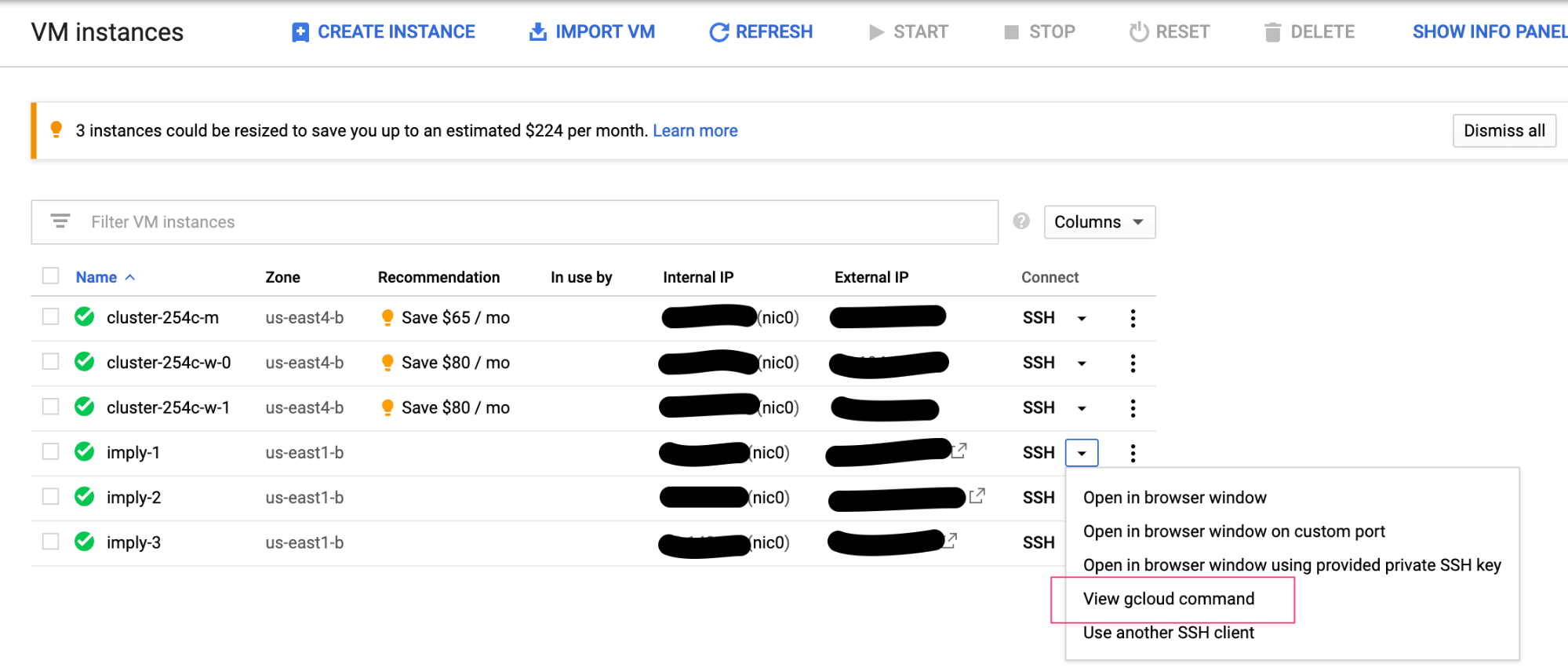
- Choose “View gcloud command” and copy the command and run it from your host terminal.
II. Imply Installation
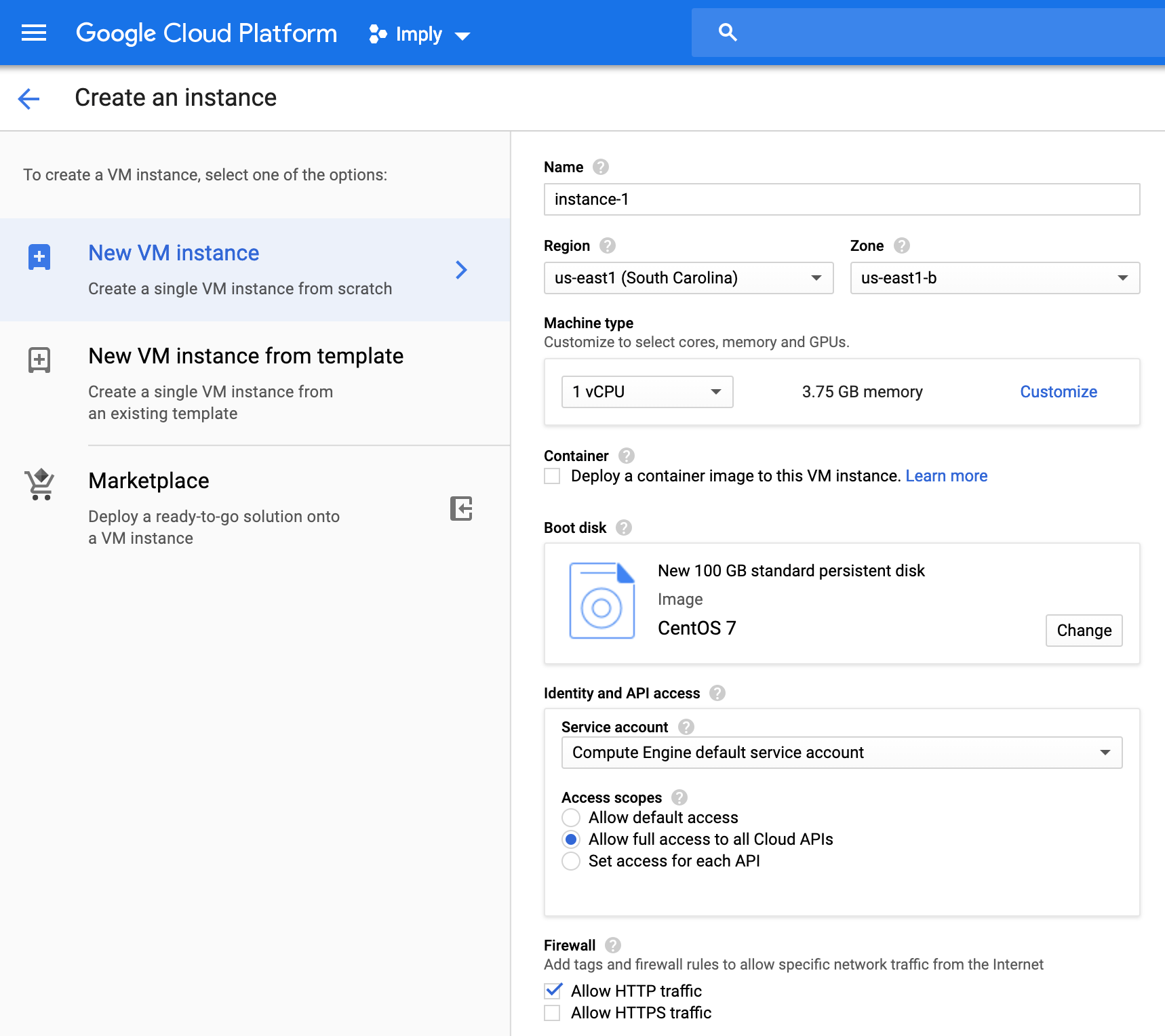
Create your vms with the proper configuration that will meet your use case. GCP provides you the ability to expand the memory up to 624GB per vm. A sample setup is shown below.
