Security is a critical requirement in every deployment of a system that holds and processes data Specifically, a secure data processing system should support:
Authentication, to identify what entity is accessing the system
Authorization, to control what an authenticated entity is allowed to access
Secure network communications, to prevent eavesdropping and tampering with messages
In this blog post, we will discuss how we secured Apache Druid (incubating), and validated our implementation.
Druid was initially open-sourced and released to the general public in 2012 In its early development, Druid did not have any built-in security features Although security is a critical general requirement, it is not uncommon for an open source project to initially focus on specific use cases and add security later on.
Without built-in security, users who deployed Druid were forced to shoulder the significant burden of implementing their own security controls on top of Druid Such external controls included measures such as complex network-level security policies, configuring and maintaining TLS and authentication proxies in front of Druid, and building custom Druid request parsers to perform authorization checks.
This lack of built-in security hindered Druid’s adoption in some cases, as not all users have the technical resources to build and maintain their own security controls on top of Druid.
In 2016, an experimental authentication and authorization framework was added to Druid, with the primary goal of allowing Druid to support datasource level access control This patch was a major step forward that enabled organizations with software engineering resources to develop extension plugins for this security framework However, there were no publicly released security extensions until early 2017, when the Kerberos authentication extension was added.
Starting from mid-2017, the Druid community made a big push to improve Druid’s security system and ensure it meets the stringent security requirements of modern enterprises As part of this initiative, Druid now supports encrypted TLS connections for client-server traffic and internal communications, and well as flexible authentication and authorization mechanisms.
At Imply, we focused on productizing Druid’s experimental authentication and authorization system Below, I’ll discuss a couple of the techniques we used in designing and validating the security system.
Pre-response sanity checking
While designing and developing the new authentication/authorization system, we faced the following challenge: how do we know that we’ve secured everything?
It is inherently difficult to completely secure a codebase after it has grown as large and complex as Druid’s As a rough estimate of the number of interactions that need to be secured, I searched for HTTP method annotations in the Druid codebase with:
As of August 29, 2018, there were ~206 HTTP endpoints!
Since Druid is open source and supports extension plugins, developers are free to add new functionality and points of access. It’s quite possible that new code neglects to add security checks.
The prior experimental security layer was opt-in: if a point of access did not have security checks, it would continue function as an unsecured resource, making it difficult to determine if security holes existed.
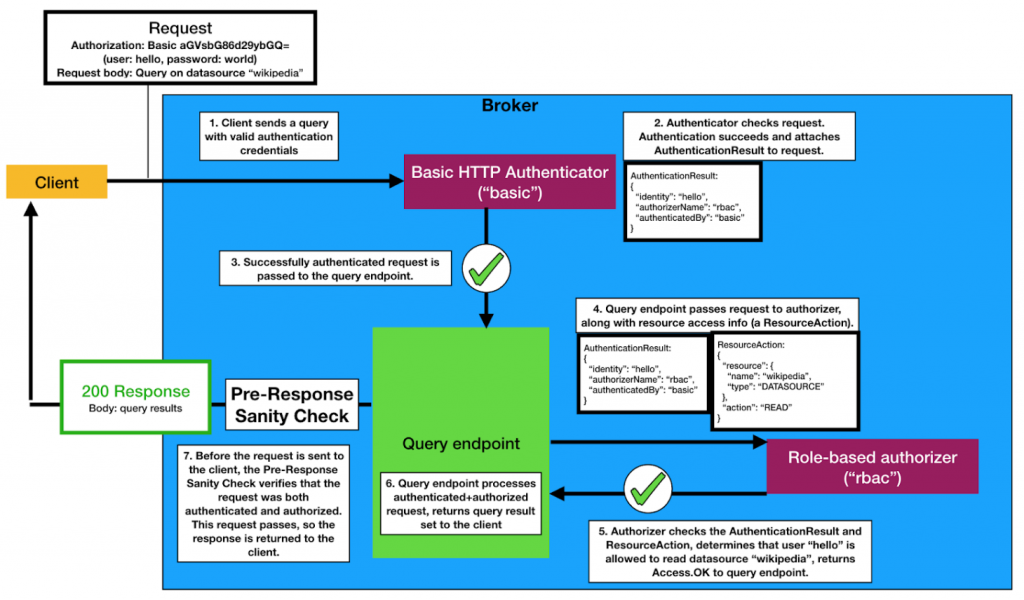
To see how we addressed this challenge, let’s take a look at the following diagram, showing the security checks that a query to Druid passes through.
Here, a client is sending a query to a Druid broker node Within the broker node, there are 4 entities of note: the authenticator, the query processing endpoint, the authorizer, and the pre-response sanity check.
The request first passes through the authenticator, which verifies the identity of the entity issuing the query In this example, we’re using Basic HTTP user/password authentication When the authentication check passes, an “Authentication Result” object is attached to the request.
After passing through the authenticator, the request goes to the query processing endpoint The query processing endpoint inspects the query and sees that it’s for the “wikipedia” datasource The query processing endpoint then asks the authorizer to check if the requester is allowed to access “wikipedia” The result of this authorization check is also attached to the request.
The next step in the request processing sequence shows a simple technique that we use to help us ensure that we’ve secured all request handling endpoints.
Before the response is sent to the user, the corresponding request is inspected by the pre-response sanity checker This sanity check ensures that both an authentication result and authorization result were attached to the request If either is missing, this sanity check will abort the response and send an error instead to the client, while logging an exception.
This check applies to every single request If a developer wants to skip security checks for a particular request endpoint, they must explicitly register that request endpoint as “unsecured”.
This sanity check allows Druid’s security system to have fail-shut, opt-out behavior, but it does not prevent all authorization bugs For example, it’s still possible for a request handling endpoint to perform an authorization check that doesn’t match the semantics of the request being made.
Nevertheless, the check has proven to be quite useful for catching errors of omission, for example.: The following pull request shows one example, where the API endpoint for retrieving datasource names and metadata from the Druid coordinator was left unsecured.
This pull request is another example, where this feature informed us that authorization checks were not being performed on any HTTP OPTIONS requests From my recent personal experience, I had forgotten to put authorization checks on a new ingestion task stats API that I was building, and this sanity check helped me catch that error during development.
Unsecured deployments
How should we handle cases where the user wishes to run their cluster in an unsecured mode?
This is quite common For example, users often deploy temporary test or development clusters that don’t hold any sensitive or important data, where the security checks would be seen as an unnecessary hindrance.
We address the unsecured case by providing “allow all” implementations of authentication and authorization extension interfaces that allow all requests to succeed, with all other security-related parts of the request handling sequence remaining identical This helps reduce complexity and opportunities for bugs by having a unified code path for all requests.
Final thoughts
We have discussed the evolution of Druid’s security system, provided an overview of the challenges involved in building the current system, and shared useful design and validation techniques.
The Druid community continues to develop more security features for Druid We are currently working on implementing support for mutual TLS.
Other enhancements that would be quite useful but are not currently being developed include (but are not limited to):
Audit logging
Row & column level access control
More authentication and authorization extension implementations
If you would like to contribute to Druid or get involved in the community, please join us at apache/incubator-druid!
Other blogs you might find interesting
No records found...
Jun 11, 2026
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...
A First Look at Lumi Loglake: Query Logs Where They Live
TL;DR: Imply Lumi Loglake is a lakehouse (separated compute/storage) architecture for unstructured logs that reduces costs from 40% up to orders of magnitude on your hardware/AWS/Azure bill used to run your...