90% Amount of team members enabled with ad-hoc data exploration
8X Reduction in operational overhead
Business Goals
Kueez is an elite squad of technology and data experts that develops a technological platform for content creation, user experience, media buying, and monetization of online content, Founded in late 2016 by serial digital entrepreneur Ori Mendi, Orr Katznelson, and Daniel Tony. A force to be reckoned with in the Online Publishing industry, Kueez was chosen by SimilarWeb as one of the 10 fastest-growing publishers in the US by 2020.
With more than 30 self-owned websites, Kueez offers a multitude of top-quality, engaging content to a global audience of over 100 million users per month and growing!
Life before Imply
Before Imply, they ran open-source Druid in GCP. But it got to the point where they couldn’t manage it properly. They lacked the domain skills, bandwidth, and resources to prevent the system from failing at scale. Because of these issues, they knew they had challenges.
“a managed service for Druid, the platform needed to be 100% available”
With those challenges in mind, Kueez’s CTO – found Imply via a warm recommendation from a current customer of ours. He knew Imply could help the team reach its goal to reduce operational overhead costs, plus offer support and tooling to manage it more robustly.
Imply allows Kueez’s data analysts, content editors, and growth teams to optimize their campaigns in real-time. With open-source Druid, they struggled to keep their system up and running, their queries were failing during traffic spikes and they couldn’t access the data they needed.
Technology requirements
When Kueez’s CTO (Elad Yosifon) and Chief Architect (Daniel Tony) began designing and architecting their real-time analytics platform, they briefly evaluated other databases, such as Redis, Athena, Cassandra, Clickhouse, and Snowflake to name a few. Still, they knew from recommendations that Druid would be the right choice. Customers have repeatedly shared with us that it is easier to partner with Imply than hiring a team of engineers to maintain open-source software.
“Kueez was looking for a better, scalable solution in managing and maintaining Druid”
Once it got to scale, they definitely had the knowledge but not the bandwidth. They tried everything to maintain and optimize their deployment independently but as we have already stated, this is a challenge for most open source Druid users.
Why Imply
It was an easy choice for Kueez to move from open-source Druid to Imply because of our team’s deep understanding of Druid and we are the creators and experts. Second, the pricing was cost-effective and it fit their use case need for real-time analytics. Lastly, we solved their pain of reducing open-source Druid operational overhead with Imply Cloud.
They started their journey with Imply through a discovery call where we uncovered their pain and learned about the performance issues they were hitting. As Kueez looked to scale their data platform, they needed a system that would make it easier for them to sleep at night. That’s why they chose Imply.
“Imply’s data platform is very reliable it’s never down and is our backbone for real-time analytics.”
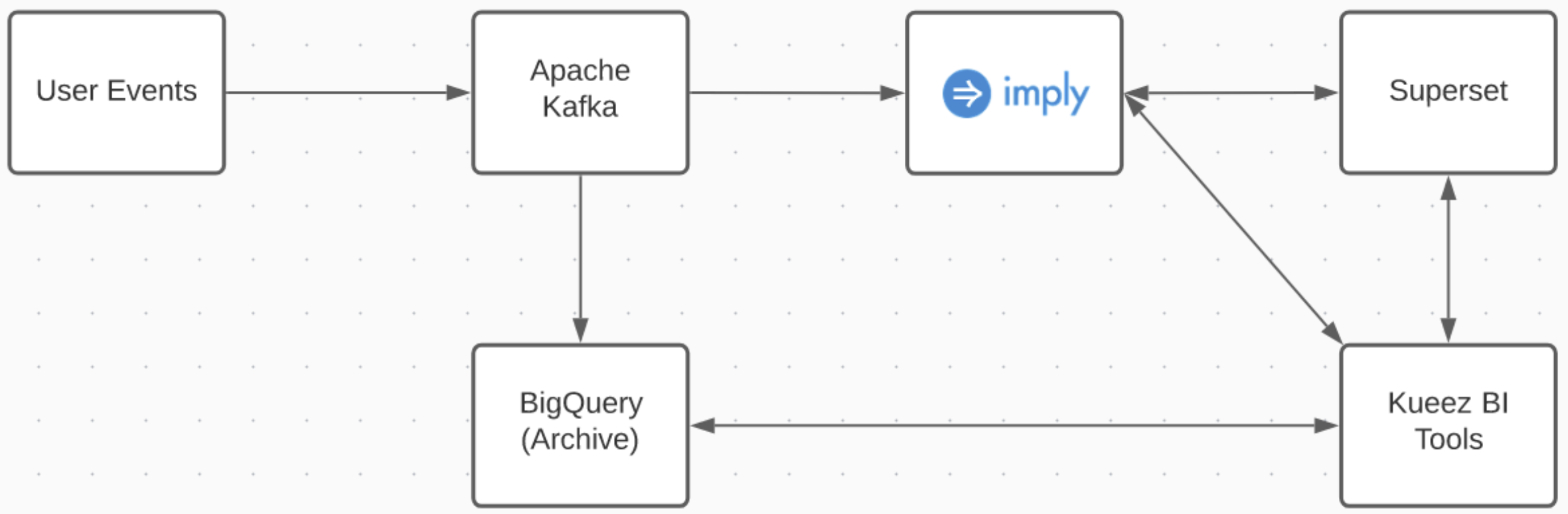
Inside their real-time analytics architecture, they have Imply alongside Superset as their go-to database, Google BigQuery as their archive data warehouse, and their own BI tools on top of it all.
Kueez’s analysts, content editors, designers, and operations teams rely on Imply to decide on campaigns and content in real-time. They use Imply to help them monitor and optimize campaign performance to ensure their customers and advertisers efficiently run their programs. Thus, allowing them to get the most eyeballs on their site, generating more clicks, impressions, and revenue for their advertisers.
Business Outcomes
8X reduction in operational overhead
Before Imply Cloud, they struggled with provisioning open-source Druid, which created many issues and downtime. By leveraging our managed service, Imply Cloud, they could free up valuable engineering resources to work on higher-value business problems and implement a system that can provide real-time monitoring, real-time analytics, and 100% availability.
12X performance improvement
Imply has been instrumental in Kueez’s ability to scale. It’s not uncommon for them to have over 100 million monthly users, terabytes of raw data, and over 5 billion unique data events ingested into their platform on a daily basis. According to Kueez, scaling their real-time analytics to support users’ volume has been made possible because their real-time analytics platform is built on Imply Cloud.
90% of team members are enabled with ad-hoc data exploration
At Kueez, data is at the center of all decisions. To empower decision-making, they needed a real-time self-service analytics tool that would allow their team to analyze campaigns and content independently. Since their adoption of Imply Cloud, 90% of their team are now enabled with real-time ad-hoc exploration, which is a massive improvement and something the team appreciates every day.
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...