Before installing Imply, make sure that the vms can read/write from/to your GCS bucket. You can use the sample command format below. Most of the commands from here on out will require “sudo” level access.
To write to a bucket:
sudo gsutil cp /path_to_file gs://some_bucket
To read data from a bucket:
sudo gsutil cp gs://some_bucket /path_to_file_directory
If both commands are successful, your vms have correct access to your buckets.
At this point, you can now install Imply. Use the latest version available here. Update all the necessary Druid configuration files.
III. Dataproc Installation
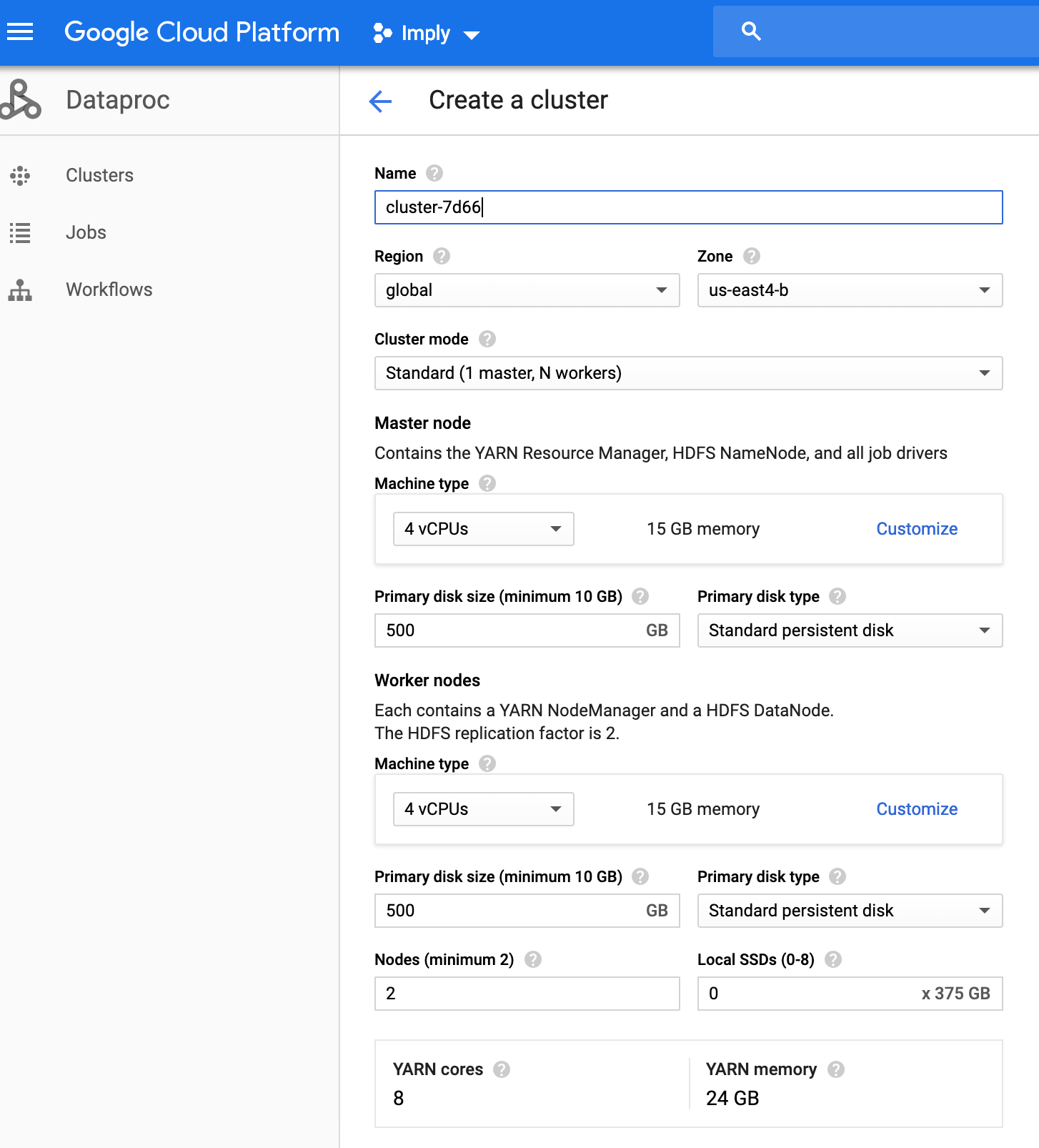
Make sure to deploy Dataproc in the same GCP region as Imply. Choose the right number of CPUs and sufficient memory to meet the SLA for hadoop ingest into Druid. One thing to note is that the “Local SSDs (0-8)” field is for storing temporary/staging data when Hadoop jobs are running. Choose the appropriate number of disk for the use case.
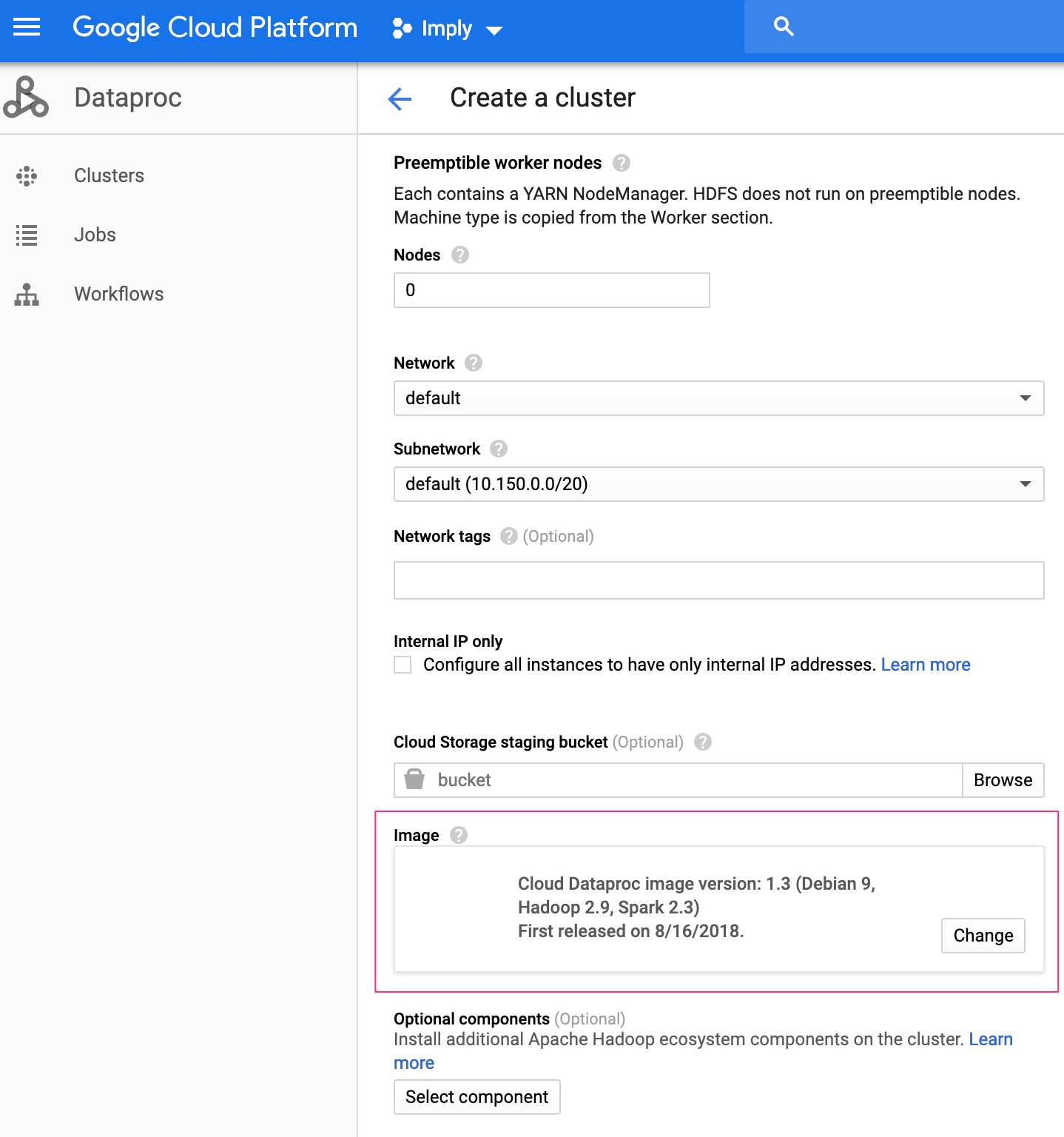
The Advanced section below highlights Dataproc version 1.3. This version (or greater) is what is needed as it ships with druid-google-extensions and the gcs-connector-hadoop that is compatible with Imply 2.8.x and above.
