Oct 22, 2024
Introducing Apache Druid® 31.0
We are excited to announce the release of Apache Druid 31.0. This release contains over 525 commits from 45 contributors.
Learn MoreAre you building a data-driven web application that needs to serve data to your users with low latencies? Are you using MySQL, Postgres, or another traditional RDBMS as the backend for that web application? If so, you’re inevitably going to run into scalability issues as your dataset expands and your usage demands grow. These scalability issues will result in massive performance degradations for your users if you don’t find a solution that scales to meet your growing needs. Fortunately, Apache Druid is exactly what you need to keep costs down while enabling hundreds of your users to simultaneously query terabytes of your data with sub-second latencies.
These scalability issues occur because traditional RDBMSs simply aren’t designed to handle massive datasets or high concurrency. They are natively single-server, single-threaded, and are designed to only scale vertically (by increasing the size of the server) rather than horizontally (by increasing the number of servers). Although recent versions of Postgres have introduced parallel queries (still missing in MySQL and most other RDBMSs), even Postgres servers are still unable to handle even dozens of concurrent queries, let alone terabytes of data or complex query plans. As the Postgres docs themselves point out, “Many queries cannot benefit from parallel query,” leaving engineers with no option but to find another database.
With your growing user base and dataset, it’s important to think about how your backend will scale to meet your demand.
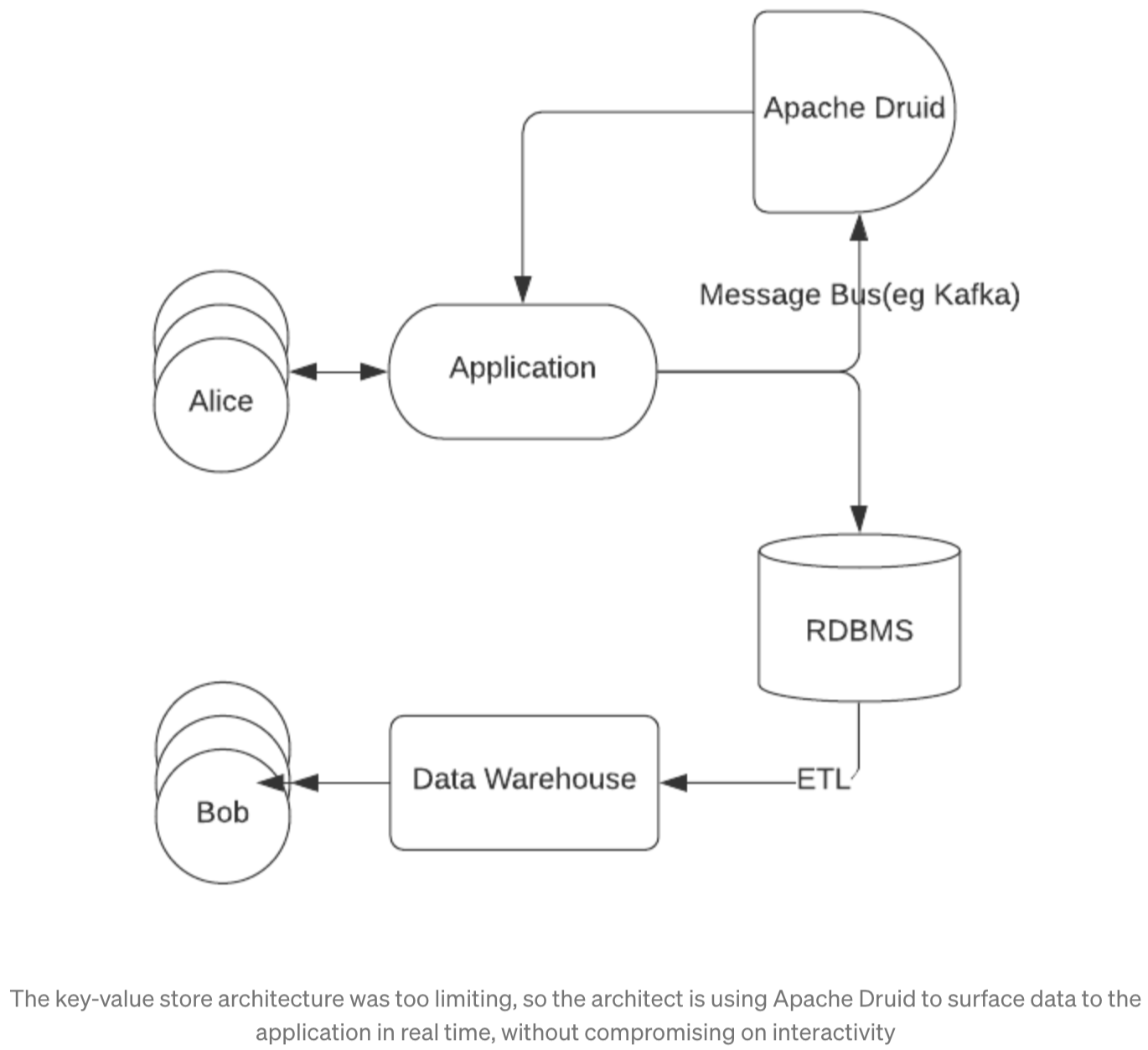
Once upon a time, all data was stored in traditional database systems. Data would be generated either by a user interacting with an application or from some source external to the application, stored in the database, and then surfaced to the user through the application.
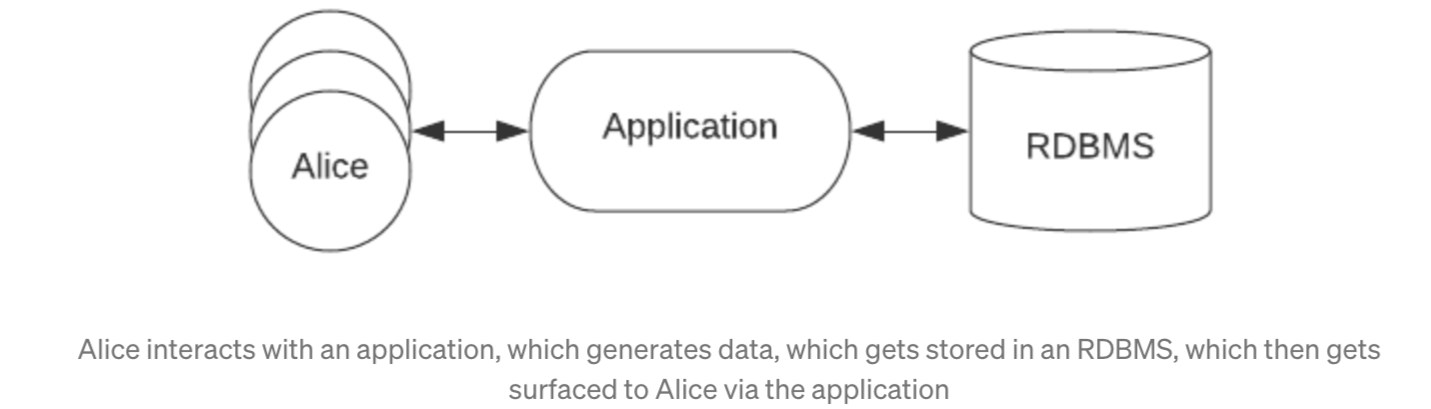
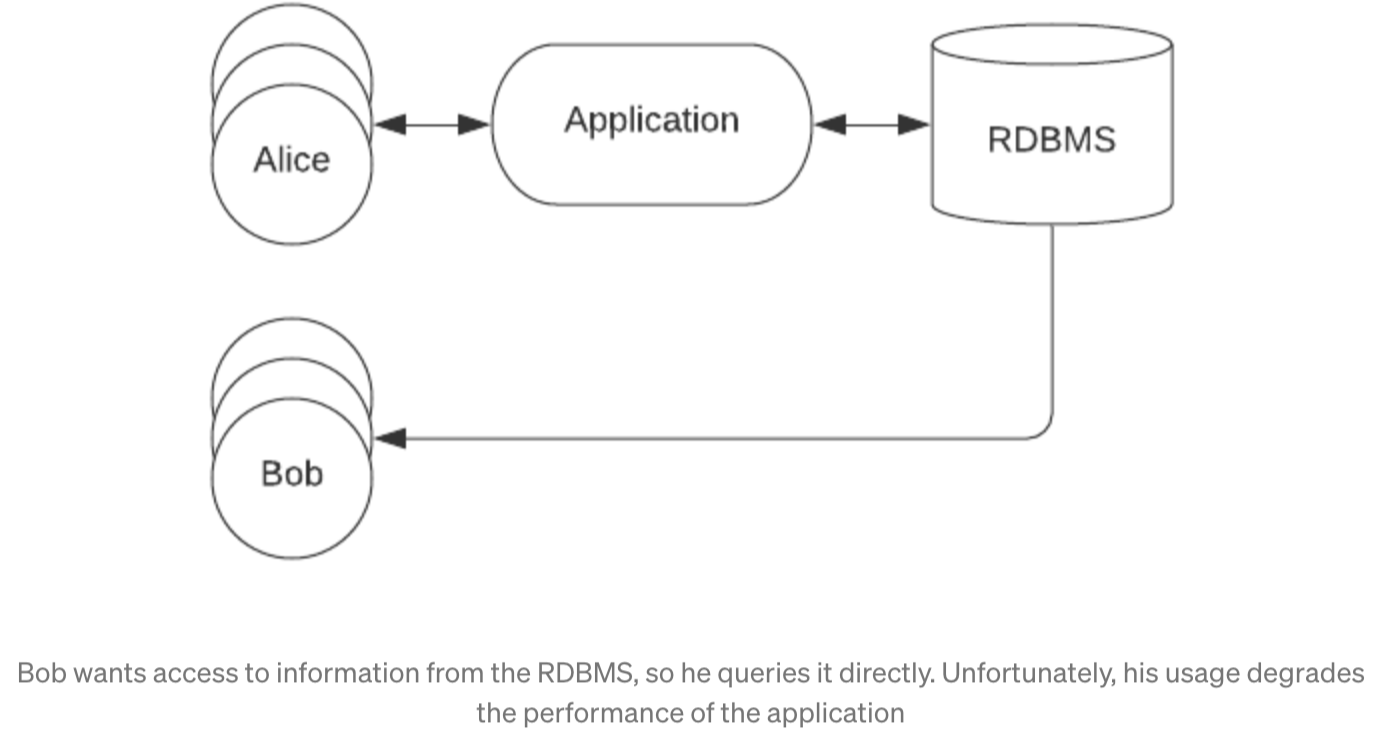
This works well enough at first, but things quickly change when internal users want to run analytics on that data as well. Product managers, engineers, and even executives inevitably want access to usage data (such as the number of active users, number of interactions, etc), which means that business intelligence (BI) reports get run directly against the database. This increase in query volume and concurrent requests results in performance degradation for external users, making applications run slower and decreasing user engagement.
In response to this, we began to see the rise of data warehouses, ETL, and data engineers. Data warehouses are data storage systems which are explicitly created to service those internal users, offloading that burden from the traditional database which could still be used to power front end applications. Data engineers would write ETL (Extract-Transform-Load) scripts to process and move the data from databases into data warehouses, thereby enabling BI functionality without negatively impacting the performance of the user facing application.
