How Adikteev helps customers succeed using self-service analytics
Aug 20, 2020
Margot Miller, Adikteev
Adikteev is the leading mobile app re-engagement platform for performance-driven marketers, and is consistently ranked in the top 5 of the Appsflyer Performance Index. This post discusses how we use Imply to react in real-time to live data from diverse sources to gain actionable insights, thereby improving customer mobile app engagement and making our customer success managers more productive.
The art of re-targeting requires analytics at scale
Adikteev designs and executes mobile marketing campaigns for our clients in order to boost app use and engagement. It is critical for us to capture detailed telemetry in order to try to understand how our retargeting campaigns have influenced user behavior; not just purchases, but also impressions, time spent on different screens and other relevant actions. We want to analyze these outcomes by user segment based on numerous dimensions such as device, OS, location and app-specific information. This data streams in real-time from millions of devices, apps, campaigns, and assets such as ads.
In the mobile application market, total downloads get all of the attention, but for companies looking to monetize their apps, there are many other key performance indicators to watch, such as daily and monthly active users (DAUs, MAUs), user acquisition cost, retention rate, and others. These KPIs contribute to user lifetime value (LTV), and profitability depends on the average LTV covering the costs of development, operations, and doing business. Optimizing the performance of marketing campaigns is a major key in achieving a profitable LTV.
Retargeting is the art of determining when to message a customer to try to get them to re-engage with the application. A multichannel retargeting campaign could consist of ad placements, an in-app push notifications, SMS, and emails. To be efficient with messaging spend, it’s critical to understand how likely a particular customer might be to re-engage with the app based on that message.
Adikteev uses all this data with the ultimate goal of measuring, understanding, and improving the performance of the campaigns we run for our customers. The data can be as deep and granular as any event that is captured by the advertiser with all of those events being pinged to Adikteev.
Dashboards vs. ad hoc analytics
As at many companies, Adikteev dashboards are a common and popular way to monitor our business, and these dashboards are used across almost all departments and functions, and at every level, from the front-line practitioners to C-suite executives. They are built by a BI team or analysts to give summary information to monitor trends, certain metrics, and specific KPIs.
While dashboards are useful for pre-built standard reporting use cases, we have found that standard Tableau dashboards don’t lend themselves nearly as well to operational and self-service exploratory analytics, primarily because they are just too slow when any updates or changes need to be made to the dashboard in order to further investigate or explore the data for decision making purposes. The databases that the dashboards pull from can’t keep up and it can take seven minutes or more for them to reload.
Our internal users often need a change to the standard dashboard to further explore the data to understand an anomaly or other issue. They may want to add a new column, filter, parameter, aggregation, or other computation or field to the report. Making these changes can delay the process of updating the dashboard. Often this requires a new request to the central BI/Analytics team, which can take even longer depending on that team’s backlog.
These delays can severely impact the productivity of our Tableau dashboard users. As a result, decisions may often be significantly delayed until they have the exact analytics results they need.
Achieving operational performance excellence with Imply
In order to overcome the delays and productivity hit associated with attempting to use traditional dashboards for analytics, we have implemented Imply as a self-service ad-hoc analytics solution for customer success managers (CSMs). By adopting the Imply platform,we were able to improve the speed and freshness of data available to our customers. When onboarding a new client, Imply allows our CSM to demonstrate a very fluid, smooth and dynamic analytics capability. CSMs can respond in real-time to customer needs, even while in a campaign performance meeting.
In addition to internal use, Imply allows us to provide our customers with their own analytics to gain a direct understanding of how well their campaigns are performing. Adikteev customers get the flexibility to import data into their own multi-vendor data consoles and to pull data directly into their own systems of record.