You can leave the defaults in the last section. If you do have to automate the configuration after you install the cluster, you can define your initialization scripts stored in the GCS bucket and they will be executed upon completion of the vm provisioning.
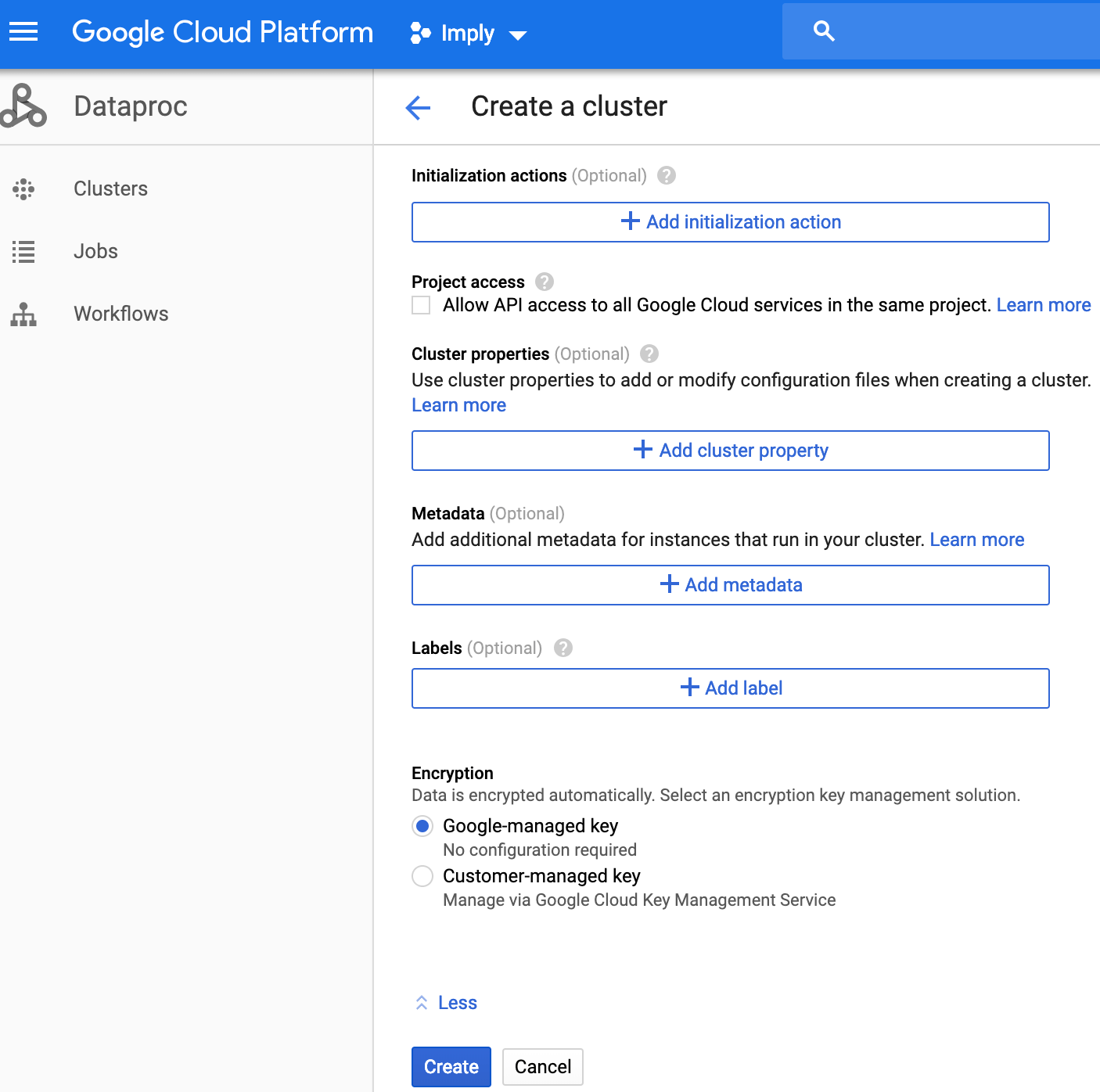
Run a test to read files into the bucket using the hadoop command below. It should list all directories/file underneath it.
hadoop fs -ls gs://your_bucket
Dataproc has some configuration files, along with the packaged open source Druid jars that are needed to be copied over to Imply.
IV. Imply and Dataproc Integration
Dataproc Steps
There are several things that needs to be copied from Dataproc and pushed over to Imply. Here is the list; make sure to apply proper permissions after copying them.
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
Create a bucket that will store these configuration files. You can use a command similar to the one below to copy them over. Login to one of the Dataproc vms and run the command.
sudo gsutil cp /usr/lib/hadoop/etc/hadoop/*-site.xml gs://your_bucket
This will copy over all the Hadoop configurations to your bucket. The next step is to copy the druid-google-extensions folder, google client/api and gcs-connector jars to your bucket. The gcs-connector and the rest of the google jars also needs to be copied over to all Dataproc vms under /usr/lib/hadoop/lib/.
sudo gsutil cp \
/opt/druid/apache-druid-0.13.0-incubating/extensions/druid-google-extensions \
gs://your_bucket
sudo gsutil cp /usr/lib/hadoop/lib/gcs-connector.jar gs://your_bucket
sudo cp \
/opt/druid/apache-druid-0.13.0-incubating/extensions/druid-google-extensions/*google* \
/usr/lib/hadoop/lib/
sudo cp \
/opt/druid/apache-druid-0.13.0-incubating/extensions/druid-google-extensions/gcs-connector
.jar /usr/lib/hadoop/lib/
Update the hadoop-env.sh script to include the gcs-connector.jar in the HADOOP_CLASSPATH. Your entry should look like this. It will automatically be picked up by Dataproc.
HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/usr/lib/hadoop/lib/gcs-connector.jar
Imply Steps
First and foremost, remove the druid-hdfs-storage extension if you have it in your loadList. Your loadList from your common.runtime.properties file should look similar to below.
druid.extensions.loadList=["druid-parser-route","druid-lookups-cached-global","mysql-metadata-storage","druid-google-extensions"]
If you don’t remove the hdfs extension, it will show an error below which will not allow your Dataproc job to run and finish.
1) Error injecting constructor, java.lang.IllegalArgumentException: Can not create a Path from an empty string
at org.apache.druid.storage.hdfs.HdfsDataSegmentKiller.<init>(HdfsDataSegmentKiller.java:47)
while locating org.apache.druid.storage.hdfs.HdfsDataSegmentKiller
at org.apache.druid.storage.hdfs.HdfsStorageDruidModule.configure(HdfsStorageDruidModule.java:94) (via modules: com.google.inject.util.Modules$OverrideModule -> org.apac
he.druid.storage.hdfs.HdfsStorageDruidModule)
while locating org.apache.druid.segment.loading.DataSegmentKiller annotated with @com.google.inject.multibindings.Element(setName=,uniqueId=146, type=MAPBINDER, keyType=
java.lang.String)
Run the following commands to copy over all the configurations and jars from the bucket and put them in their respective location. All of these commands should be applied to all Imply vms. Ensure proper permissions are set.
sudo gsutil cp gs://your_bucket/gcs-connector.jar <imply_home_dir>/dist/druid/lib
sudo gsutil cp gs://your_bucket/druid-google-extensions \
<imply_home_dir>/dist/druid/extensions \
sudo gsutil cp gs://your_bucket/gcs-connector.jar \
<imply_home_dir>/dist/druid/extensions/druid-google-extensions
sudo gsutil cp gs://your_bucket/*-site.xml <imply_home_dir>/conf/druid/_common
The default Hadoop working tmp directory from Imply doesn’t exist in Dataproc so the MiddleManager runtime.properties need to be updated to reflect the Hadoop working tmp directory (/hadoop/tmp) in Dataproc. The update property file should look like this.
druid.indexer.task.hadoopWorkingPath=/hadoop/tmp
Update the common.runtime.properties as shown below.
# For GCS as Deep Storage
# Cloudfiles storage configuration
druid.storage.type=google
druid.google.bucket=imply
druid.google.prefix=druid
# Indexing service logs
druid.indexer.logs.type=google
druid.indexer.logs.bucket=<bucketname>
druid.indexer.logs.prefix=druid/indexing-logs
V. Testing
There are two levels of testing required to validate initial setup before doing hadoop-indexing using Dataproc.
Test 1: Imply HTTP Ingest Test From Pivot
Go to Pivot UI http://pivot_ip:9095. Then follow the steps below to do a native batch ingest and storing segments in GCS bucket.
- Click on the Load button

- This will show several options. Choose Wikipedia Edits.
- This will pull up a series of pages which are ok to leave with default settings.
- Click Sample and continue.
- Click Yes this is the data I wanted
- Click Configure columns.
- Click Additional Configs
- Click Review config

- Click Start loading data
 This will now ingest the wikipedia edit files, create the segment and store them in the GCS bucket. When successful, it should look something like this.
This will now ingest the wikipedia edit files, create the segment and store them in the GCS bucket. When successful, it should look something like this.
The historicals also should have the Wikipedia segments.
This completes the batch ingest into GCS.
Test 2: Imply Hadoop Indexer Test
We will be using the same Wikipedia dataset for this test. Copy over the compressed Wikipedia file locally onto your machine and load it to GCS.
$ wget https://static.imply.io/data/wikipedia.json.gz .
$ gunzip wikipedia.json.gz
$ gsutil cp wikipedia.json gs://your_bucket
Follow the steps below to run the Hadoop indexer.
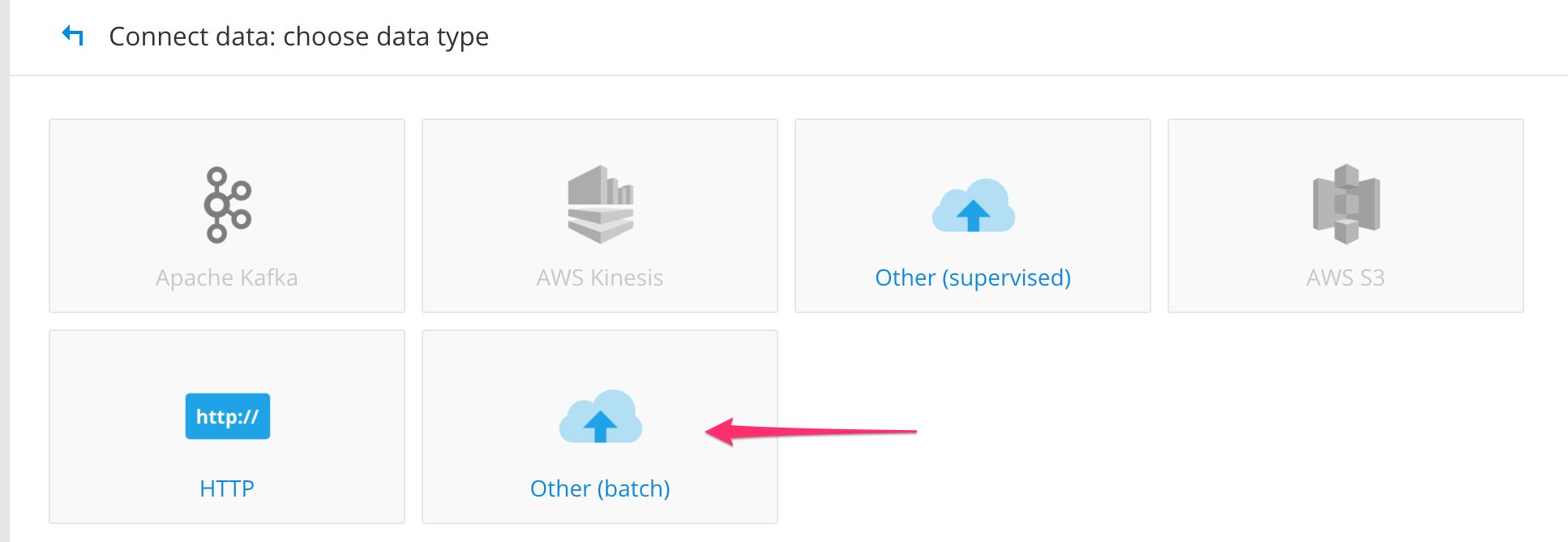
- Click the Load button
- Choose Other (batch)
- This will pull up default ingest spec as shown below.