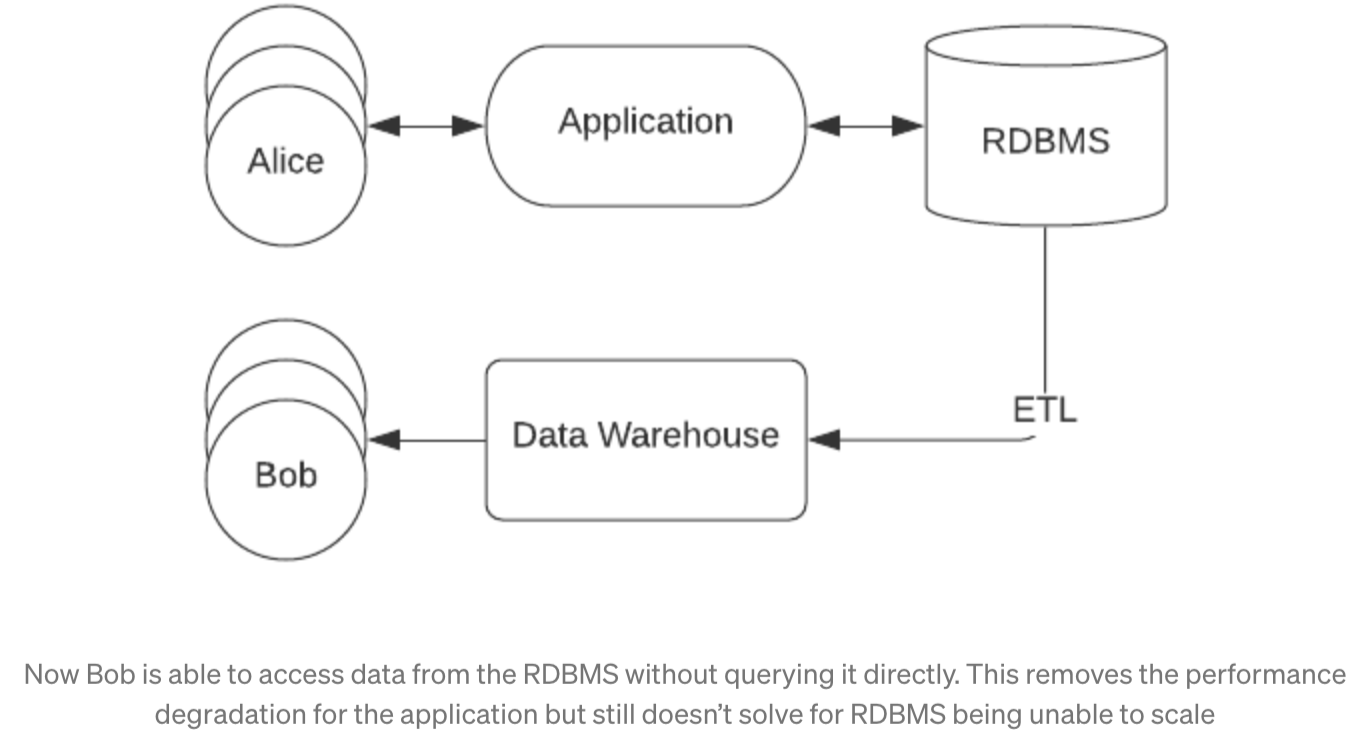
The introduction of data warehousing helped to offload the burden from the databases powering the application, but ultimately even horizontally scalable data warehouses couldn’t totally replace RDBMS systems. Simply put, data warehouses like Redshift, Snowflake, and BigQuery, were developed to power BI reporting and what’s called “cold analytics”, where queries can return in the matter of minutes and concurrency is low. They aren’t built to power interactive applications, where you can have dozens of users submitting requests simultaneously and wanting their results back in less than a second.
With horizontally-scalable data warehouses unable to service data-driven applications, where should developers look when their Postgres or MySQL database starts to fail? One approach that engineers have tried is to pre-compute the entire range of possible query results and store them in a key-value store like Apache Cassandra or Dynamo.
