In this post, I am going to talk a bit about Apache Druid and a recently documented configuration option that enables true NULL values to be stored and queried for better SQL compatibility: druid.generic.useDefaultValueForNull=false, and in the process do a deep dive into how it relates to a small sliver of the query processing system as we explore the performance of this feature.
Druid, SQL, and NULL
Druid first added built-in support for SQL in version 0.10, all the way back in 2016. From its meager beginnings as an adorable toy with a hopeful dream, it has gradually become a first-class way to query Druid, growing to the point where it has nearly complete feature parity with ‘native’ Druid JSON queries. It can even express some queries that are not possible with a single native JSON query. However, since its introduction, something started to stick out: a difference between the way Druid natively handles null values (or rather, didn’t) and the expectation of how null values should behave in SQL, which could create some often confusing query results.
Traditionally, Druid considered the empty string, '', and null values as equivalent for string columns. Numeric columns could never have null values, instead null values at ingestion time would be stored as a zero. There are historical reasons for this; originally Druid only had dimensions (which were always strings) and metrics which were always numbers (or complex sketch types). Metrics were never null because they were built at ingestion time, aggregating on each distinct dimension tuple within a time bucket. Eventually Druid introduced numeric column types, meaning that Druid could now have number columns that were not required to be built from aggregations, making the lack of a true null value become ever more painful.
NULL Handling
(Not so) secretly, an optional mode to allow actual null values to exist in Druid, striving to be more SQL compatible, was introduced in version 0.13, but was considered experimental and not documented outside of comments in the related issues and pull requests on Github. The initial series of patches (1, 2) addressed the aspects of modifying the segment storage format to be able to preserve null values encountered during ingestion, as well as overhauling the query engine to be able to expect and distinguish between null values.
For string columns, no actual segment format modifications were required, but it did require adding a special null value to the dictionary part of the column to allow treating empty strings and nulls as distinct values. Numeric columns however required modifications that were a bit more complex. The solution involved adding a null value bitmap to each numeric column with null values, where each null is a set bit. Druid already had the options of using CONCISE or Roaring bitmaps for the inverted indexes of string columns, so numeric columns follow suit and use the configured bitmap type for their null bitmap components during segment creation.