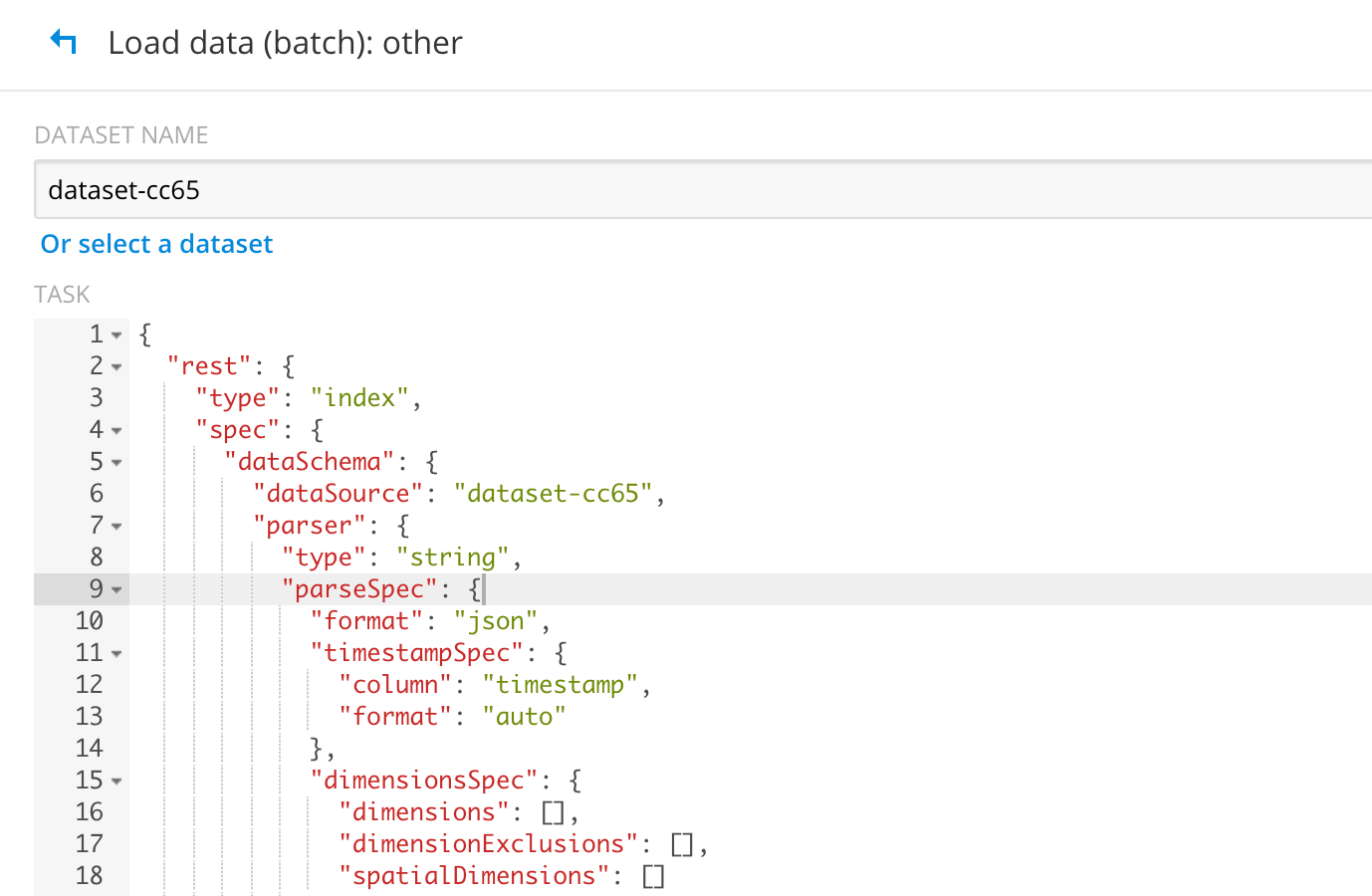 Replace it by using the ingest spec below. Notice that the jobProperties have defined the mapper and reducer java opts to use UTC timezone. If you don’t have this set, Druid will throw an error “No data exists”. Update your “paths” field to point to your file/directory correctly in GCS.
Replace it by using the ingest spec below. Notice that the jobProperties have defined the mapper and reducer java opts to use UTC timezone. If you don’t have this set, Druid will throw an error “No data exists”. Update your “paths” field to point to your file/directory correctly in GCS. { "type" : "index_hadoop", "spec" : { "dataSchema" : { "dataSource" : "wikipedia", "parser" : { "type" : "hadoopyString", "parseSpec" : { "format" : "json", "dimensionsSpec" : { "dimensions" : [ "isRobot", "diffUrl", { "name": "added", "type": "long" }, "channel", "flags", { "name": "delta", "type": "long" }, "isUnpatrolled", "isNew", { "name": "deltaBucket", "type": "long" }, "isMinor", "isAnonymous", { "name": "deleted", "type": "long" }, "namespace", "comment", "page", { "name": "commentLength", "type": "long" }, "user", "countryIsoCode", "regionName", "cityName", "countryName", "regionIsoCode", { "name": "metroCode", "type": "long" } ] }, "timestampSpec": { "column": "timestamp", "format": "iso" } } }, "metricsSpec" : [], "granularitySpec" : { "type": "uniform", "segmentGranularity": "DAY", "queryGranularity": { "type": "none" }, "rollup": false, "intervals": null } }, "ioConfig" : { "type" : "hadoop", "inputSpec" : { "type" : "static", "paths" : "gs://your_bucket/wikipedia.json" } }, "tuningConfig" : { "type" : "hadoop", "partitionsSpec" : { "type" : "hashed", "targetPartitionSize" : 5000000 }, "forceExtendableShardSpecs" : true, "jobProperties" : { "mapreduce.job.classloader": "true", "mapreduce.job.user.classpath.first": "true", "mapreduce.map.java.opts":"-Duser.timezone=UTC -Dfile.encoding=UTF-8", "mapreduce.reduce.java.opts":"-Duser.timezone=UTC -Dfile.encoding=UTF-8" } } } }
- You should be able to see this once the Hadoop indexing is successful.