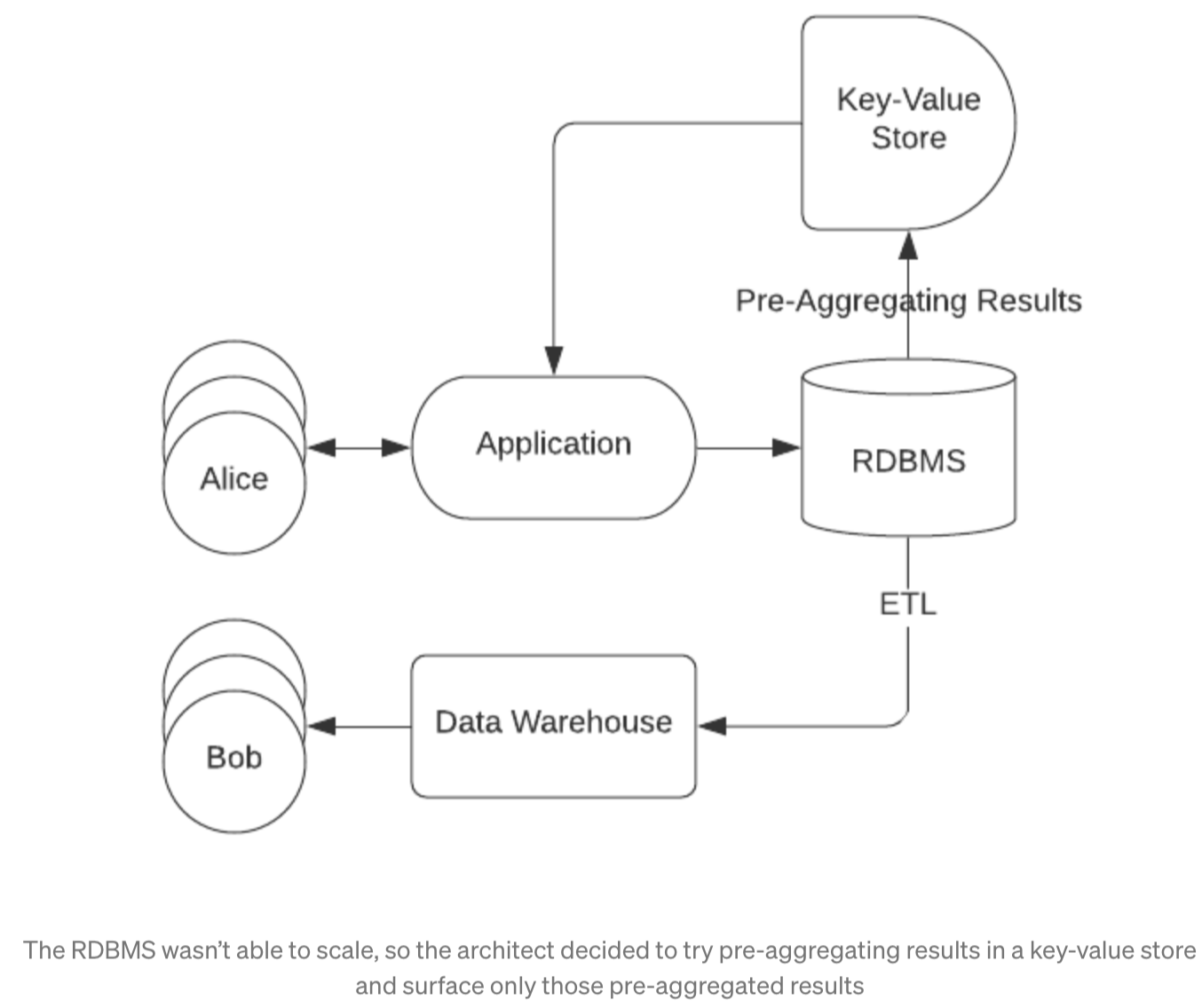
This approach has the advantage of being able to handle lots of concurrent requests while maintaining low latencies, but has some obvious drawbacks. One drawback is that pre-computing query results is a computationally expensive operation, as all possible permutations of filters and groupings must be computed, which means either limiting the types of questions that users can ask of their data or spending inordinate amounts of compute resources on pre-computing these queries. The other drawback is that new data coming in won’t be added to the query results until the query pre-computation operation has run again, meaning that any semblance of real-time ingestion is lost.