The query engine changes mainly consisted of changing column selectors and aggregators to acknowledge that null values exist by checking for and handling them appropriately. For numeric columns, this meant checking if the null bitmap has a value set for that row.
As our SQL support has matured, we decided that with version 0.17 it was finally time to acknowledge that this SQL compatible null value mode in fact exists, in the form of documenting it on the Druid website. But first, besides the obvious needs of spending some extra time to hunt down any remaining bugs by expanding tests coverage, we also needed to carefully consider the performance implications of enabling this mode.
Diving in
Query performance is our bread and butter; the ability to quickly slice and dice to perform interactive data exploration is a large part of what makes Druid a compelling platform in the face of incredibly large datasets. So, in deciding to announce this more SQL compatible mode, we needed to really investigate the performance implications of enabling it.
One of the biggest potential areas of concern was the numeric column isNull check that needs to be done per row. At the start of my investigation, this was being done using the bitmap get function, which provides random access row positions. The first course of action was to create a benchmark, NullHandlingBitmapGetVsIteratorBenchmark.java, and to run some experiments to see what to expect, as well as if I could make some modifications to make it better.
The nature of how column selectors are used internally by the query engines in Druid, where rows are processed from each segment in order (after filtering), lend themselves to potentially using a bitmap iterator as an alternative to calling bitmap.get for every null check. All bitmap implementations we use in Druid include support for an iterator, so, I first tested using get against using an iterator on columns with 500k rows, using various null bitmap densities and filter selectivities to simulate the overhead of checking for nulls while selecting values with each approach and bitmap type.
The performance difference between using get and iterator for CONCISE was absurdly in favor of using an iterator, being 5 orders of magnitude faster than using get when a column contained a large amount of nulls (benchmark results available here)! With this easy win out of the way, the remainder of the discussion and exploration focuses on Roaring.
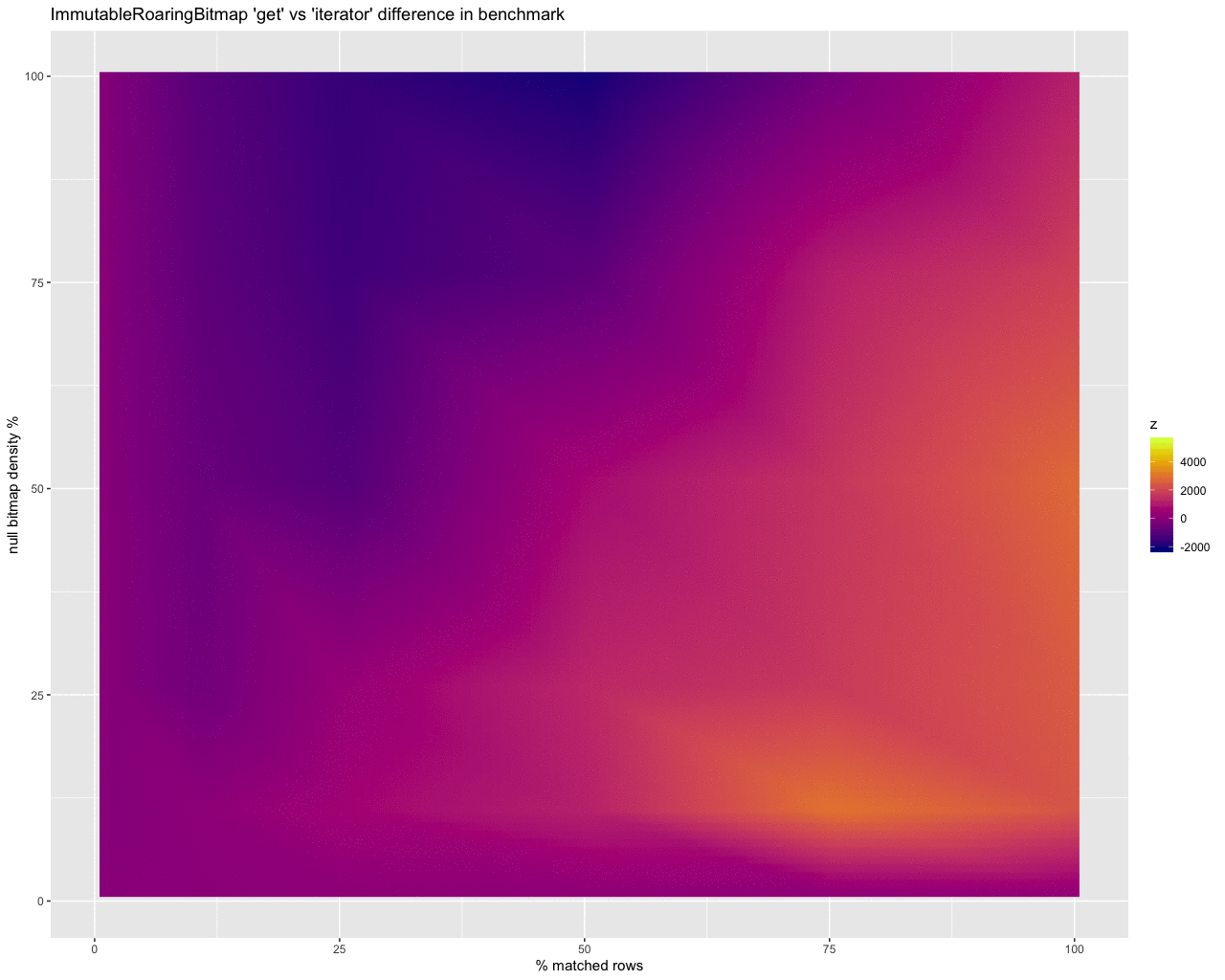
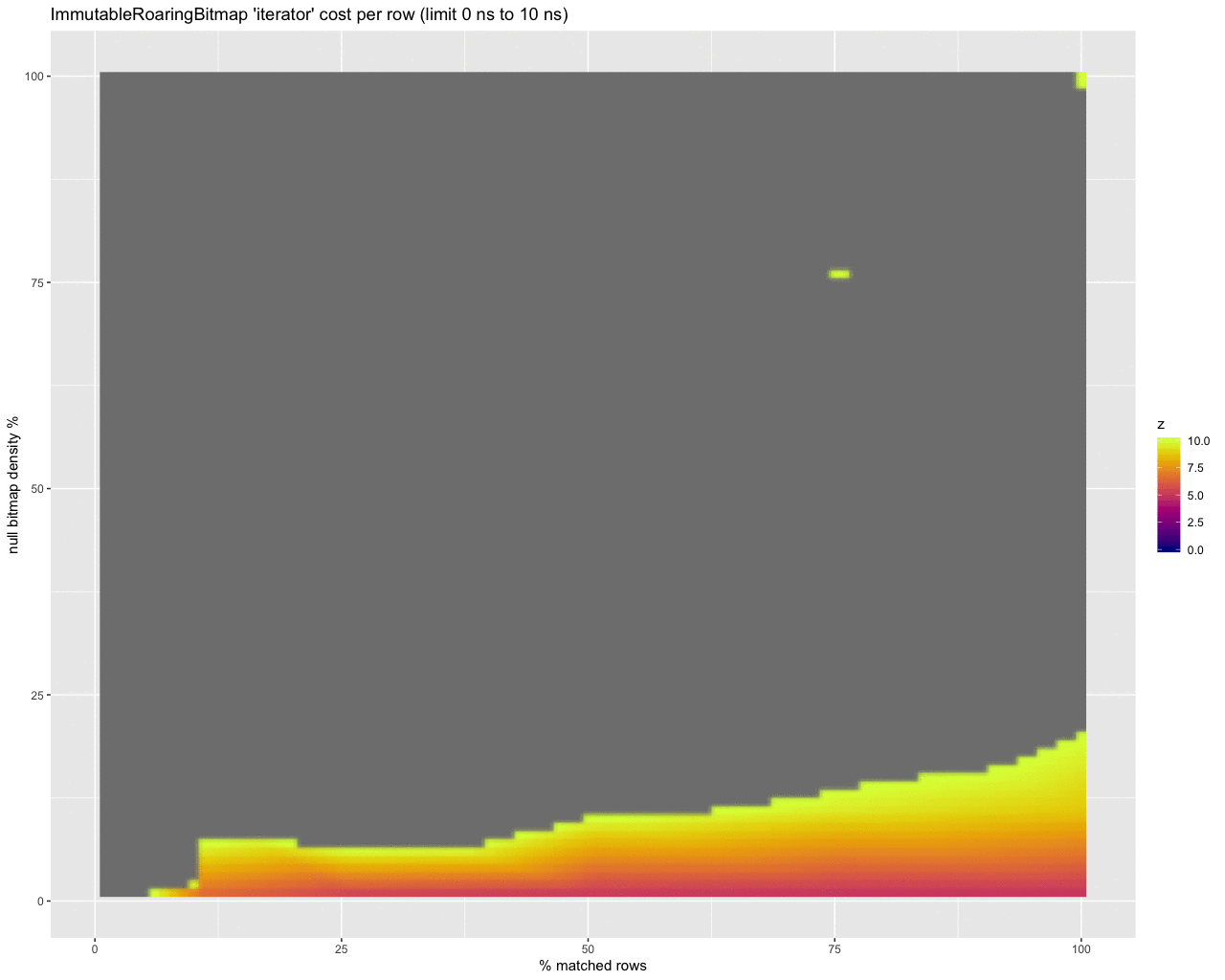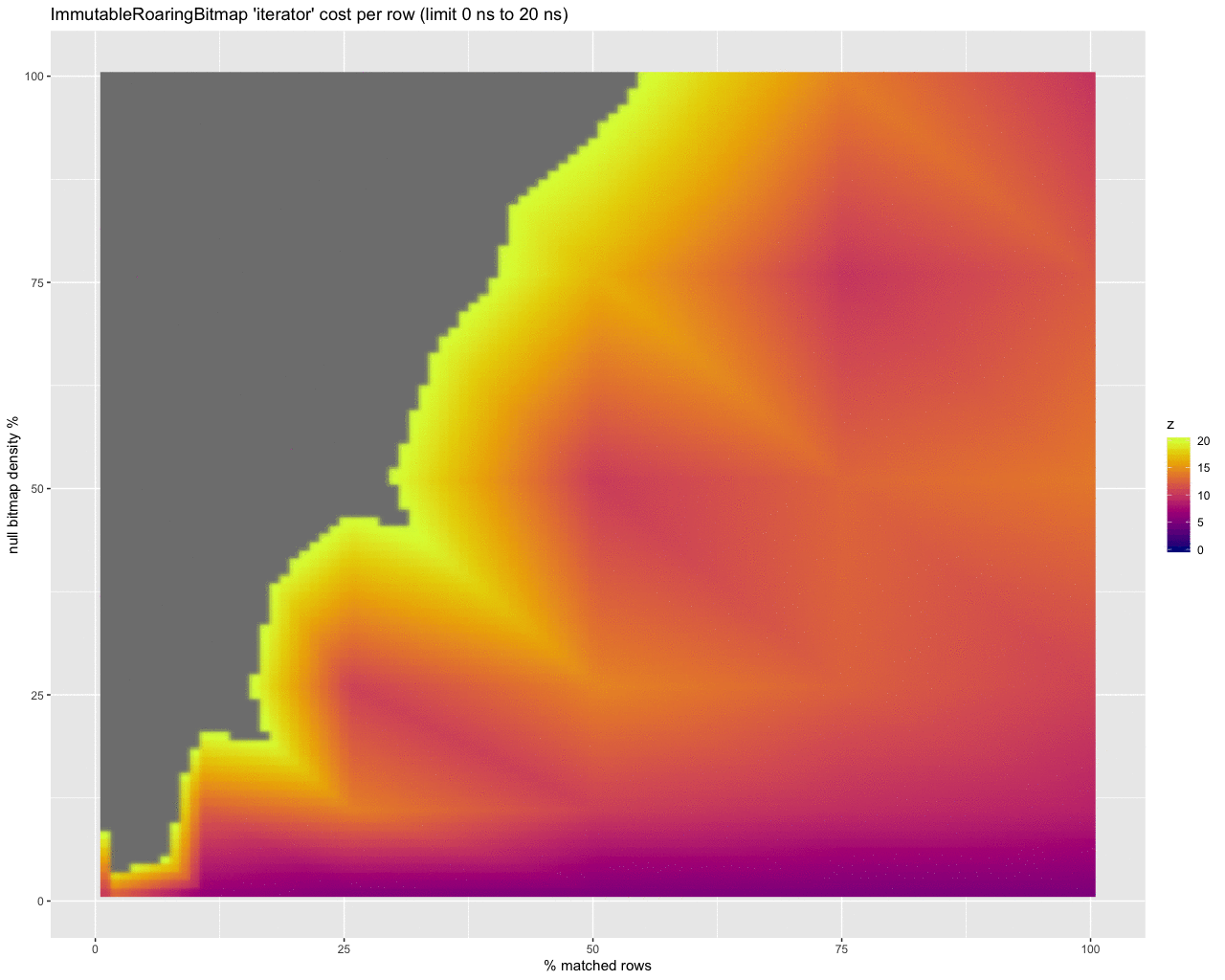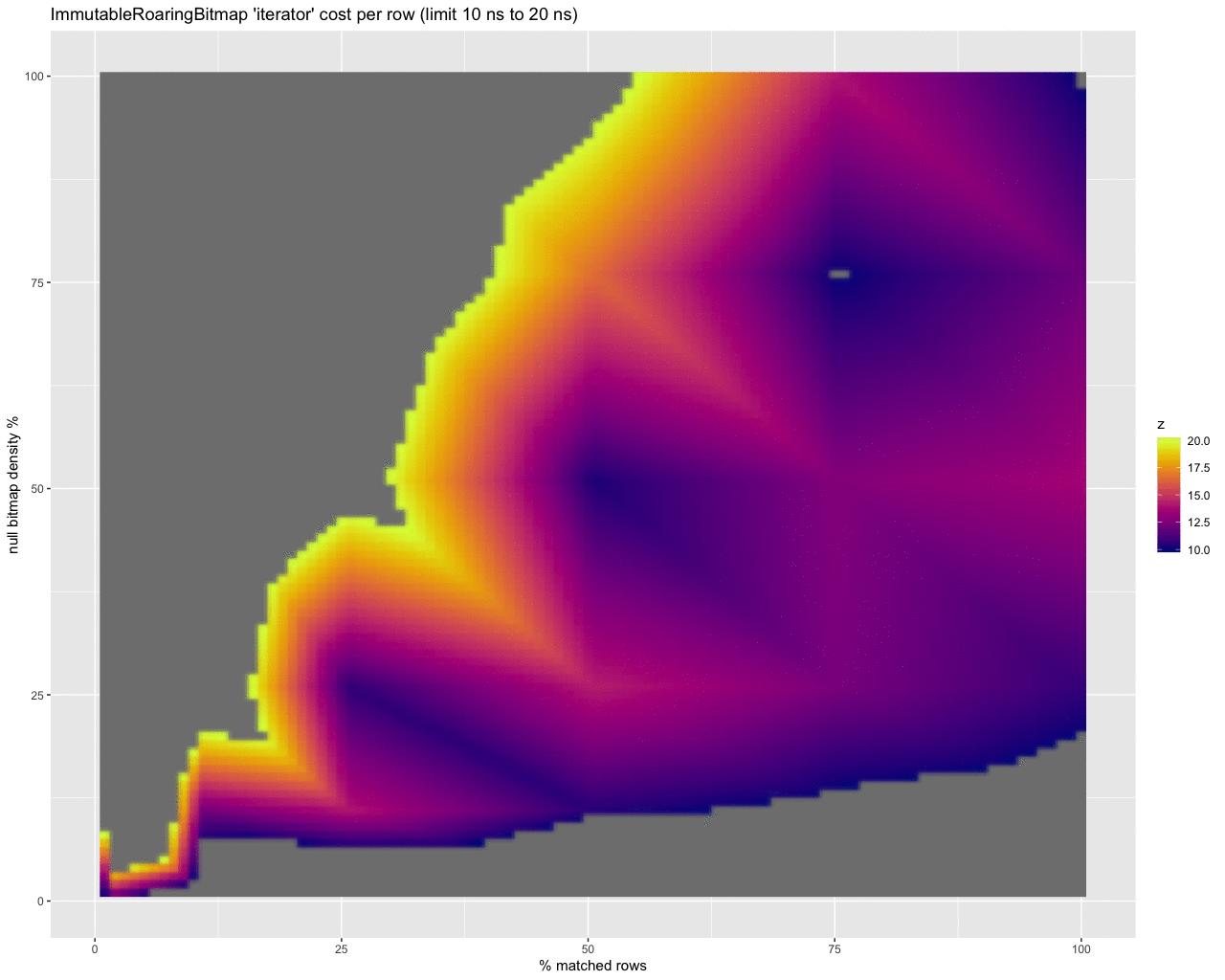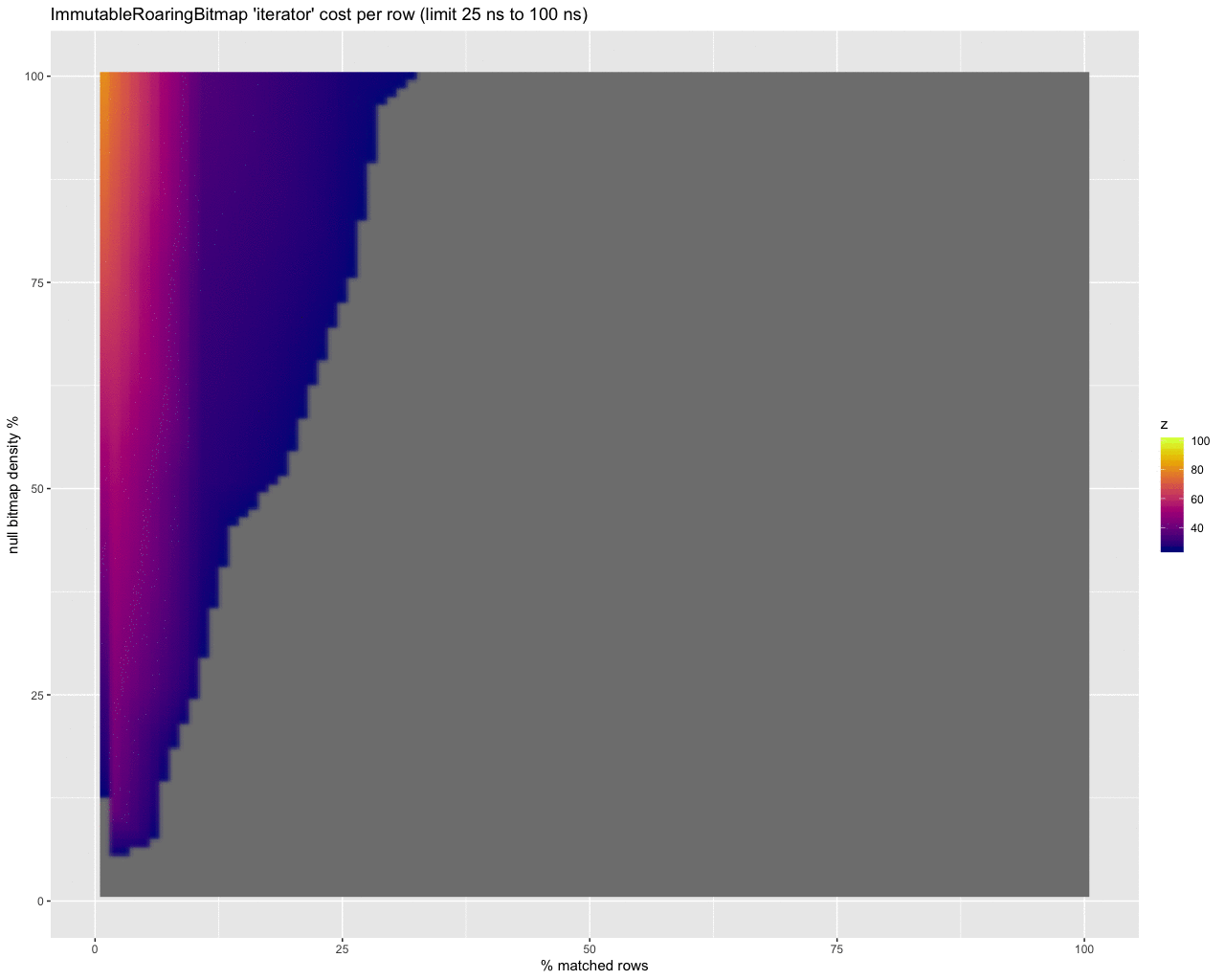