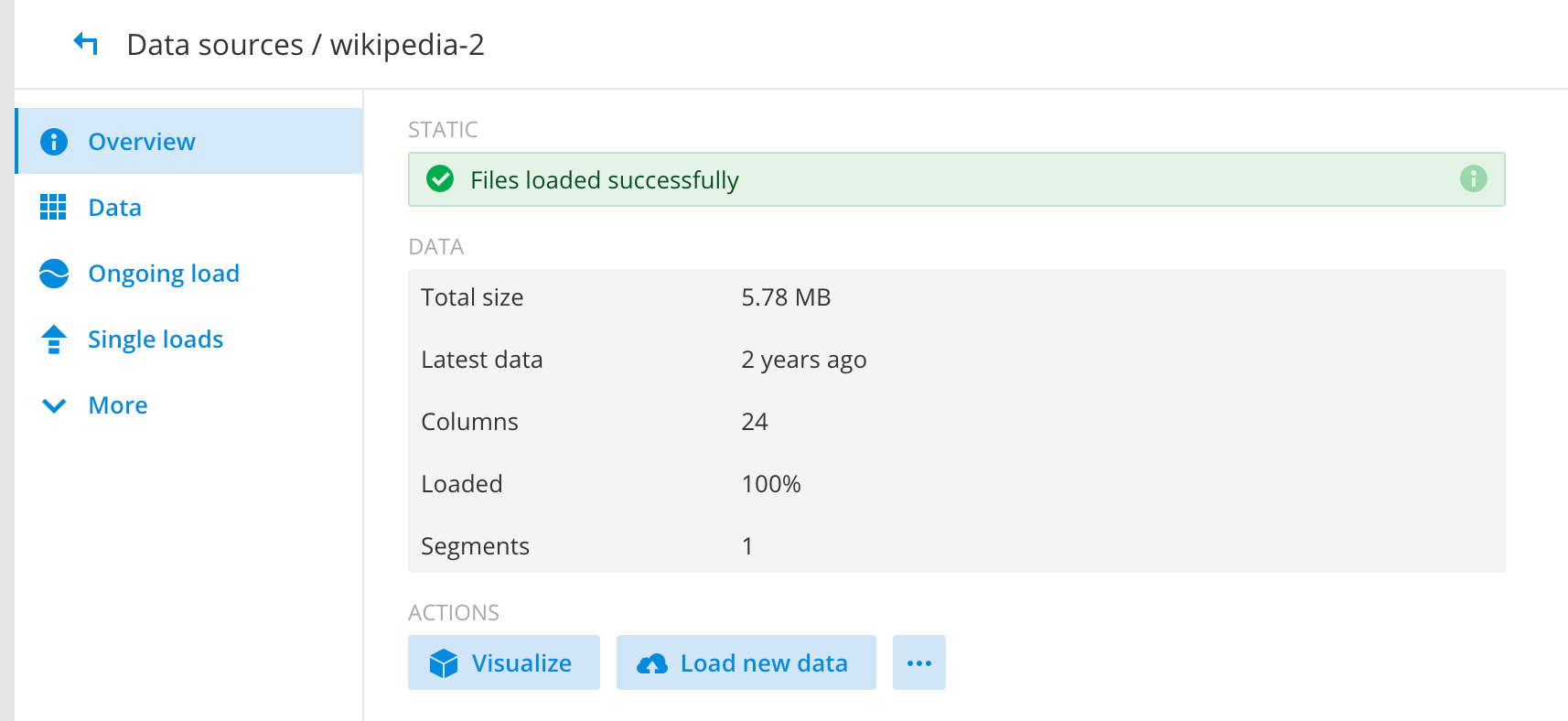 All the segments should exists in your GCS bucket and in historical as well. This completes the full functional testing for Imply and Dataproc.
All the segments should exists in your GCS bucket and in historical as well. This completes the full functional testing for Imply and Dataproc.
- Now we can query the data using Imply Pivot by clicking on the “Visualize” button. This will take you to the “slice-n-dice” page where you can start discovering trends, patterns, etc.
Visualize Page:
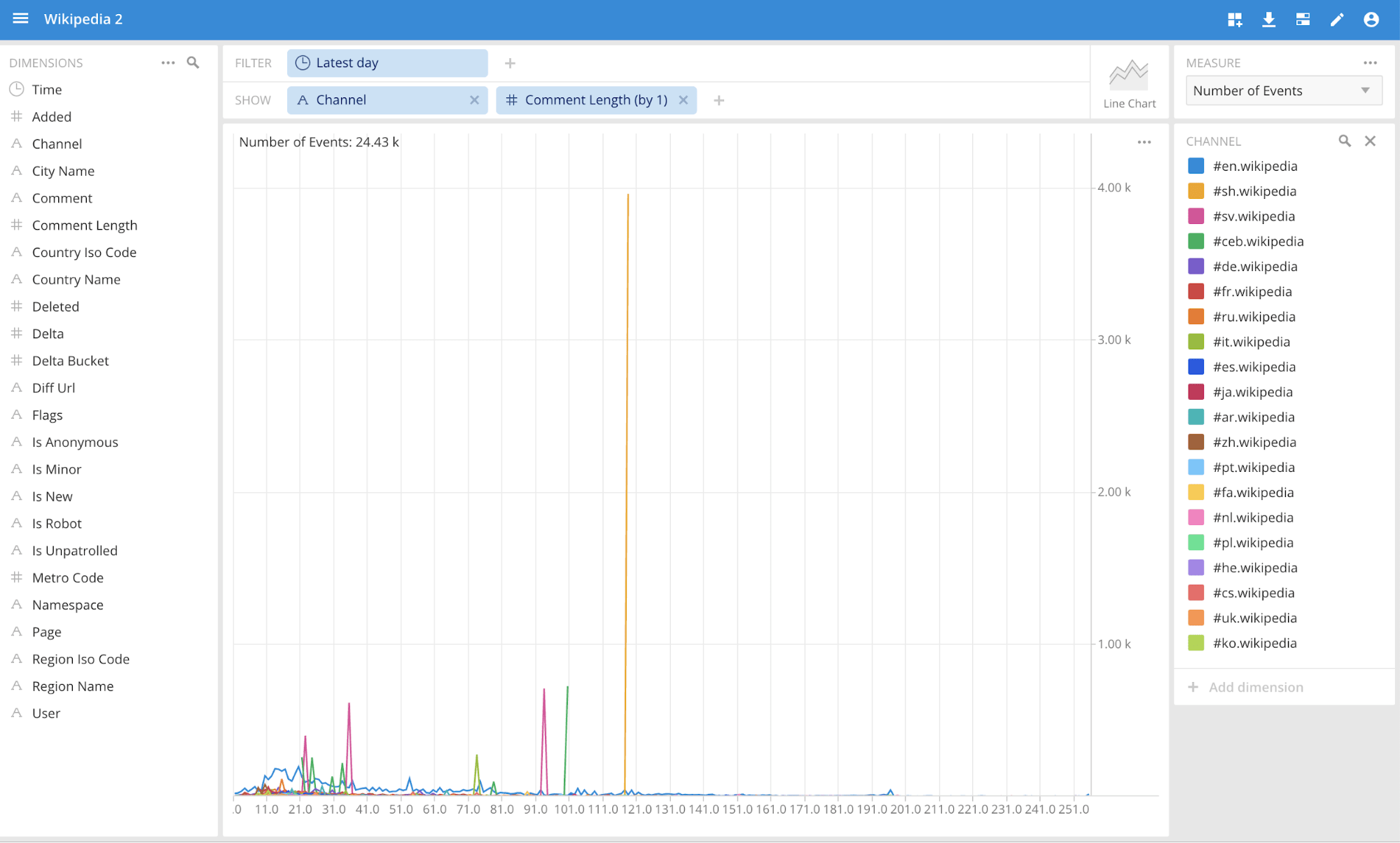
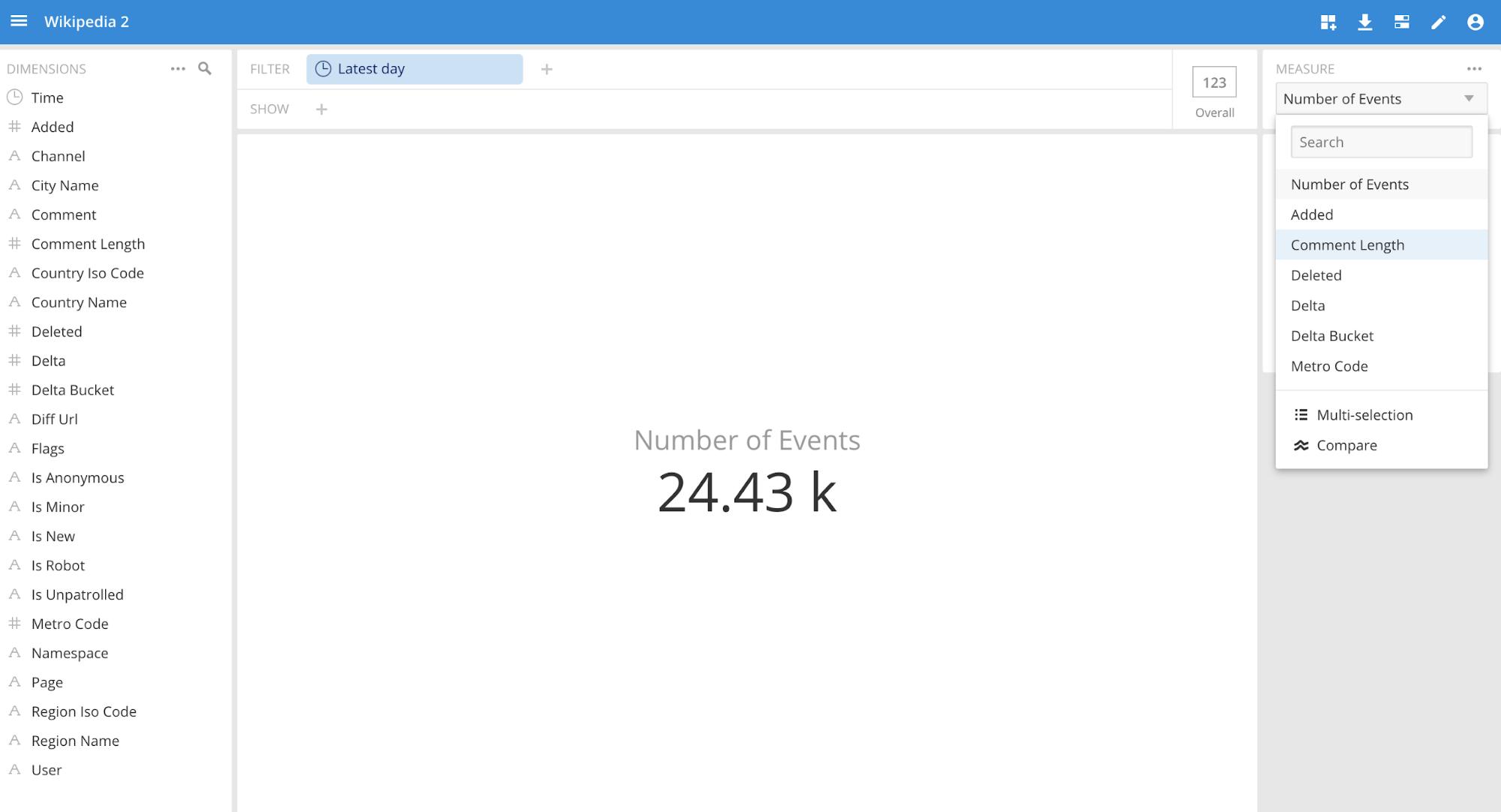 Showing trends for edits by channel and comment:
Showing trends for edits by channel and comment:
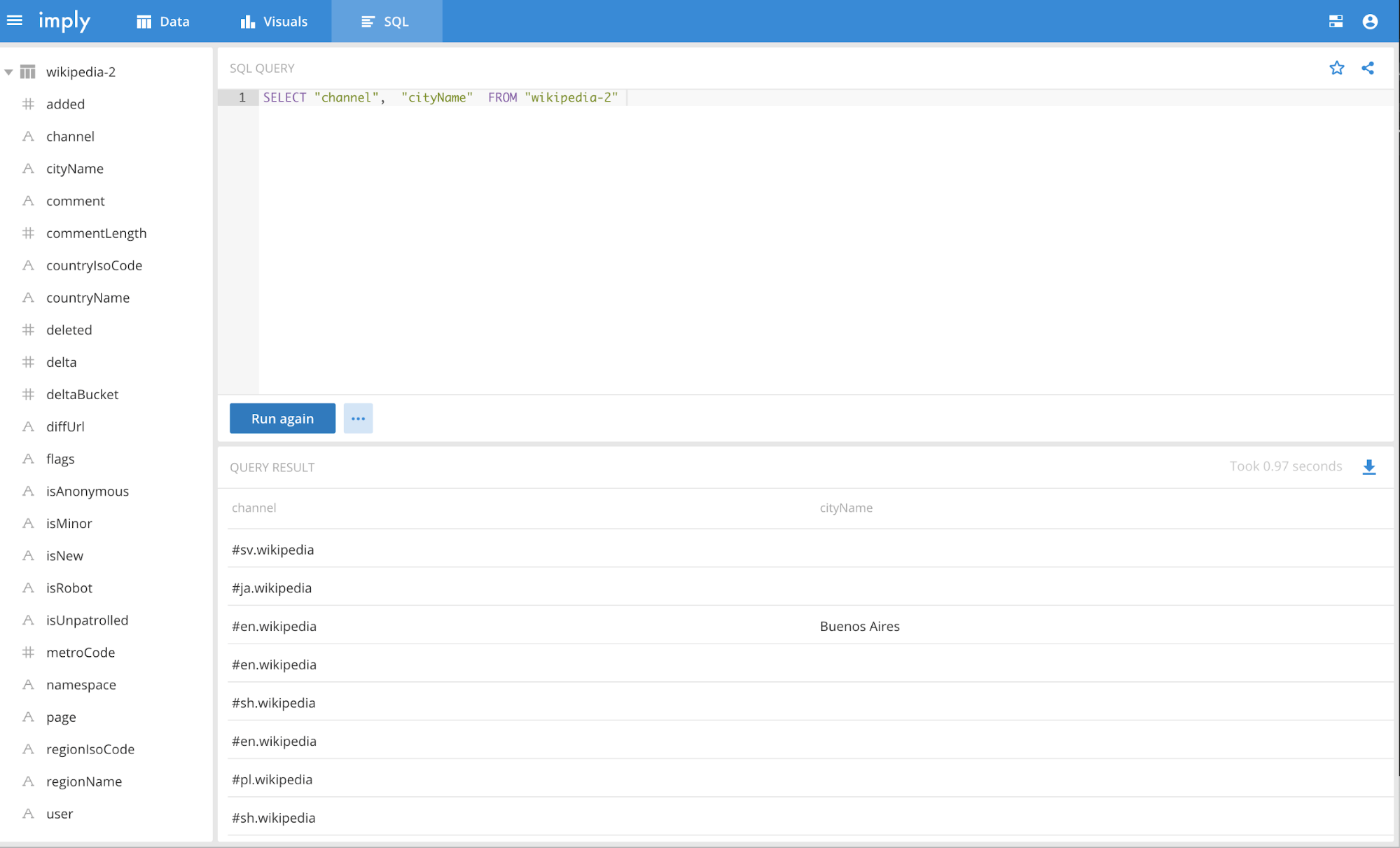
 Running SQL queries in the SQL View:
Running SQL queries in the SQL View:
VI. Troubleshooting
Coordinator Log
com.google.inject.Guice - UnknownHostExceptionX
If you get the exception below, that means that you have an old copy of the -site.xml files from dataproc. A new dataproc cluster has been created and all its -site.xml files have to be copied over to the Imply cluster. 2019-03-16T19:54:08,402 INFO [main] com.google.inject.Guice - An exception was caught and reported. Message: java.net.UnknownHostException: some-host-m java.lang.IllegalArgumentException: java.net.UnknownHostException: some-host-m
MiddleManager Log
- No buckets?? It seems that there is no data to index.