In summary, the options for backends that we’ve explored all have limitations. RDBMSs such as Postgres and MySQL are easy to stand up and offer great interactivity, but simply can’t scale beyond a single server, limiting your ability to grow your application. Data warehouses such as Redshift, Snowflake, and BigQuery can help to offload some of the BI workloads from your RDBMS, but ultimately aren’t built to support interactive, custom data applications. And although the key-value store gives both scalability and fast latencies, the need to pre-compute data means that you’re limiting the breadth of questions that your users can ask and won’t be able to surface new data to end users in real time. So, does there exist a solution which will give us the interactivity of an RDBMS, scalability of a data warehouse, and the concurrency of a key-value store?
Apache Druid was created explicitly with the limitations of these prior systems in mind. Imply cofounders Fangjin Yang and Gian Merlino were working at Metamarkets, a data platform for advertisers, when they surveyed the marketplace and saw that no existing tool or solution provided the features that they needed to act as a backend for their custom data application. That’s why Apache Druid was designed to allow users to continue having a conversation with their data, just like they’re used to having with an RDBMS backend to a data-driven application, while also enabling massive scalability beyond the limitations of a traditional RDBMS.
Druid scales both horizontally and vertically, meaning that as your concurrency demands and the size of your data increase, you can just add more servers to the cluster or increase the size of the current servers.
Druid is also built for speed AND redundancy. The data is stored on the local server much like a traditional database. This provides for fast queries because latency between disk and CPU is minimized. Additionally, a copy of the data is stored in HDFS or an object store which means that the data is already set up for redundancy and disaster recovery.
Druid’s optimized data format allows for fast querying of the data regardless of the question the user is asking of the data. Gone are the days of limiting what users’ can ask based on what indexes exist in the data schema.
Another example of how Apache Druid is designed for custom data applications is its ability to ingest data in real time from streaming sources like Apache Kafka and Amazon’s Kinesis. These message buses have become mainstays in event-driven and streaming architectures, allowing users to access data almost as soon as it’s created. None of the tools discussed above are able to ingest data quickly from these streaming sources, meaning that the real-time capabilities that these message buses should provide are lost if you’re not using Druid.
Of course, any system isn’t without its tradeoffs, and it would be disingenuous to pretend that Apache Druid is a magic bullet database that will be the best tool for every job. Druid allows for incredible scalability, incredibly low latencies, and incredibly high concurrency, which makes it the perfect tool for data-driven applications that need to rapidly surface data to their users. However, Druid is an OLAP database, so it’s great for analytical workloads but not transactional ones.
This means that if you’re frequently updating or deleting individual rows in your database, Druid isn’t the correct database for you. Simply put, Druid stores data in a columnar data format, which means that modifying a single row means opening and rewriting multiple files to make those changes. For this reason, Druid works best when replacing Postgres and MySQL for analytical workloads, which simply append new data to an existing dataset rather than modifying the rows in the existing dataset.
I’ve seen Druid be incredibly successful at replacing traditional RDBMSs for fully analytical workloads or working side-by-side with a traditional RDBMS where transactional workloads are handled by the RDBMS and analytical ones by Druid. Transactional workloads represent a fraction of the current usage of RDBMSs, so if you’re primarily using your RDBMS for analytical workloads, I highly recommend looking into Apache Druid as the new backend for your custom data application.
I decided to write this post because I’ve been seeing so many companies use an RDBMS as the backend for their custom data application, run into huge performance issues when their application began to scale, and then rescue their product with Apache Druid. I’ve seen Postgres DBAs try every trick in the book to hack their way into scaling Postgres way beyond what it was intended for, and then reap the consequences when those hacks inevitably failed. Rather than go through the same growing pains that so many have gone through, I invite you to reach out and see whether Apache Druid and Imply might be a good fit for powering your data-driven application.
Introducing Apache Druid® 31.0
We are excited to announce the release of Apache Druid 31.0. This release contains over 525 commits from 45 contributors.
Learn MoreAn Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreLast Call—and Know Before You Go—For Druid Summit 2024
Druid Summit 2024 is almost here! Learn what to expect—so you can block off your schedule and make the most of this event.
Learn More