To help make sense of the numbers collected from this, I imported them into R and created some heat maps to compare the differences between the approaches. Here’s how it looks, straight out of the oven:
With this raw output, the results aren’t so helpful — the large gray areas are gaps between data points. Interpolating data to fill in those gaps yields something prettier, but still not incredibly telling on its own:
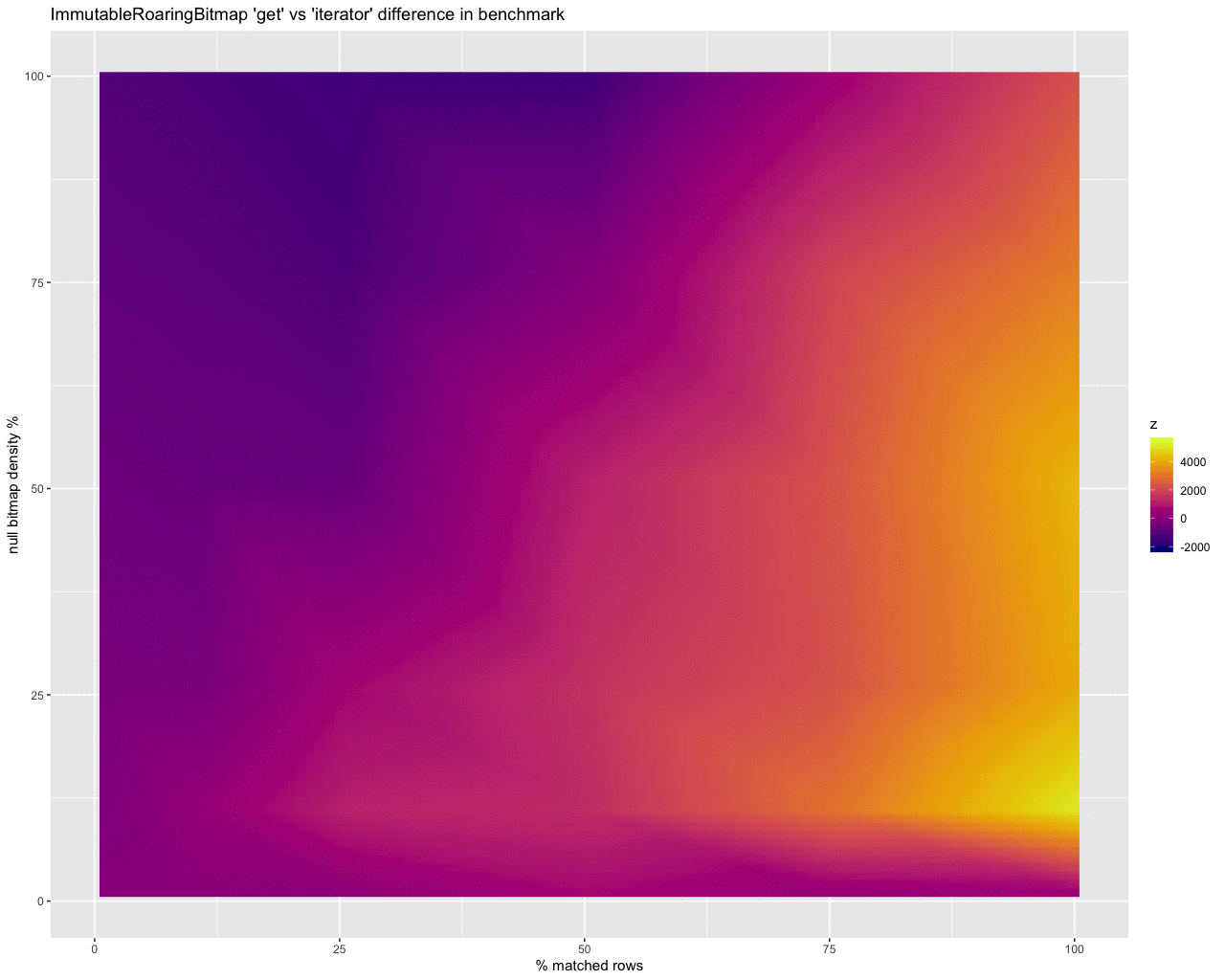
It does however start to show that the iterator is better at dealing with a larger number of rows, diminishing as the density of the bitmap increases.
Query mechanics
Let’s take a step back. The benchmark I mentioned earlier, NullHandlingBitmapGetVsIteratorBenchmark, is simulating approximately what happens during query processing on a historical for numerical null columns when used with something like a NullableNumericAggregator. NullableNumericAggregator is just a wrapper around another Aggregator to ignore null values or delegate aggregation to the wrapped aggregator for rows that have actual values, and can be used with all of the “simple” numeric aggregators like sum, min, and max.
As mentioned earlier, when default values are disabled, Druid stores numeric columns with two parts if nulls are present: the column itself and a bitmap that has a set bit for each null value.
At query time, filters are evaluated to compute something called an Offset. This is basically just a structure to point to the set of rows that are taking part in the query, and are used to create a column value/vector selector for those rows from the underlying column. Selectors have an isNull method that let the caller determine if a particular row is a null. For numeric columns, this is checking if that row position is set on the bitmap. So, mechanically, NullableNumericAggregator will check each row from the selector to see if it is null (through the underlying bitmap); if it is, ignore it, but if not, delegate to the underlying Aggregator to do whatever it does to compute the result.
The benchmark simplifies this concept into using a plain java BitSet to simulate the Offset, an ImmutableBitmap for the null value bitmap, and a for loop that iterates over the “rows” selected by the BitSet to emulate the behavior of the aggregator on the selector, checking for set bits in the ImmutableBitmap for each index like isNull would be doing.
Translating this into what you’re seeing in the heat map:
- the y axis is showing the effects of differences in density of the null bitmap (bottom is with just a few null values, the top is nearly all rows are null),
- the x axis is the differences in the number of rows that our selector will select (left side selects very few rows, right scans nearly all rows), and
- the z axis is the difference in benchmark operation time between using the bitmap
get method and using an iterator (or peekable iterator) from the bitmap to move along with the iterator on the selectivity bitset.