The log below indicates that the Hadoop working directory for Druid doesn’t exist. You can check this in druid.indexer.task.hadoopWorkingPath and make sure that the path exists in hadoop file system. 2019-03-19T15:09:38,646 INFO [task-runner-0-priority-0] org.apache.druid.indexer.DetermineHashedPartitionsJob - Path[var/druid/hadoop-tmp/wikipedia-2/2019-03-19T150739.100Z_1c16425db4864050bbf859979c3da5b2/20160627T000000.000Z_20160628T000000.000Z/partitions.json] didn't exist!? 2019-03-19T15:09:38,646 INFO [task-runner-0-priority-0] org.apache.druid.indexer.DetermineHashedPartitionsJob - DetermineHashedPartitionsJob took 106649 millis 2019-03-19T15:09:38,647 INFO [task-runner-0-priority-0] org.apache.druid.indexer.JobHelper - Deleting path[var/druid/hadoop-tmp/wikipedia-2/2019-03-19T150739.100Z_1c16425db4864050bbf859979c3da5b2] 2019-03-19T15:09:38,781 INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.actions.RemoteTaskActionClient - Performing action for task[index_hadoop_wikipedia-2_2019-03-19T15:07:39.100Z]: LockListAction{} 2019-03-19T15:09:38,784 INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.actions.RemoteTaskActionClient - Submitting action for task[index_hadoop_wikipedia-2_2019-03-19T15:07:39.100Z] to overlord: [LockListAction{}]. 2019-03-19T15:09:38,802 INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.HadoopIndexTask - Setting version to: 2019-03-19T15:07:39.112Z 2019-03-19T15:09:39,075 INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.HadoopIndexTask - Starting a hadoop index generator job... 2019-03-19T15:09:39,126 INFO [task-runner-0-priority-0] org.apache.druid.indexer.path.StaticPathSpec - Adding paths[gs://imply-walmart/test/wikipedia-2016-06-27-sampled.json] 2019-03-19T15:09:39,130 INFO [task-runner-0-priority-0] org.apache.druid.indexer.HadoopDruidIndexerJob - No metadataStorageUpdaterJob set in the config. This is cool if you are running a hadoop index task, otherwise nothing will be uploaded to database. 2019-03-19T15:09:39,189 ERROR [task-runner-0-priority-0] org.apache.druid.indexing.common.task.HadoopIndexTask - Encountered exception in HadoopIndexGeneratorInnerProcessing.
com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem not found
When a MR job is run and the error below occurs, that means that the gcs-connector.jar is not in the HADOOP_CLASSPATH. 2019-03-19T13:54:59,913 ERROR [task-runner-0-priority-0] org.apache.druid.indexing.common.task.HadoopIndexTask - Got invocation target exception in run(), cause: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem not found
Historical Log
com.google.inject.ProvisionException
The error below means that you have hdfs-storage-extension in your loadList. com.google.inject.ProvisionException: Unable to provision, see the following errors: 1) Error injecting constructor, java.lang.IllegalArgumentException: Can not create a Path from an empty string at org.apache.druid.storage.hdfs.HdfsDataSegmentKiller.<init>(HdfsDataSegmentKiller.java:47) while locating org.apache.druid.storage.hdfs.HdfsDataSegmentKiller at org.apache.druid.storage.hdfs.HdfsStorageDruidModule.configure(HdfsStorageDruidModule.java:94) (via modules: com.google.inject.util.Modules$OverrideModule -> org.apache.druid.storage.hdfs.HdfsStorageDruidModule) while locating org.apache.druid.segment.loading.DataSegmentKiller annotated with @com.google.inject.multibindings.Element(setName=,uniqueId=147, type=MAPBINDER, keyType=java.lang.String) at org.apache.druid.guice.Binders.dataSegmentKillerBinder(Binders.java:41) (via modules: com.google.inject.util.Modules$OverrideModule -> org.apache.druid.storage.hdfs.HdfsStorageDruidModule -> com.google.inject.multibindings.MapBinder$RealMapBinder) while locating java.util.Map<java.lang.String, org.apache.druid.segment.loading.DataSegmentKiller> for the 1st parameter of org.apache.druid.segment.loading.OmniDataSegmentKiller.<init>(OmniDataSegmentKiller.java:38) while locating org.apache.druid.segment.loading.OmniDataSegmentKiller at org.apache.druid.cli.CliPeon$1.configure(CliPeon.java:218) (via modules: com.google.inject.util.Modules$OverrideModule -> com.google.inject.util.Modules$OverrideModule -> org.apache.druid.cli.CliPeon$1) while locating org.apache.druid.segment.loading.DataSegmentKiller for the 5th parameter of org.apache.druid.indexing.common.TaskToolboxFactory.<init>(TaskToolboxFactory.java:113) at org.apache.druid.cli.CliPeon$1.configure(CliPeon.java:201) (via modules: com.google.inject.util.Modules$OverrideModule -> com.google.inject.util.Modules$OverrideModule -> org.apache.druid.cli.CliPeon$1) while locating org.apache.druid.indexing.common.TaskToolboxFactory for the 1st parameter of org.apache.druid.indexing.overlord.SingleTaskBackgroundRunner.<init>(SingleTaskBackgroundRunner.java:95) at org.apache.druid.cli.CliPeon$1.configure(CliPeon.java:240) (via modules: com.google.inject.util.Modules$OverrideModule -> com.google.inject.util.Modules$OverrideModule -> org.apache.druid.cli.CliPeon$1) while locating org.apache.druid.indexing.overlord.SingleTaskBackgroundRunner while locating org.apache.druid.indexing.overlord.TaskRunner for the 4th parameter of org.apache.druid.indexing.worker.executor.ExecutorLifecycle.<init>(ExecutorLifecycle.java:79) at org.apache.druid.cli.CliPeon$1.configure(CliPeon.java:224) (via modules: com.google.inject.util.Modules$OverrideModule -> com.google.inject.util.Modules$OverrideModule -> org.apache.druid.cli.CliPeon$1) while locating org.apache.druid.indexing.worker.executor.ExecutorLifecycle