Community Spotlight: SuperAwesome kid-safe internet advertising powered by Apache Druid
Jan 24, 2021
Peter Marshall
SuperAwesome’s mission is to “make the internet safer for kids”: a safe, effective, and entertaining place that is 100% “kid-safe”, including an advertising system that protects the personal data of children.
Following their popular Apache Druid meetup presentations, Saydul Bashar, Data Engineer, and Nicolas Trésegnie, Chief Architect, share with the community why and how SuperAwesome uses Apache Druid.
Saydul, who cares for the reporting service, and Nicolas, who holds an overview of technology across the teams, rely on Apache Druid to enable superfast decision making with uses such as guaranteeing respectful, effective, safe advertising, and monitoring workflows on apps and websites.
SuperAwesome’s first architecture, Nicolas explains, was a quite bespoke solution. And when the time-stamped data got more difficult to analyse quickly, they had to look for an alternative. They tried other systems, but the cardinality and the breadth of the data set they wanted to analyse became a real issue.
Today, because of Apache Druid, SuperAwesome analyses events in real-time, and not just in one domain but in many, using more than 30 dimensions, many of which have high cardinality.
For internal exploration, SuperAwesome uses Metabase on top of Apache Druid, as well as using the API for direct queries and to extract data for machine learning to support dynamic decision-making.
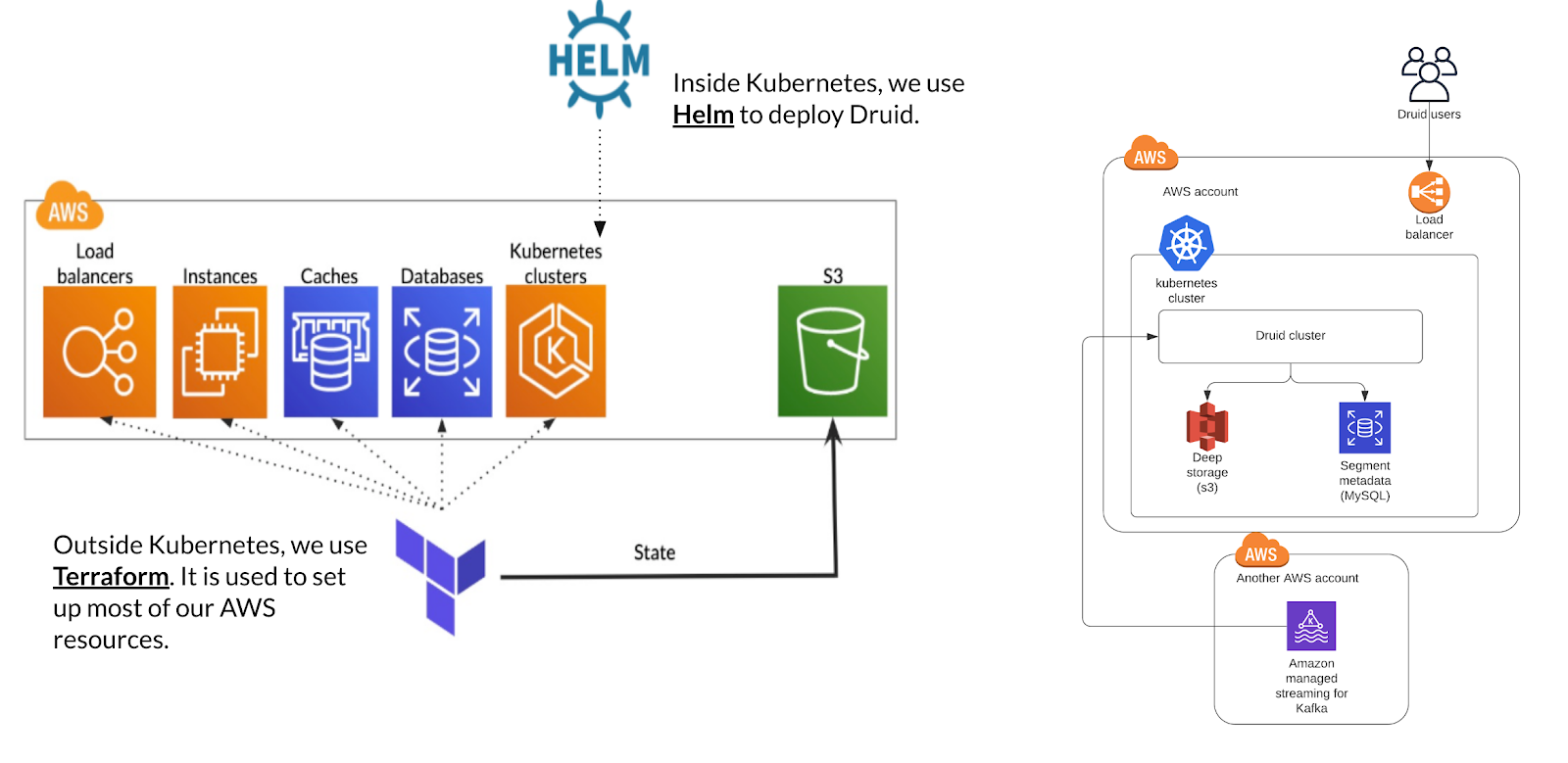
Saydul and Nicolas need SuperAwesome’s Apache Druid cluster to be a strong player in their pipeline: it has to be resilient and it has to be performant. With Datadog, they monitor everything from query performance to ingestion lag, while with a Kubernetes Dashboard they monitor consumed infrastructure resources for capacity planning.
Their Kubernetes-based, spot-instance infrastructure on AWS comprises a highly-available multi-coordinator, multi-overlord, multi-broker service on top of twelve middle managers for ingestion and ten historicals for long-term query. Their architecture is highly stateless, and both Nicolas and Saydul see the benefits: having the metadata database and deep storage entirely separate from the Druid processes makes it easier to bring down and to upgrade, and for it to rebuild and heal itself quickly.
Ingestion lag from Apache Kafka is an alarm bell for SuperAwesome: lag is the first sign that there are issues in the pipeline that, left unchecked, could become a critical problem for the business. In their advertising service, for example, lag has a direct impact on the efficacy and efficiency of campaigns – the faster that a change is made, the better the results for all concerned. Nicolas particularly called out the value of Druid’s exactly-once ingestion guarantees from Apache Kafka in scenarios like this.
“In the face of failures in the system, the results may be later than expected, but we can at least guarantee those results will be accurate when data does finally arrive.”
Saydul, Nicolas, and their teams are frequent visitors to the Google User Groups and ASF Slack, and speak regularly at meetups. We thank them for their continued support and voice in the community, and look forward to hearing from them more in the future.
The community would love to hear your story! Email community@imply.io to sign up for a 5-minute interview for your own Community Spotlight, and to discuss opportunities for blog posts and speaking slots, as well as to get the latest information about community activities across the world. And we’re also here to help you get your name in lights on Apache Druid’s Powered By page.
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...