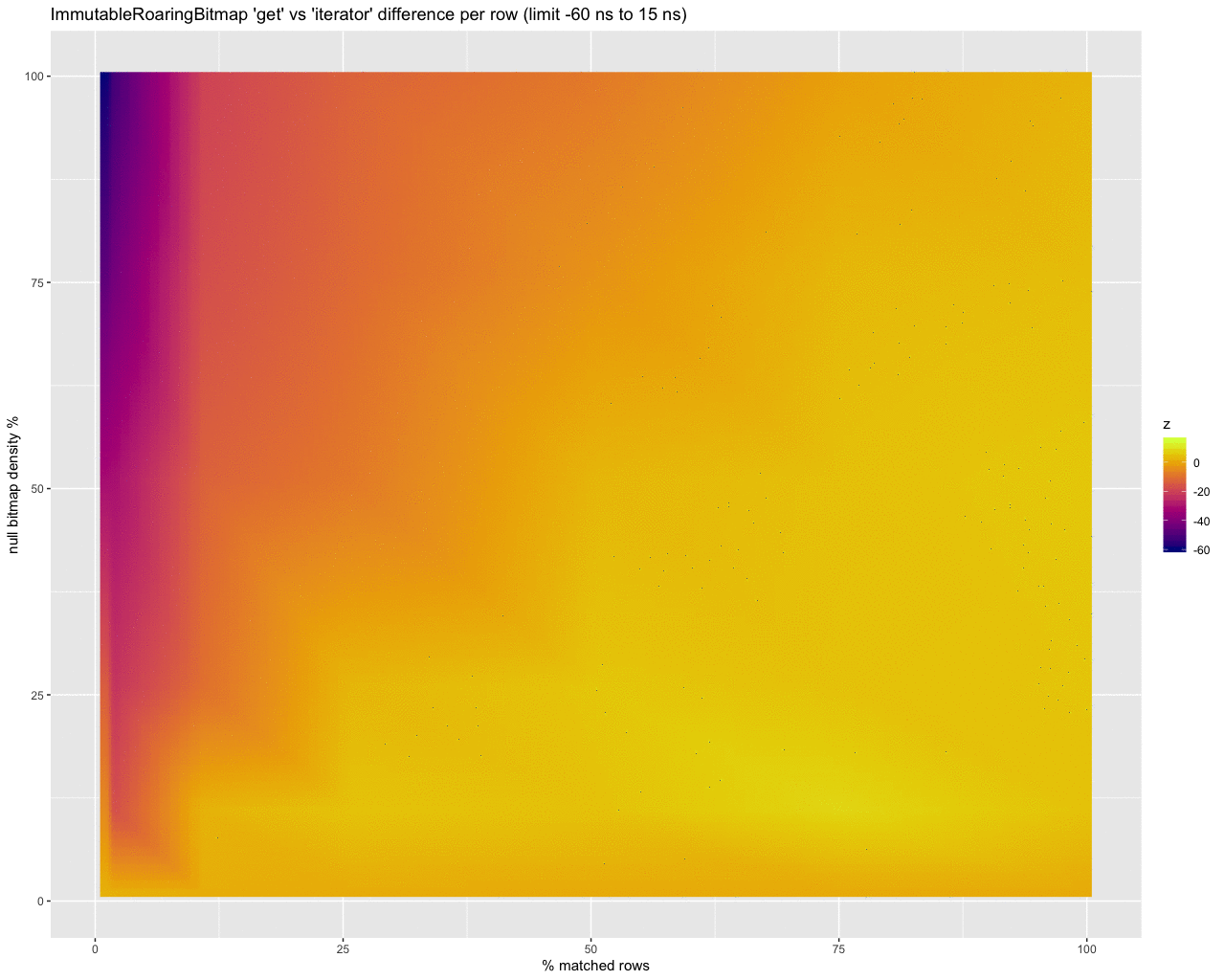
Further, some of the heat maps have translated the raw benchmark times into the time per row by scaling the time by how many rows are selected, to standardize measurement across the x axis, making it easier to compare the two strategies.
Good, but can we do better?
While this is a start, scaling the data points to estimate the cost per row in nanoseconds provides a much more useful picture. It shows the abysmal performance of using the iterator at super high selectivity (e.g., 0.1% of rows match and are selected) with really dense bitmaps:
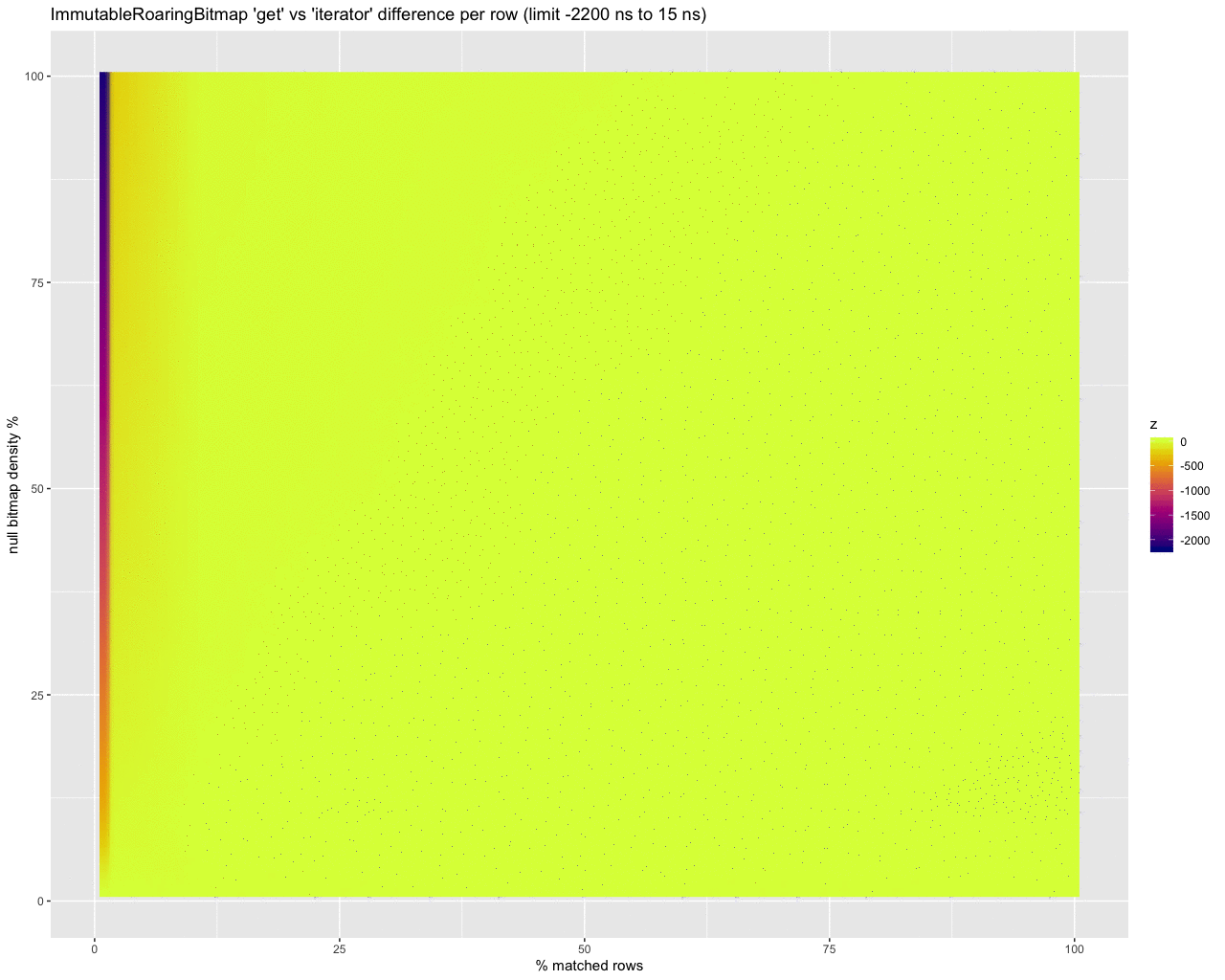
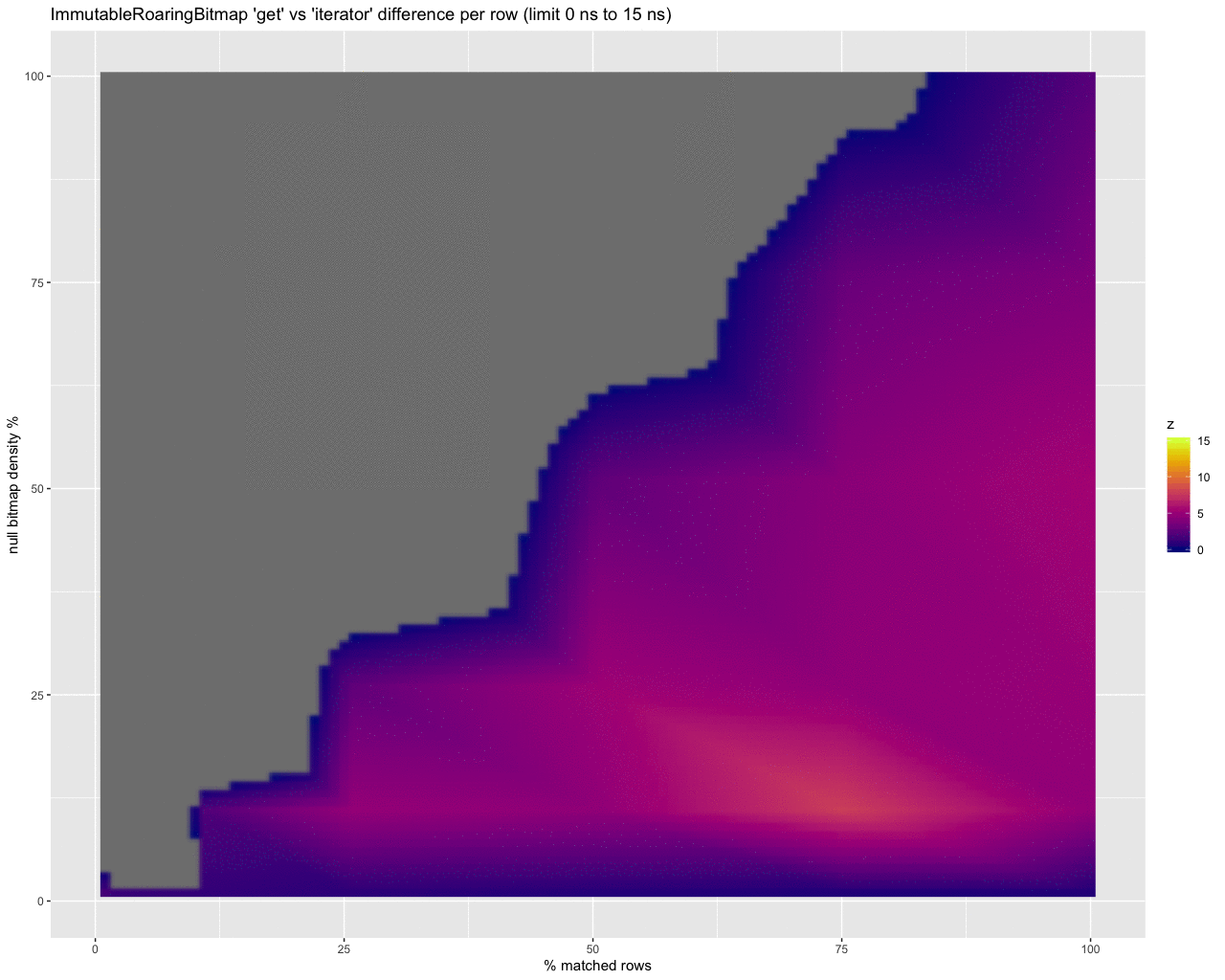
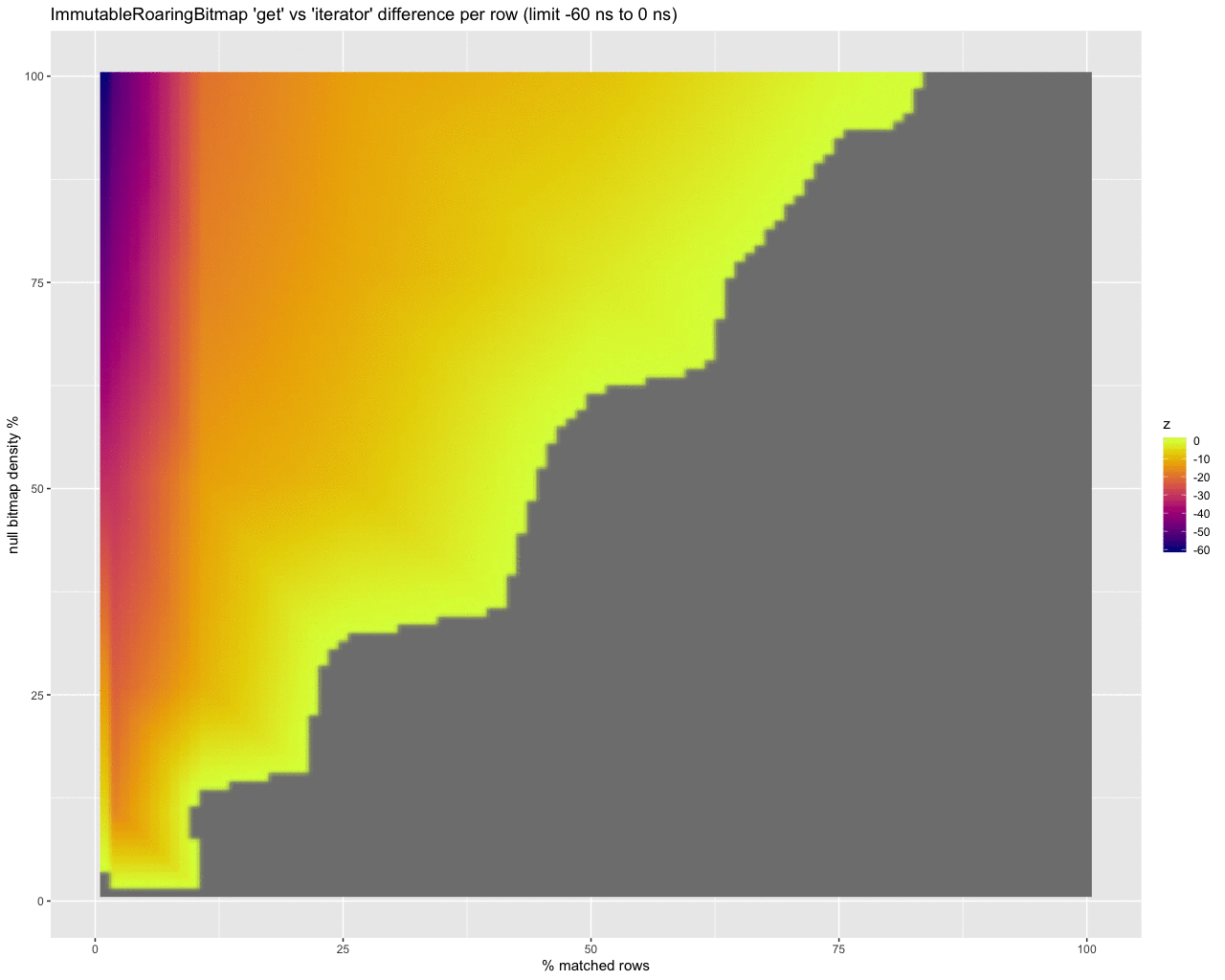
However if we truncate the results we can compare areas where the iterator is better (on the left) to where get is better (on the right):
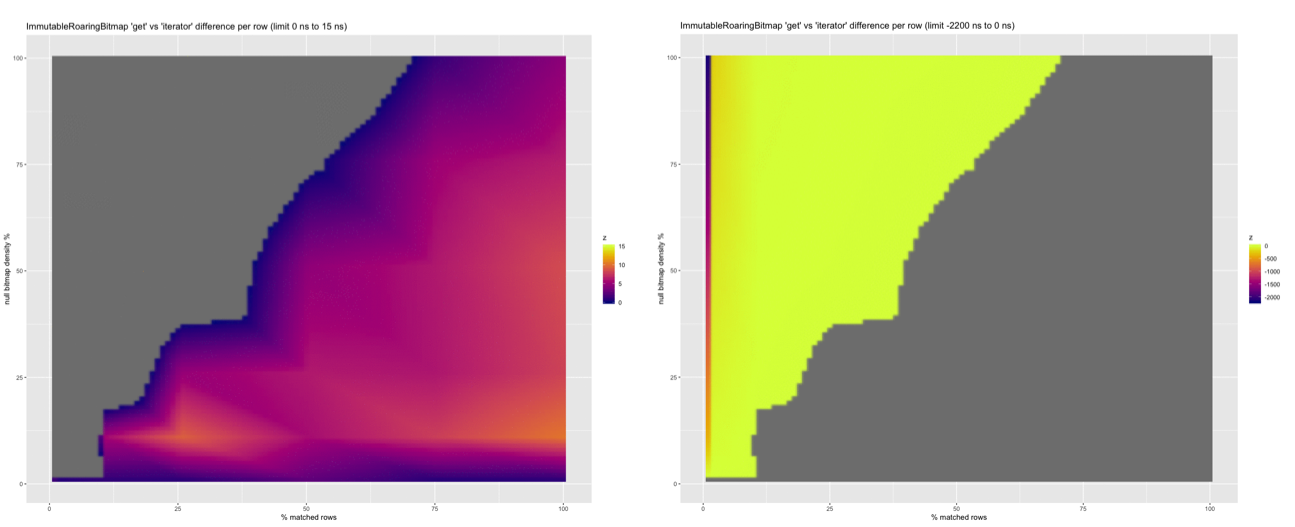
…it does look like the iterator performs up to 15 ns per row better than using get when processing a lot of rows.
Searching for a way around the limitation, I was unaware that the IntIterator for roaring was actually a PeekableIntIterator which is an iterator that offers an advanceIfNeeded method that allows skipping the iterator ahead to an index. ConciseSet actually has a similar method on its iterator, skipAllBefore, which is used by the contains method that the get of concise uses!
This is why concise performed so terribly in the benchmarks when processing a higher number of rows, because every get is creating an iterator, skipping to the position, loop checking to see if the iterator contains the index or passes it, and then throwing it away!
Adding the peekable iterator to the benchmark had a similar outcome to using the plain iterator:
…but without nearly the overhead at high selectivity on dense bitmaps.
It’s still worse, but not nearly as bad: no more than 60ns slower per row when processing a small number of rows than get, compared to over 2 microseconds for using the plain iterator.