Using Imply to optimize customer cohorts for retargeting
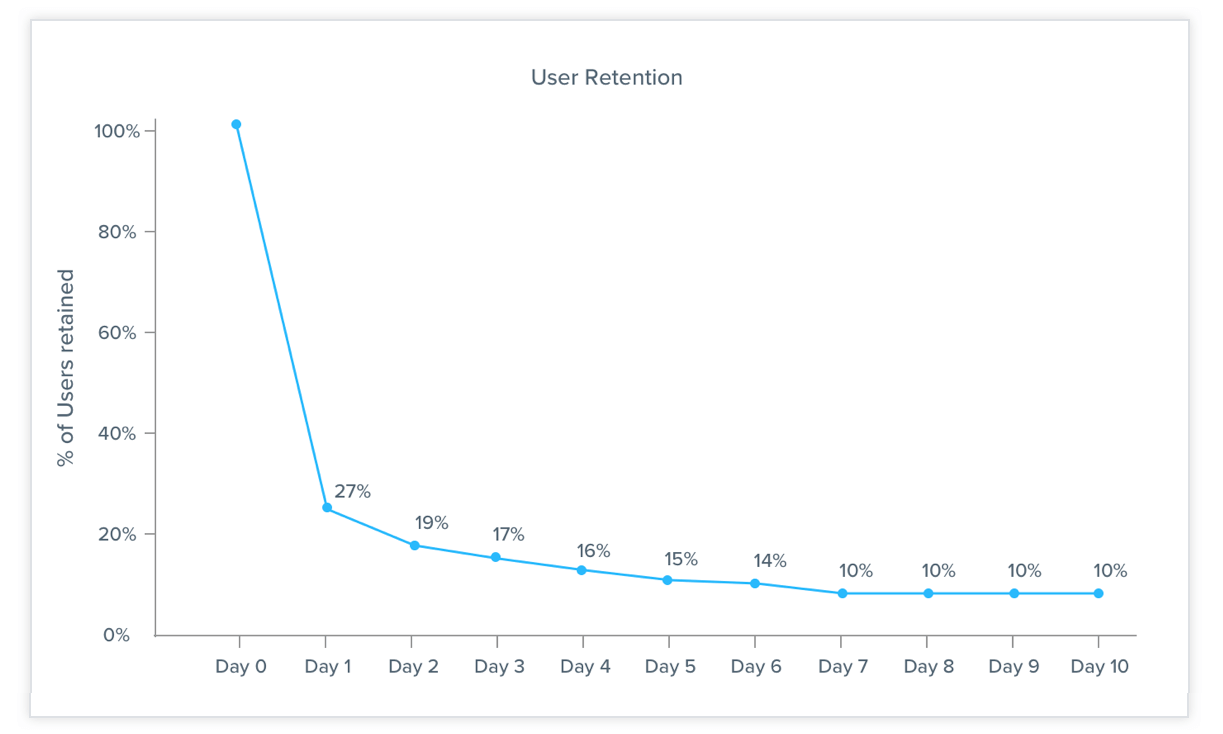
One of the ways that mobile application managers segment their customers is to group them into cohorts depending on how long it’s been since the last time they engaged with the app. The lapsed customers are often viewed in terms of a retention curve that describes how many customers have dropped-off by day as shown in the example graph below.
During a call with a gaming client to discuss retargeting campaigns, the client stated that they wanted to target customers who were more than 30 days lapsed. Using Imply on the call, the CSM was able to analyze data for that application and in real-time show the client the effectiveness of marketing campaigns based on time passed since the customer had lapsed.
Our analysis showed that most of the app use drop-off is coming from day 1 to day 5, followed by a flat period between days 5 and 8, and then almost no drop-off between 8 and day 30.
They were able to convince the client to move the retargeting campaign criteria from day 30 to day 8, which improved outcomes in the following ways:
The campaign performed better because it was not needlessly re-tarteging unlikely prospects who hadn’t engaged with the app for between 8 to 30 days.
Our success allowed us to scale the campaign and create more impact for the client.
We were able to make this decision live consultatively while on the planning call with the customer.
We have learned from experience that if you target too far out, the performance is not going to be good due to small scale, and then it becomes a vicious circle, all as a result of having chosen a poor initial time horizon for the retargeting. Using Imply live enabled us to convince the customer to spend at a sufficient scale to ensure campaign success.
Besides using Imply to help a customer make better marketing decisions and improve their ROI, we were also able to act as a trusted advisor to our clients, which helps cement the relationship, increase share of wallet and reduce risk of churn.
Using Imply Pivot alerts to detect active user falloff
Another benefit of using Imply real-time analytics is the ability to monitor various aspects of a customer’s application beyond the specifics of campaign reporting. We have set up a variety of internal dashboards to monitor other critical KPIs of the app.
One of those KPIs is Daily Active Users (DAU). Recently, one of our clients made a change to their retargeting strategy, and we used Imply Pivot alerts to show that the change was having a substantial negative effect on the customer’s DAUs. We were able to alert the client to the change a full two days before it became visible in their own internal data tracking systems. As a large drop in DAUs can have a very significant effect on an app’s success metrics, being able to deliver an early warning of the negative consequences of that change potentially saved the client from a possibly very bad business outcome.
Conclusion
By using Imply real-time self-service analytics instead of relying on slow and stale dashboards, we have been able to achieve both internal productivity gains, making better decisions faster, provide our external clients with strategic advice to improve the performance and effectiveness of their retargeting marketing campaigns, and notify clients quickly of potentially serious problems with changes to their business even days before the client would have noticed it themselves.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...