peekable iterator better than get:
get better than peekable iterator:
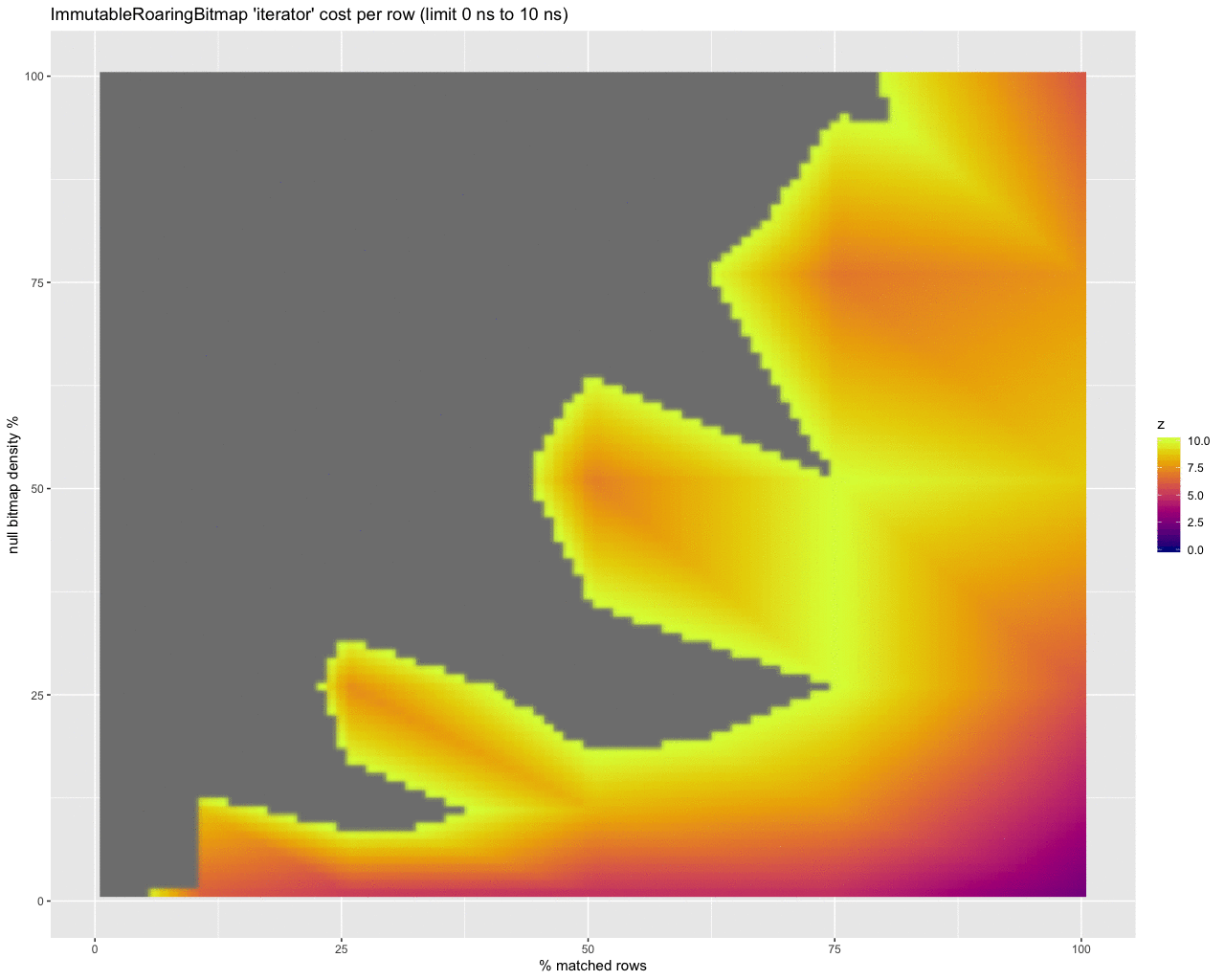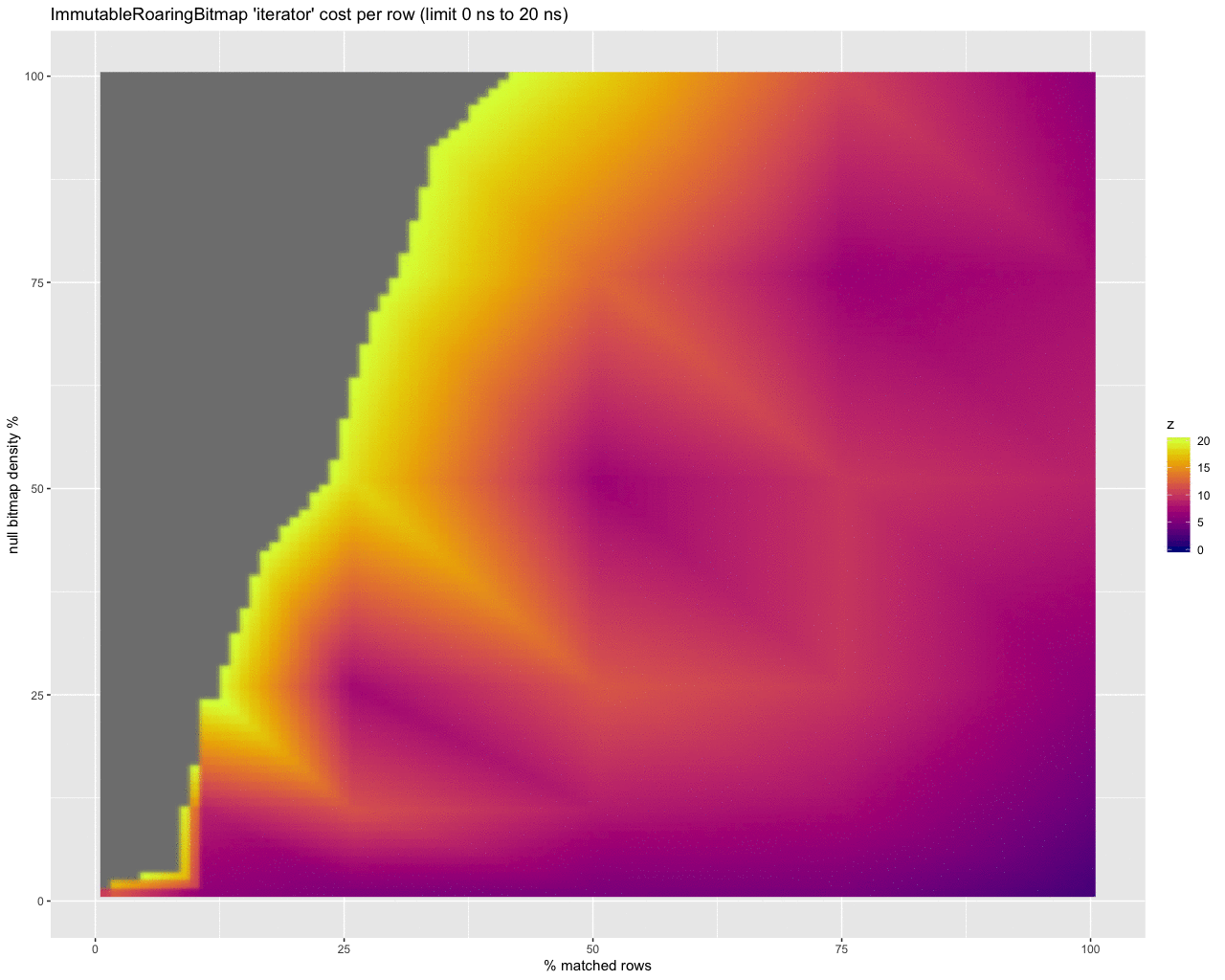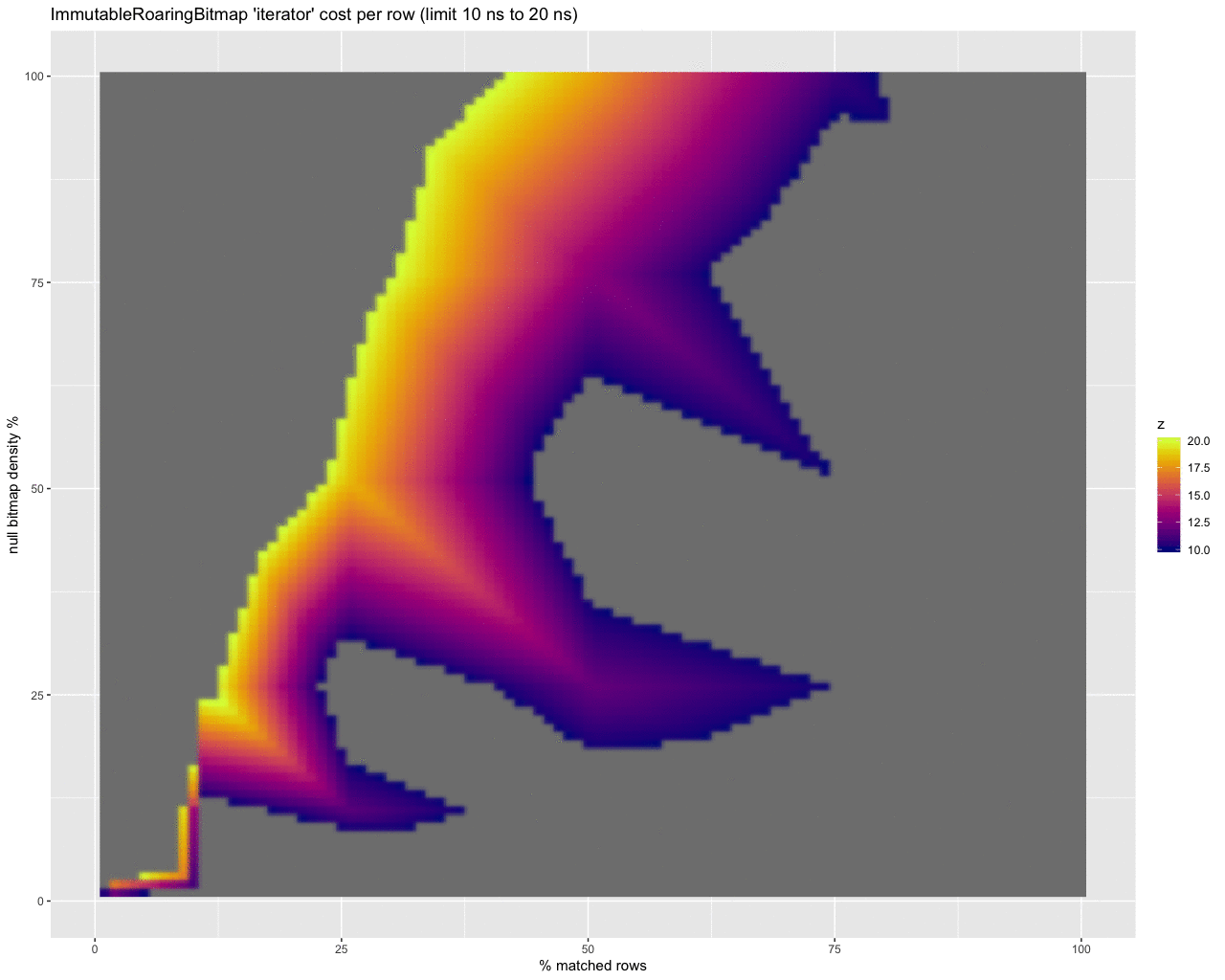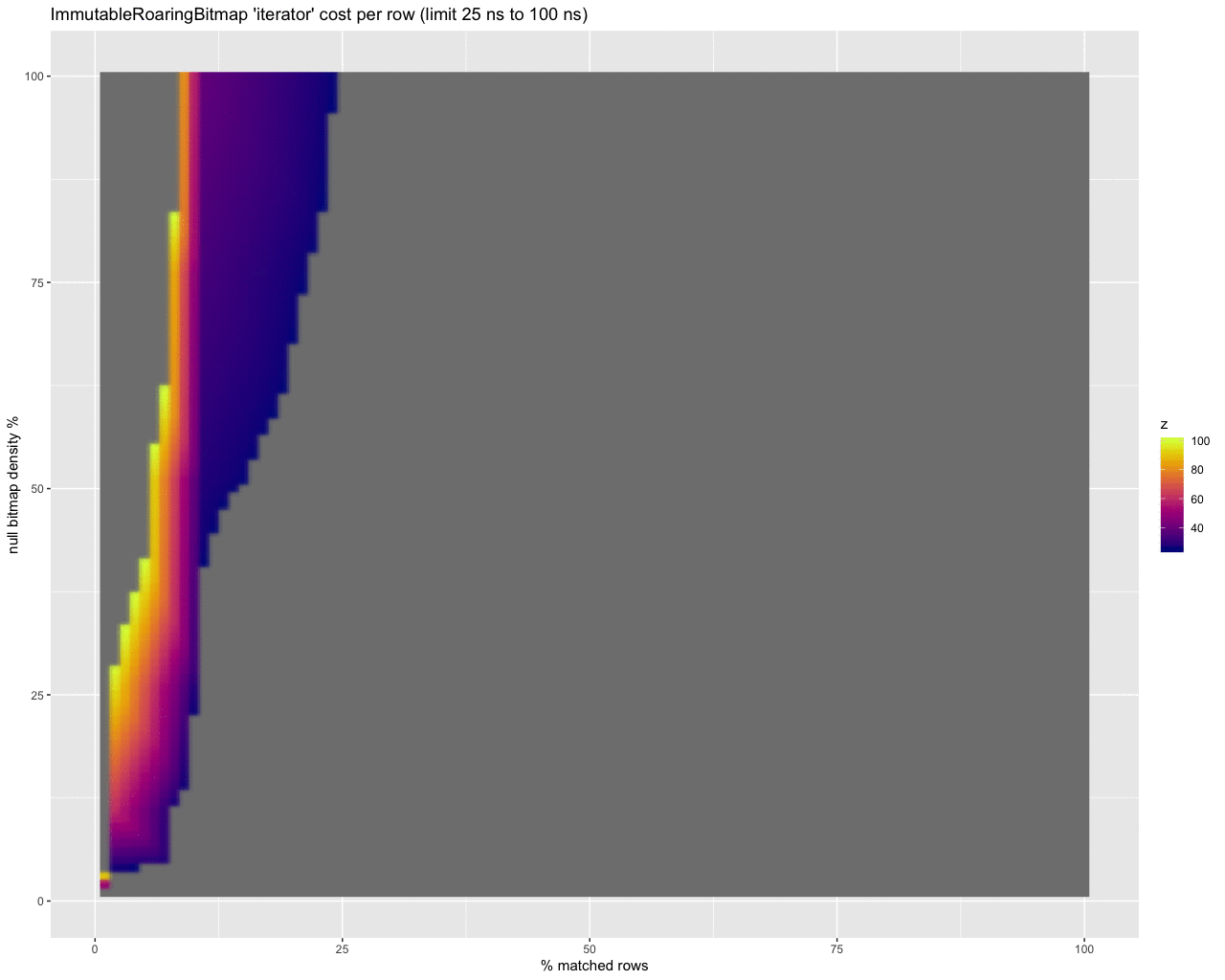
Finally, to get a handle on the per row cost in nanoseconds of checking for nulls at all, I threw together these animations:
get:
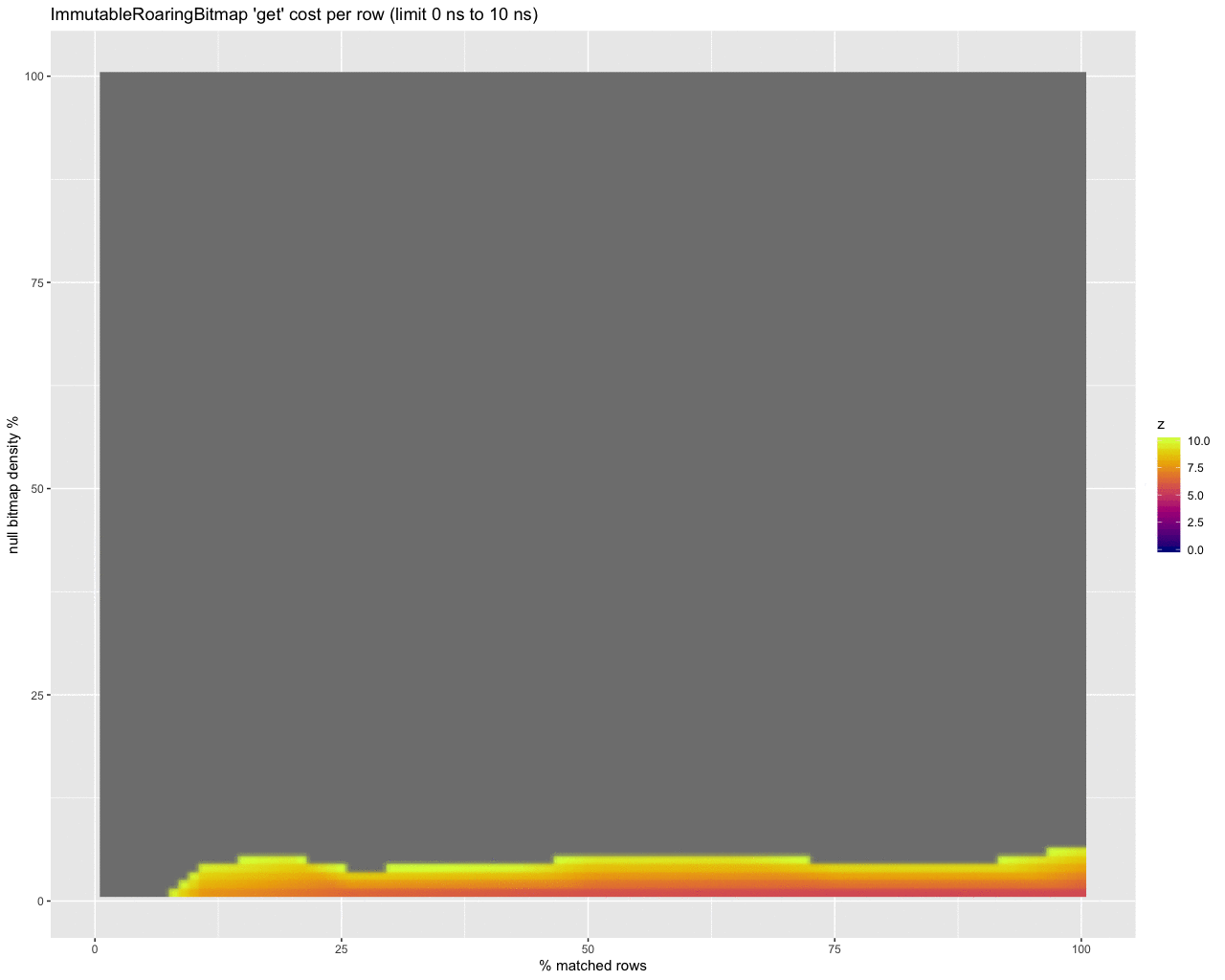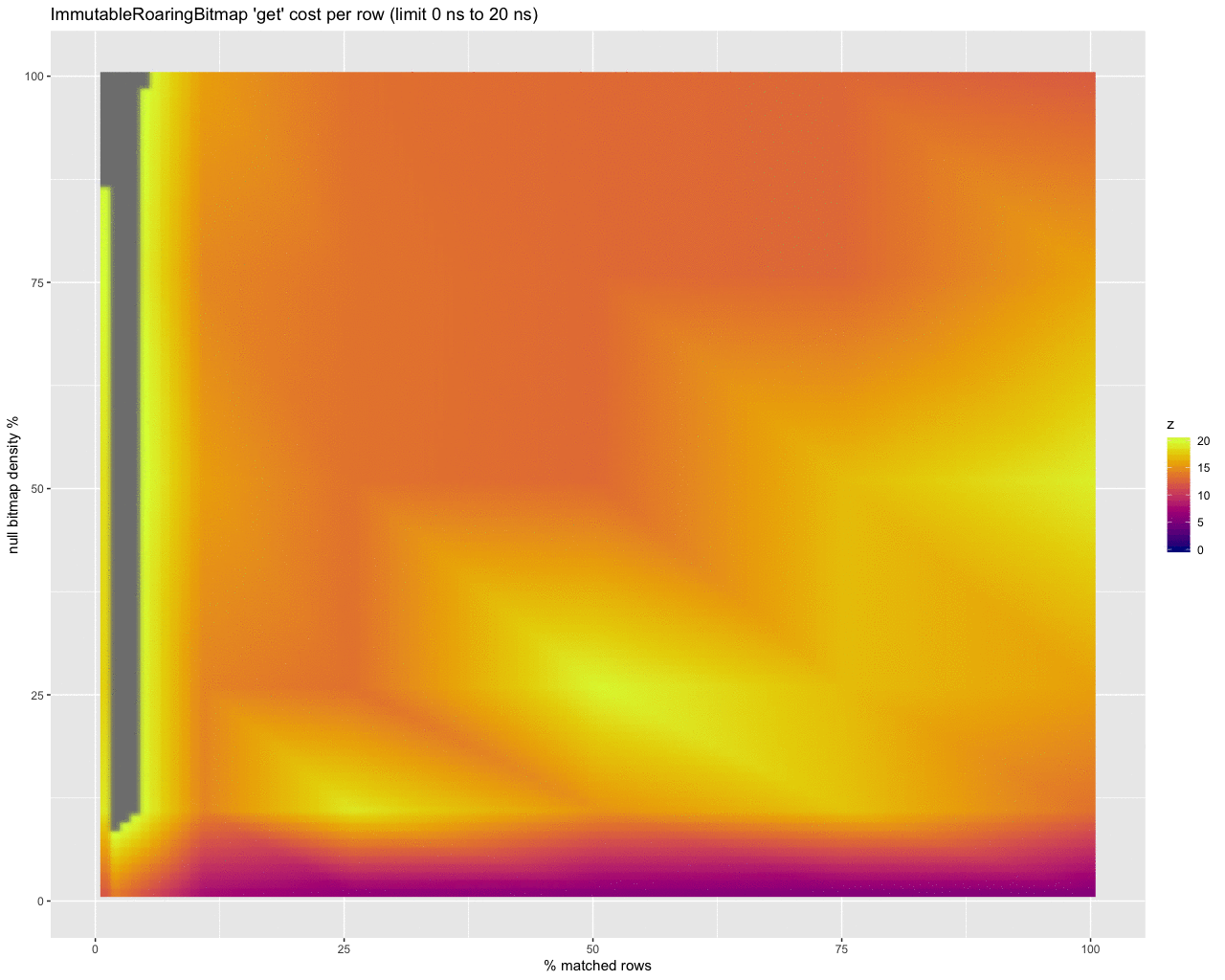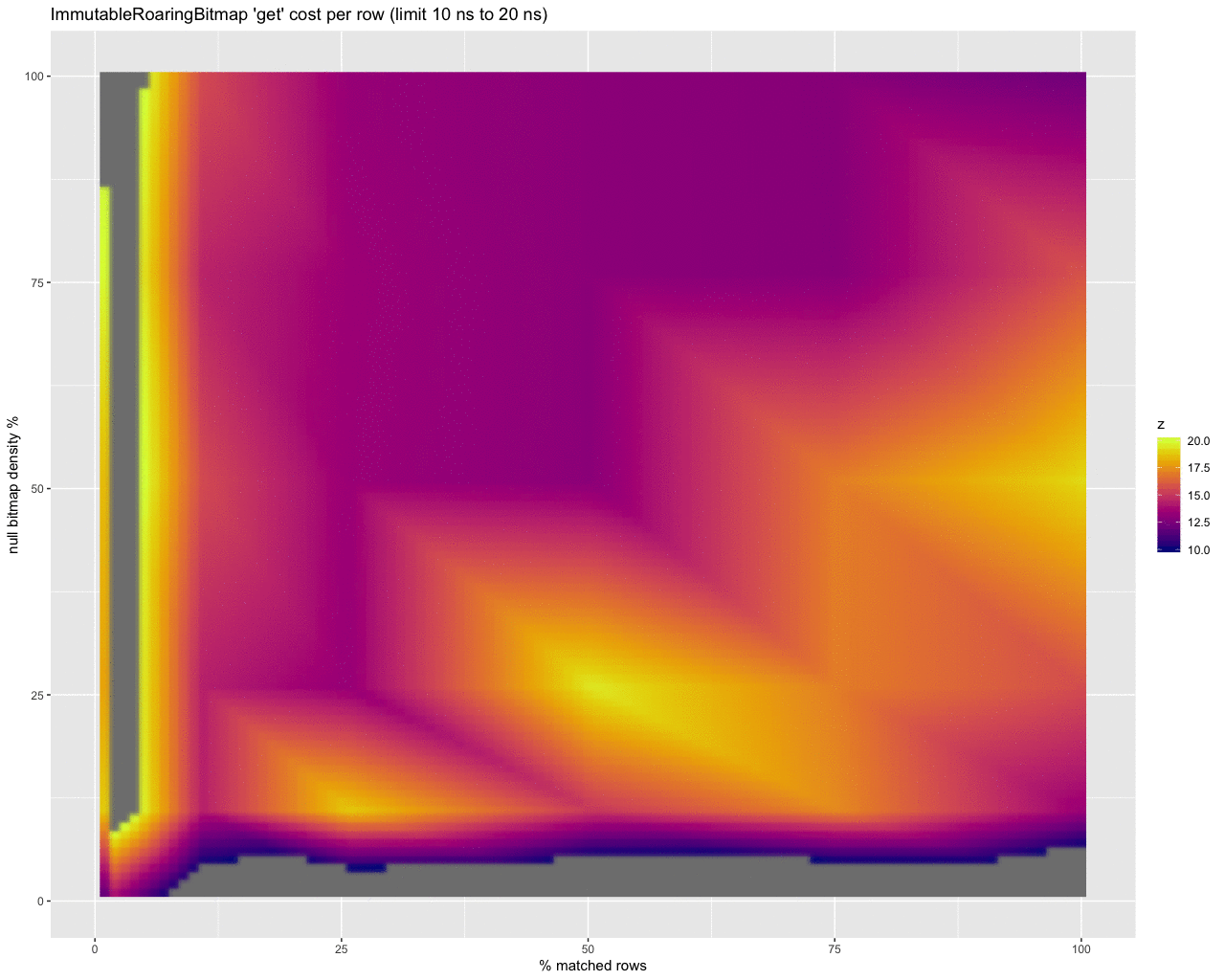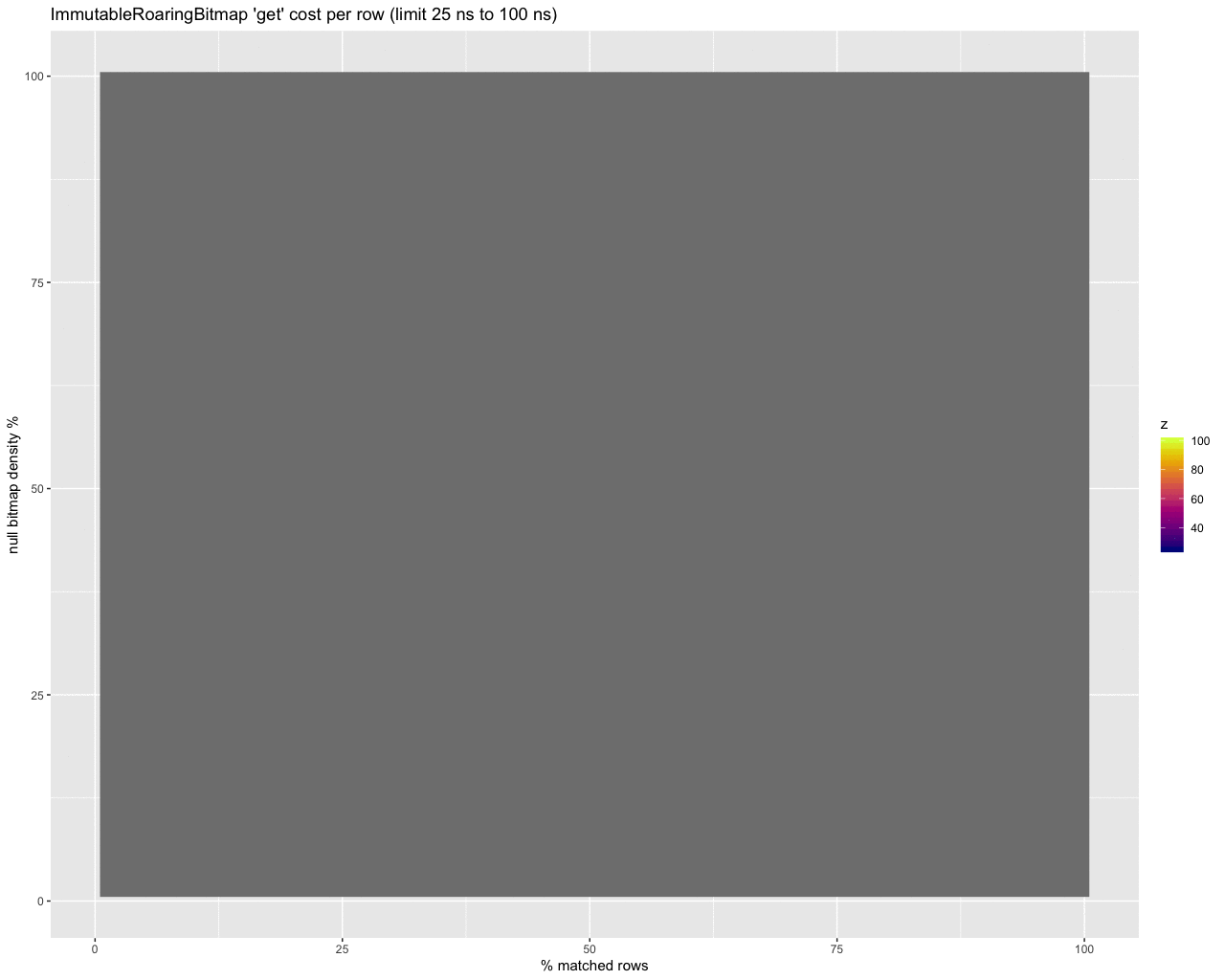
iterator:
peekable iterator:
The last three animations show the estimated per row cost in nanoseconds for each strategy. I will summarize:
get
- Most of the numbers look to be in the 10-25ns per row range (higher at low selectivity where it matters most).
IntIterator
- About half are under 10ns per row (at low selectivity). This is definitely the best, but at super high selectivities (.1% of rows selected) with very dense bitmaps it climbs to over a couple of microseconds per row.
PeekableIntIterator
- About half are between 10-15ns per row (at low selectivity), most below 25ns, but also has more overhead with dense bitmaps at very high selectivity but only climbs to about 50-60ns per row in the worst case.
Based on these results, we swapped the isNull check to use PeekableIntIterator to optimize the case where the selector is going to be processing a larger number of rows. PeekableIntIterator was chosen over IntIterator because it offers nearly the same performance increase at low selectivity, without nearly as severe of a performance loss for high selectivity.